开源日报 每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,坚持阅读《开源日报》,保持每日学习的好习惯。
今日推荐开源项目:《JS 改 typescript-tutorial》
今日推荐英文原文:《Top Open Source Tools for Artificial Intelligence and Machine Learning》
今日推荐开源项目:《JS 改 typescript-tutorial》传送门:GitHub链接
推荐理由:学习过 JavaScript 的朋友相信都应该在某处看到过这个和 JS 看起来很像的 TypeScript,实际上 TS 是 JS 的一个超集,你可以把你的 .js 文件直接改成 .ts 文件来使用,比起 JS 来说 TS 的代码可读性和可维护性更好些,不过学习 TS 需要学习一些概念的同时在短期内定义各种类型会增加你的工作量——尽管从长远来看总工作量会减少,根据项目的实际情况来选择 TS 或者 JS 吧。
今日推荐英文原文:《Top Open Source Tools for Artificial Intelligence and Machine Learning》作者: Swapneel Mehta
原文链接:https://opensourceforu.com/2019/03/top-open-source-tools-for-artificial-intelligence-and-machine-learning/
推荐理由:在 AI 和机器学习方面用得上的开源工具
Top Open Source Tools for Artificial Intelligence and Machine Learning
‘Data is more valuable than gold’. This is the mantra of modern computing. Enormous amounts of data are being generated every minute throughout the world. The entry of AI and ML has facilitated the processing of this data and its use in the enterprise as well as in various other fields. Here is a bird’s eye view of trending open source tools for AI and ML.
2018 can well be remembered as the year where data first demonstrated its dominance, with a visible impact not only on science and technology but also on global politics and socioeconomic conflict, especially in developing nations. While we witnessed the trouble it can foment, we were made painfully aware of the terrible costs incurred if these tools are used unethically. On the whole, this article seeks to adopt an objective view as we look at how artificial intelligence (AI) is maturing, backed by large scale research efforts across the world from Silicon Valley in the West to China in the East.
Top machine learning (ML) frameworks
The stalwart across the field remains Google’s TensorFlow that provides an enterprise-grade system to train, test and deploy deep neural networks at scale. It has steadily grown and is supported by an ecosystem of visualisation, data manipulation and interpretability tools that make it a ubiquitous solution when it comes to scalable machine learning. With the added support of Keras integration, Google is now trying to shorten the learning period for developers to work with TensorFlow.
Last year we saw the emergence of PyTorch as one of the frameworks preferred by machine learning researchers who often chose not to use the dominant TensorFlow, given the flexibility and features in the younger, lightweight, open source, deep learning library supported by and extensively used by Facebook. Most comparisons of state-of-art frameworks are focused on TensorFlow and PyTorch, arguably given their strong adoption rate in academia and industry, shadowing the others like Caffe, Theano and Microsoft’s Cognitive Toolkit (CNTK). Following these, there’s also the Apache MXnet project with the Gluon interface, which seeks to provide simple and quick building blocks that allow users to speedily prototype deep learning models.
Scikit-learn remains a widely used open source framework to prototype and deploy classifiers for machine learning, but is more focused on providing a ‘workbench’ in order to avoid the boilerplate code that presents a challenge for picking up frameworks like TensorFlow and PyTorch.
We do have Spark MLib and CNTK in use across enterprises. Netron, a popular visualisation library for neural networks, now also supports CNTK while Spark MLib is seeing steady adoption as companies start out with building scalable data streaming pipelines. In combination with Mahout and Apache’s other products for Big Data management and architecture, Apache has released SystemML as an addition to its repertoire of open source tools at the intersection of Big Data and machine learning.
Libraries such as Fast.ai’s recently released software have advanced the state-of-the-art in some disciplines within natural language processing. Edward has been released as a probabilistic programming toolkit built atop TensorFlow (soon to be integrated within it), while Lime is another library supporting greater interpretability for deep neural networks. All these are seeing increased use as issues of privacy, ethics, and understanding of biases in data acquire greater importance within the industry. Many traditional applications also rely on machine learning capabilities in Java and R via frameworks such as deeplearning4j. Overall, the AI and ML space is bustling with developments that one needs to follow, and change seems to be the only constant.
