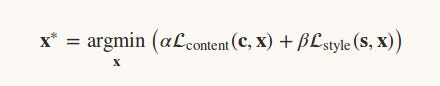This morning I found myself summarizing my favorite bits from a talk that I enjoyed at Google Cloud Next in San Francisco, What’s New with TensorFlow?
Then I thought about it for a moment and couldn’t see a reason not to share my super-short summary with you (except maybe that you might not watch the video — you totally should check it out, the speaker is awesome) so here goes…
#1 It’s a powerful machine learning framework
TensorFlow is a machine learning framework that might be your new best friend if you have a lot of data and/or you’re after the state-of-the-art in AI: deep learning. Neural networks. Big ones. It’s not a data science Swiss Army Knife, it’s the industrial lathe… which means you can probably stop reading if all you want to do is put a regression line through 20-by-2 spreadsheet.
Discovered with the help of TensorFlow, the planet Kepler-90i makes the Kepler-90 system the only other system we know of that has eight planets in orbit around a single star. No system has been found with more than eight planets, so I guess that means we’re tied with Kepler-90 for first place (for now). Learn more here.
If you tried TensorFlow in the old days and ran away screaming because it forced you to code like an academic/alien instead of like a developer, come baaaack!
TensorFlow eager execution lets you interact with it like a pure Python programmer: all the immediacy of writing and debugging line-by-line instead of holding your breath while you build those huge graphs. I’m a recovering academic myself (and quite possibly an alien), but I’ve been in love with TF eager execution since it came out. So eager to please!
#3 You can build neural networks line-by-line
Keras + TensorFlow = easier neural network construction!
Keras is all about user-friendliness and easy prototyping, something old TensorFlow sorely craved more of. If you like object oriented thinking and you like building neural networks one layer at a time, you’ll love tf.keras. In just the few lines of code below, we’ve created a sequential neural network with the standard bells and whistles like dropout (remind me to wax lyrical about my metaphors for dropout sometime, they involve staplers and the flu).
Oh, you like puzzles, do you? Patience. Don’t think too much about staplers.
#4 It’s not only Python
Okay, you’ve been complaining about TensorFlow’s Python monomania for a while now. Good news! TensorFlow is not just for Pythonistas anymore. It now runs in many languages, from R to Swift to JavaScript.
#5 You can do everything in the browser
Speaking of JavaScript, you can train and execute models in the browser with TensorFlow.js. Go nerd out on the cool demos, I’ll still be here when you get back.
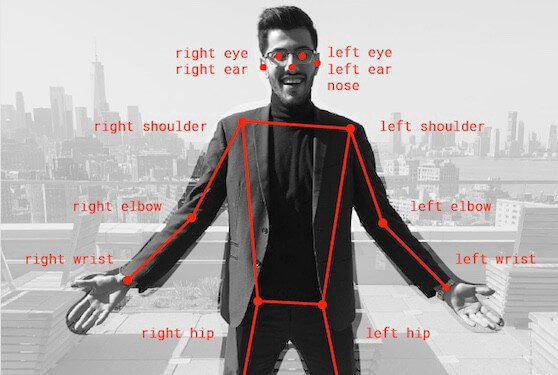
Real-time Human Pose Estimation in the browser with TensorFlow.js. Turn on your camera for a demo here. Or don’t get out of your chair. ¯\_(ツ)_/¯ Up to you.
#6 There’s a Lite version for tiny devices
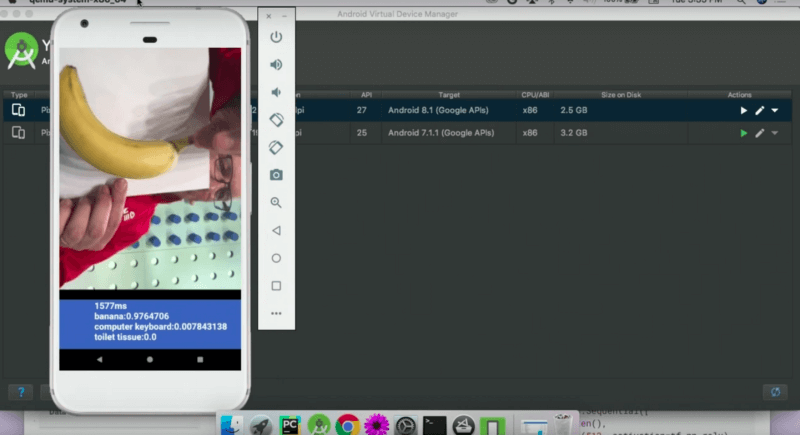
Got a clunker desktop from a museum? Toaster? (Same thing?) TensorFlow Lite brings model execution to a variety of devices, including mobile and IoT, giving you more than a 3x boost in inference speedup over original TensorFlow. Yes, now you can get machine learning on your Raspberry Pi or your phone. In the talk, Laurence does a brave thing by live-demoing image classification on an Android emulator in front of thousands… and it works.
1.6 seconds to compute? Check! Banana with over 97% probability? Check! Toilet tissue? Well, I’ve been to a few countries where I suppose a sheet of paper like the one Laurence is holding up counts.
#7 Specialized hardware just got better
If you’re tired of waiting for your CPU to finish churning through your data to train your neural network, you can now get your hands on hardware specially designed for the job with Cloud TPUs. The T is for tensor. Just like TensorFlow… coincidence? I think not! A few weeks ago, Google announced version 3 TPUs in alpha.