Top tools for artificial intelligence in the cloud
‘Artificial Intelligence-as-a-Service’ is trending, especially because small-scale companies do not wish to do the heavy lifting of setting up end-to-end data pipelines, but would prefer to focus on each stage of the preprocessing, training and deployment processes. For instance, Amazon and Google’s cloud platforms offer a set of endpoints to address machine learning on streaming data. In fact, their recent offerings like Google Cloud AutoML and the Amazon Web Services SageMaker focus on transferring control into the user’s hands by introducing more interpretability; but they still have some distance to travel when considering the level of automation and performance across heterogenous data sets.
Following Rekognition in 2017, Amazon has ramped up focus on natural language processing, automatic speech recognition, text-to-speech services, and neural machine translation technologies as managed services in the cloud. The company introduced video and image analysis using DeepLens, making it easier for developers to access these as desired.
Top Web frameworks for machine learning
Web frameworks have been all the rage in machine learning as neural networks have reduced in size and gained sufficient accuracy when compared to human standards. One of the forerunners in this space is Andrej Karpathy’s ConvNet.js. This inspired similar work or parallel lines of thought that later resulted in libraries based in JavaScript, which can be run as part of server-side or client-side scripts. The recent release of TensorFlow.js is a solid step forward in this direction, extending the ecosystem for developers seeking to bring the machine learning experience to the browser. There are other frameworks, including ml5js, focused on offering a complete set of in-browser machine learning capabilities.
Top ML tools for mobile app developers
‘Data is more valuable than gold these days’. All mobile app developers want to integrate advanced analytics including machine learning systems into data processing, to enable them to generate more accurate insights and make decisions based on the ‘big picture’ of the user statistics within their apps. It becomes a very lucrative market to capture as app developers seek custom solutions for their use cases, which focus on an unchanged user experience in spite of a huge amount of processing in the backend.
Google is capitalising on its expertise in developing and supporting TensorFlow by releasing ML Kit which caters to the Android market, often with specific requirements of low-memory impact and low-resource learning, on the fly. This comprises specific libraries that address text and face recognition, bar code scanning, image labelling and face detection, and will soon see a foray into natural language processing, with support for the smart reply feature seen in its other products including Gmail.
Apple, meanwhile, is playing catch-up with its CoreML library. The advantage of the competition within this space has been the release of a huge repository of lightweight models optimised for mobile devices that permit the end user to continue to have a streamlined experience on handheld devices.
Overall, the machine learning landscape is growing increasingly crowded with new frameworks emerging and older ones fading; but a huge amount of work is focused on working in conjunction and promoting a much healthier environment for developers and researchers. This bodes well for the end users as we note the emergence of mature, capable and interpretable open source machine learning tools for use cases spanning the tech landscape and beyond.
下载开源日报APP:https://opensourcedaily.org/2579/
加入我们:https://opensourcedaily.org/about/join/
关注我们:https://opensourcedaily.org/about/love/
One of the games that I occasionally play to relax is Minesweeper.
I have extensive experience with JavaScript front-end technologies starting from jQuery and nowadays Angular. Being open to new technologies I have tried React in few hello world projects. Implementing Minesweeper in TypeScript and React seemed like an interesting challenge and opportunity to learn more.
In this post I will try to explain how I did it and maybe encourage or learn you how to implement your clone of this or maybe some other game.
If you’re just interested in seeing the final solution visit or clone the GitHub repository or if you just want to play it click here.
Before we start
You will need to have installed (or install) on your machine:
We will bootstrap the React project with using the option --script-version=react-script-ts that would instruct create-react-app to use Create React App (with TypeScript) configuration.
In my previous experience with Angular I find TypeScript a real joy to work. And having daily experience with statically typed languages (Java, Kotlin) I was not interested in using pure ES6. On the other side, learning and investing time in Flow was not worth it having a previous (great) experience with TypeScript. Read this great article to find out more about using TypeScript + React.
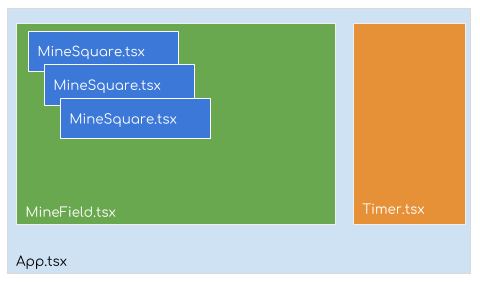
One of the important steps in implementing any React application is how to brake down the UI in components and how to compose them. On the following image is the structure of the React components that we will need to implement for Minesweeper.
React components structure
The final design was to brake down the game in three separate components:
MineSquare – will host a single square that is a possible mine, number indicating of neighbour bombs or just empty square if no bombs around
MineField – will host the game container as a grid (rows x columns) of mines
Timer – will be an external component that will show the elapsed time since the game started.
Next create a directory components in your src directory and create a separate file for each of the listed components.
This is how an empty component should look like:
import * as React from "react";
export const MineField = (props: PropType) => (
<div className="game-board">
{'MineField'}
</div>
);
In React you can create components as class that extends the React.Componentclass or as functions (possibly arrow) for functional (stateless) components.
Minesweeper game domain
The game domain are the classes and data structures used to represent the state of the game.
export interface Point {
x: number;
y: number;
}
/**
* bombs = -1 - it is a bomb
* bombs >= 0 - count of bombs around
*/
export class Mine {
constructor(public position: Point,
public isOpened = false,
public bombs = 0,
public isFlagged = false,
) {
}
}
export class Game {
constructor(public state: Array<Array<Mine>>,
public totalBombs = 0,
public exploded = false
) {
}
}
The game Minesweeper is represented as two-dimensional array (matrix) of mines Array<Array<Mine>> or Mine[][]. Each Mine has:
position (x,y coordinates) in the matrix of mines
isOpened a boolean field which is true when a mine field is opened
bombs a number which encodes if there is a bomb (-1) or positive number representing the count of bombs around that mine.
isFlagged which represents if the mine is marked (flagged) by the user as potential bomb.
It was really hard to get the naming right for the game domain, having to deal with mines/bombs, mine field as single field with mine or field of mines :).
The Game class represents the state of the Minesweeper game which is the two dimensional array of mines. Also it contains auxiliary fields for the count of total bombs and state if there is exploded bomb (game is finished).
MineSquare component
The MineSquare is a functional (stateless) component. That means that it should render the property field: Mine and just propagate an event when interaction happens. It can not keep or mutate any state.
The Mine will be rendered as HTML button element since the click is the natural interaction for this HTML element. Depending on the state of the field: Mine we will render the different content inside the button element. The function renderField(field: Mine) does exactly that. So when the field is opened (user explored that field) it can be:
bombs == -1 so we render a bomb (using FontAwesome bomb icon for this)
bombs == 0 the field is just empty
bombs > 0 we render the number of bombs in that field.
When the field is opened and flagged we render a flag icon.
The component propagates the mouse onClick event to indicate user interaction with this field.
In minesweeper there are two types of interaction user can have with a field, to explore it or to flag it as potential mine. Maybe better choice is to represent these with different events such as mouse left and right click. But because of a buggy behaviour of the right click, my final choice was to encode these two different events with only left click and a pressed state of a certain keyboard key (ctrl in my case).
MineField component
The MineField component is also functional and is responsible of rendering the full state of the game (the two-dimensional array of mines). Each field is rendered as a separate MineSquare component. It will also propagate the click event from each MineSquare component.
This component is very simple, it should just render the two-dimensional array of mines as grid. Each row is grouped in a separate HTML container divelement and with CSS it is all aligned. To uniquely identify each row we can use the row index i as a React key property, and for each MineSquare component the key would be the combination of indices i and j (the current row and column).
Timer component
The Timer is another stateless component responsible for rendering the elapsed seconds since the game started. To render the seconds in appropriate format 00:00 it uses a custom function secondsToString from our utility module named time.
Here is the implementation of the secondsToString function.
function leadZero(num: number) {
return num < 10 ? `0${num}` : `${num}`;
}
export const time = {
secondsToString: function (seconds: number) {
const min = Math.floor(seconds / 60);
const sec = seconds % 60;
return `${leadZero(min)}:${leadZero(sec)}`;
}
};
One of the known drawbacks of TypeScript and JavaScript language in general is the lack of powerful standard library. But instead of relying on myriad of external modules for simple functions such as leadZero or secondsToString I think it’s better to just implement them.
Game state
So far we have implemented the simple (stateless) components of the game. To make the game alive we need to implement initialization of new game state (new game action) and all possible modifications.
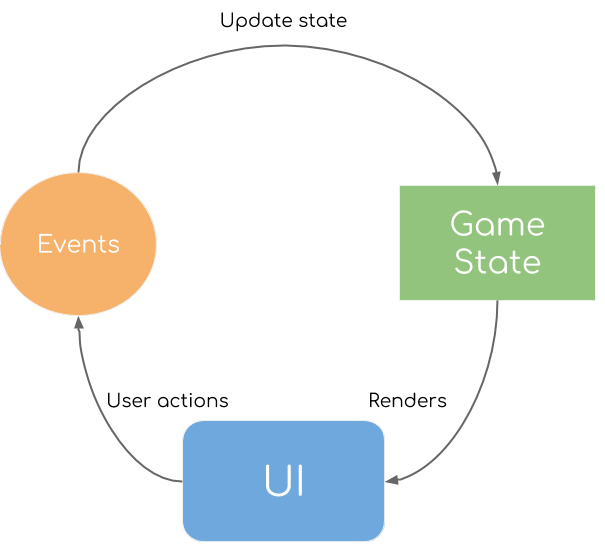
Simplified game loop
Most of the simple games are following some kind of game loop as shown in the image above. The users through the UI are having interactions with the game and are generating actions. Sometimes actions are generated automatically as the time passing, but in Minesweeper that is not the case. On each action, the state of the game is modified and then rendered back on the UI.
In the case of Minesweeper, the user can make three possible actions on not opened field (mine square):
mark it as potential bomb
open it
and if the field is already opened the user can explore neighbours.
Generating new game state
Generating new game state means initializing the two-dimensional array of Mine objects. Some of these mines need to be bombs and we make this decision by using pseudo-random number generator to implement sort of uniform distribution of a mine being a bomb. The BOMBS_PROBABILITY (by default 0.15 or 15%) is the probability of a mine having a bomb. While we create mines we generate a pseudo-random number using Math.random() which has generates a double with uniform distribution in the range of 0-0.99.
After we have initialized the game state with Array<Array<Mine>> we need to update the bombs count of all mines that are neighbouring a bomb. The function fillBombsCount does just that, by traversing all the neighbours of a mine and incrementing the bombs count for each neighbour that is a bomb.
The traverseNeighbours is the utility function that iterates all eight (top left, top, top right, left, right, bottom left, bottom, bottom right) of the neighbours of a given mine.
The function update is a generic function for updating the game state without modifying it. It iterates all of the game state mines and applies a function f that should apply the actual transformation for a mine. This function is used in all functions that need to update the game state in any way.
The function markMine is used for two user actions. The first action is when user wants to mark a mine field as a potential bomb. We do that, only when the current state of the field is not opened by updating the game state where we set that field as flagged and not opened. The second possible action for a user is to explore already opened field that has a count of bombs.
function markMine(game: Game, opened: Mine): Game {
if (opened.isOpened && !opened.isFlagged) return exploreOpenedField(game, opened);
return update(game, (field: Mine) => {
if (field == opened) {
return new Mine(field.position, false, field.bombs, !field.isFlagged);
} else {
return new Mine(field.position, field.isOpened, field.bombs, field.isFlagged);
}
});
}
Exploring opened field
To explore open field is a potentially game ending action that needs to explore all neighbour fields of that field. The opened field that a user explores must have all its neighbour bombs flagged right. If a neighbour field that is a bomb is not flagged, the game ends.
function exploreOpenedField(game: Game, opened: Mine): Game {
const updated = update(game, (field: Mine) => field);
let hitMine = false;
traverseNeighbours(updated.state, opened, field => {
if (!field.isOpened && !field.isFlagged) {
if (isMine(field)) {
hitMine = true;
} else {
field.isOpened = true;
if (field.bombs == 0) {
updateZeros(updated.state, field);
}
}
}
return field;
});
if (hitMine) {
return endGame(game);
}
return updated;
}
To implement this function we use the generic traverseNeighbours and for each neighbour field that is not opened and not flagged:
if it’s a mine we should end the game
if it’s not we should set as opened and if we open a zero-bomb field we should open all other connected zero-bomb fields.
Open mine
function endGame(game: Game): Game {
return update(game, (field) => {
if (isMine(field)) {
return new Mine(field.position, true, field.bombs, field.isFlagged);
} else {
return new Mine(field.position, field.isOpened, field.bombs, field.isFlagged);
}
}, true);
}
function openMine(game: Game, field: Mine): Game {
if (field.isFlagged) return game;
else if (isMine(field)) {
return endGame(game);
} else {
const openField = (openedField: Mine) => (field: Mine) => {
if (field === openedField) {
return new Mine(field.position, true, field.bombs, false);
} else {
return new Mine(field.position, field.isOpened, field.bombs, field.isFlagged);
}
};
let result = update(game, openField(field));
if (field.bombs == 0) {
updateZeros(result.state, field);
}
return result;
}
}
Traversing connected zero-bomb fields
The function updateZeros traverses using a recursive DFS (Depth-First Search) algorithm all connected zero-bomb fields.
On each state modifying action we need to check if the state of game has reached an end state. For the game Minesweeper that state is when all the fields are explored correctly. That means that a mine field that contains a bomb is flagged and otherwise it’s opened.
function checkCompleted(game: Game): boolean {
const and = (a: boolean, b: boolean) => a && b;
return game.state.map(row => {
return row.map(field => {
return isMineCovered(field);
}).reduce(and);
}).reduce(and);
}
function isMineCovered(field: Mine) {
if (isMine(field)) {
return field.isFlagged;
} else {
return field.isOpened;
}
}
The function checkCompleted checks for the end state by iterating all fields and mapping them in to a boolean value. The true value means field is explored correctly and false means not explored correctly. Combining all these values using logical AND would yield final true only if all fields are explored correctly, which would mean the end state is reached.
Count flagged fields
The function countFlagged is used to count all the flagged fields in the game state to show the current progress of flagged/total bombs.
function countFlagged(game: Game): number {
const plus = (a: number, b: number) => a + b;
return game.state.map(row => {
return row.map(field => {
return field.isFlagged ? 1 : 0;
}).reduce(plus, 0);
}).reduce(plus, 0);
}
Putting all together in App component
Once we have implemented all the game state modifications and checks we can put it all together. The actual game state is initialized and modified in the component App.
The final piece of the puzzle, the App component is the only stateful component that keeps and modifies the game state. The state of the component contains:
the number of rows and columns of the Minesweeper grid
the game state
the elapsed seconds since the game started
the number of flagged fields (computed from the game state)
and a boolean flag indicated if the game is completed (also computed from the game state).
The state is initialized at the beginning of the component on a new game state. We use the React lifecycle method componentDidMount to bind two keyboard events onkeydown and onkeyup to track the state of ctrl key. We also start a timer using JavaScript setTimeout function that we use to modify the elapsed seconds state.
The function updateState is used to update the state of the React component using this.setState. This is a HOF (higher-order function) that accepts the actual game state modification function as updateFn as argument. Once the game state is modified, the final state of the component is updated and the UI should be rendered. This function is called on the user generated event onSquareLeftClick. When the ctrl button is down a mine is opened and otherwise mine is marked (or explored).
The actual rendering of the UI is pretty simple. We render a simple menu of three links that allow to start new game with the chosen difficulty. Then we render the MineField component with the current game state and the Timercomponent showing the elapsed seconds. Finally, we render a information on the current status of the game, such as is it completed and number of flagged fields vs total bombs.
Conclusion
Implementing any simple game is an interesting programming challenge. Many times a challenging part is to implement the game state and functions (algorithms) that mutate the state. Favouring functional programming I tried to implement most of these functions as mostly pure functions by using functional constructs such as map and reduce. Also, three out of four React components are functional (stateless or pure functions).
Hopefully sharing my solution and explaining it in this post was interesting and learning experience. If you feel inspired to start learning these technologies by implementing your own Minesweeper or other game, that would be great. And finally, it would be perfect if you also share your code and experience.
What’s the Difference Between Artificial Intelligence, Machine Learning, and Deep Learning?
This is the first of a multi-part series explaining the fundamentals of deep learning by long-time tech journalist Michael Copeland.
Artificial intelligence is the future. Artificial intelligence is science fiction. Artificial intelligence is already part of our everyday lives. All those statements are true, it just depends on what flavor of AI you are referring to.
For example, when Google DeepMind’s AlphaGo program defeated South Korean Master Lee Se-dol in the board game Go earlier this year, the terms AI, machine learning, and deep learning were used in the media to describe how DeepMind won. And all three are part of the reason why AlphaGo trounced Lee Se-Dol. But they are not the same things.
The easiest way to think of their relationship is to visualize them as concentric circles with AI — the idea that came first — the largest, then machine learning — which blossomed later, and finally deep learning — which is driving today’s AI explosion — fitting inside both.
From Bust to Boom
AI has been part of our imaginations and simmering in research labs since a handful of computer scientists rallied around the term at the Dartmouth Conferences in 1956 and birthed the field of AI. In the decades since, AI has alternately been heralded as the key to our civilization’s brightest future, and tossed on technology’s trash heap as a harebrained notion of over-reaching propellerheads. Frankly, until 2012, it was a bit of both.
Over the past few years AI has exploded, and especially since 2015. Much of that has to do with the wide availability of GPUs that make parallel processing ever faster, cheaper, and more powerful. It also has to do with the simultaneous one-two punch of practically infinite storage and a flood of data of every stripe (that whole Big Data movement) – images, text, transactions, mapping data, you name it.
Let’s walk through how computer scientists have moved from something of a bust — until 2012 — to a boom that has unleashed applications used by hundreds of millions of people every day.
Artificial Intelligence — Human Intelligence Exhibited by Machines
King me: computer programs that played checkers were among the earliest examples of artificial intelligence, stirring an early wave of excitement in the 1950s.
Back in that summer of ’56 conference the dream of those AI pioneers was to construct complex machines — enabled by emerging computers — that possessed the same characteristics of human intelligence. This is the concept we think of as “General AI” — fabulous machines that have all our senses (maybe even more), all our reason, and think just like we do. You’ve seen these machines endlessly in movies as friend — C-3PO — and foe — The Terminator. General AI machines have remained in the movies and science fiction novels for good reason; we can’t pull it off, at least not yet.
What we can do falls into the concept of “Narrow AI.” Technologies that are able to perform specific tasks as well as, or better than, we humans can. Examples of narrow AI are things such as image classification on a service like Pinterest and face recognition on Facebook.
Those are examples of Narrow AI in practice. These technologies exhibit some facets of human intelligence. But how? Where does that intelligence come from? That get us to the next circle, Machine Learning.
Machine Learning — An Approach to Achieve Artificial Intelligence
Spam free diet: machine learning helps keep your inbox (relatively) free of spam.
Machine Learning at its most basic is the practice of using algorithms to parse data, learn from it, and then make a determination or prediction about something in the world. So rather than hand-coding software routines with a specific set of instructions to accomplish a particular task, the machine is “trained” using large amounts of data and algorithms that give it the ability to learn how to perform the task.
Machine learning came directly from minds of the early AI crowd, and the algorithmic approaches over the years included decision tree learning, inductive logic programming. clustering, reinforcement learning, and Bayesian networks among others. As we know, none achieved the ultimate goal of General AI, and even Narrow AI was mostly out of reach with early machine learning approaches.
As it turned out, one of the very best application areas for machine learning for many years was computer vision, though it still required a great deal of hand-coding to get the job done. People would go in and write hand-coded classifiers like edge detection filters so the program could identify where an object started and stopped; shape detection to determine if it had eight sides; a classifier to recognize the letters “S-T-O-P.” From all those hand-coded classifiers they would develop algorithms to make sense of the image and “learn” to determine whether it was a stop sign.
Good, but not mind-bendingly great. Especially on a foggy day when the sign isn’t perfectly visible, or a tree obscures part of it. There’s a reason computer vision and image detection didn’t come close to rivaling humans until very recently, it was too brittle and too prone to error.
Time, and the right learning algorithms made all the difference.
Deep Learning — A Technique for Implementing Machine Learning
Another algorithmic approach from the early machine-learning crowd, Artificial Neural Networks, came and mostly went over the decades. Neural Networks are inspired by our understanding of the biology of our brains – all those interconnections between the neurons. But, unlike a biological brain where any neuron can connect to any other neuron within a certain physical distance, these artificial neural networks have discrete layers, connections, and directions of data propagation.
You might, for example, take an image, chop it up into a bunch of tiles that are inputted into the first layer of the neural network. In the first layer individual neurons, then passes the data to a second layer. The second layer of neurons does its task, and so on, until the final layer and the final output is produced.
Each neuron assigns a weighting to its input — how correct or incorrect it is relative to the task being performed. The final output is then determined by the total of those weightings. So think of our stop sign example. Attributes of a stop sign image are chopped up and “examined” by the neurons — its octogonal shape, its fire-engine red color, its distinctive letters, its traffic-sign size, and its motion or lack thereof. The neural network’s task is to conclude whether this is a stop sign or not. It comes up with a “probability vector,” really a highly educated guess, based on the weighting. In our example the system might be 86% confident the image is a stop sign, 7% confident it’s a speed limit sign, and 5% it’s a kite stuck in a tree ,and so on — and the network architecture then tells the neural network whether it is right or not.
Even this example is getting ahead of itself, because until recently neural networks were all but shunned by the AI research community. They had been around since the earliest days of AI, and had produced very little in the way of “intelligence.” The problem was even the most basic neural networks were very computationally intensive, it just wasn’t a practical approach. Still, a small heretical research group led by Geoffrey Hinton at the University of Toronto kept at it, finally parallelizing the algorithms for supercomputers to run and proving the concept, but it wasn’t until GPUs were deployed in the effort that the promise was realized.
If we go back again to our stop sign example, chances are very good that as the network is getting tuned or “trained” it’s coming up with wrong answers — a lot. What it needs is training. It needs to see hundreds of thousands, even millions of images, until the weightings of the neuron inputs are tuned so precisely that it gets the answer right practically every time — fog or no fog, sun or rain. It’s at that point that the neural network has taught itself what a stop sign looks like; or your mother’s face in the case of Facebook; or a cat, which is what Andrew Ng did in 2012 at Google.
Ng’s breakthrough was to take these neural networks, and essentially make them huge, increase the layers and the neurons, and then run massive amounts of data through the system to train it. In Ng’s case it was images from 10 million YouTube videos. Ng put the “deep” in deep learning, which describes all the layers in these neural networks.
Today, image recognition by machines trained via deep learning in some scenarios is better than humans, and that ranges from cats to identifying indicators for cancer in blood and tumors in MRI scans. Google’s AlphaGo learned the game, and trained for its Go match — it tuned its neural network — by playing against itself over and over and over.
Thanks to Deep Learning, AI Has a Bright Future
Deep Learning has enabled many practical applications of Machine Learning and by extension the overall field of AI. Deep Learning breaks down tasks in ways that makes all kinds of machine assists seem possible, even likely. Driverless cars, better preventive healthcare, even better movie recommendations, are all here today or on the horizon. AI is the present and the future. With Deep Learning’s help, AI may even get to that science fiction state we’ve so long imagined. You have a C-3PO, I’ll take it. You can keep your Terminator.