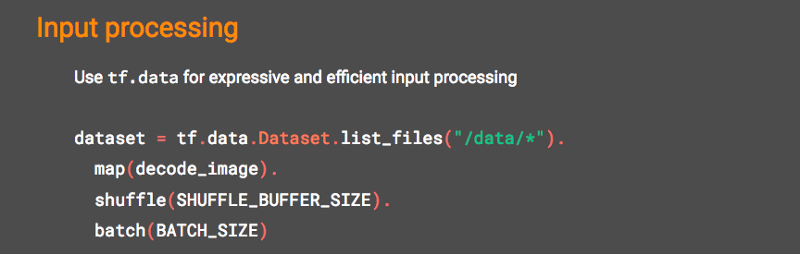
#8 The new data pipelines are much improved
What’s that you’re doing with numpy over there? In case you wanted to do it in TensorFlow but then rage-quit, the tf.data namespace now makes your input processing in TensorFlow more expressive and efficient. tf.data gives you fast, flexible, and easy-to-use data pipelines synchronized with training.
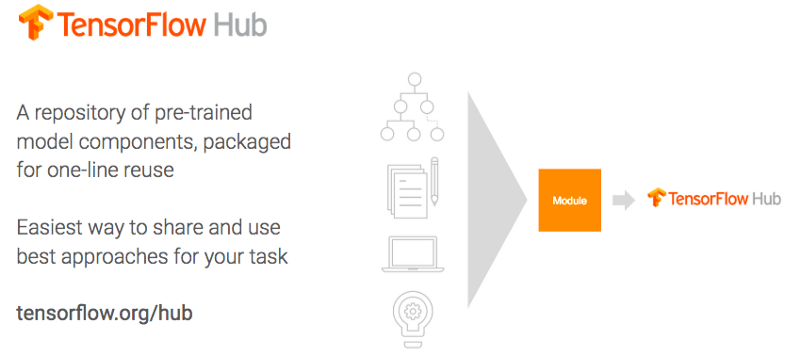
#9 You don’t need to start from scratch
You know what’s not a fun way to get started with machine learning? A blank new page in your editor and no example code for miles. With TensorFlow Hub, you can engage in a more efficient version of the time-honored tradition of helping yourself to someone else’s code and calling it your own (otherwise known as professional software engineering).
TensorFlow Hub is a repository for reusable pre-trained machine learning model components, packaged for one-line reuse. Help yourself!
While we’re on the subject of community and not struggling alone, you might like to know that TensorFlow just got an official YouTube channel and blog.
That concludes my summary, so here’s the full talk to entertain you for the next 42 minutes.
We’ve all seen (and written) bad code at one point or another and hopefully we’re all working at bettering these skills and not just learning the newest framework out there.
Why do we need to write good code, not just performant code?
While the performance of your product or site is important, so is the way your code looks. This reasoning behind this is that the machine isn’t the only entity reading your code.
First, and foremost, you are eventually going to have to re-read some portion of your code, if not the whole thing, and when that time comes performant code isn’t going to help you understand what you’ve written or figure out how to fix it.
Second, if you work on a team or collaborate with other developers then any time you write code your team members have to read your code and try to interpret it in a way they understand. To make that easier for them, it’s important to consider how you name variables and functions, the length of each line, and the structure of your code, among other things.
Lastly, it’s just nicer to look at.
Part 1: How do you identify bad code?
The simplest way to identify bad code, in my opinion, is to try to read your code as if it were a sentence or phrase.
For example, here is some code:
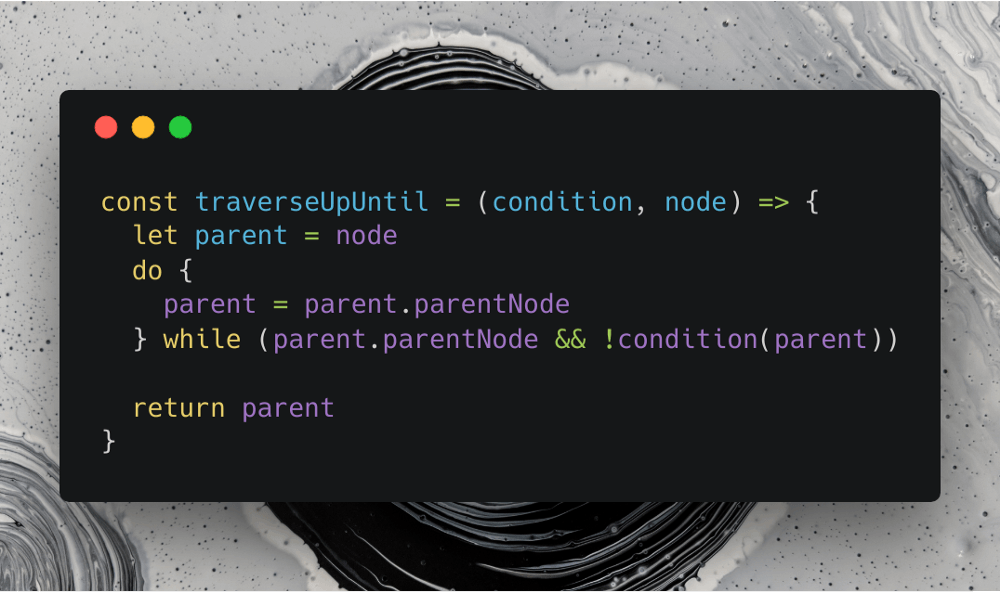
The pictured function above, when passed an element and a conditional function returns the nearest parent node that passes the conditional function.
const traverseUpUntil = (el, f) => {
Following the idea that code should be readable like regular writing, the first line has three fatal flaws.
The parameters for the function are not readable like words.
While el can be understood as it is commonly used to mean element, the parameter name f does not explain its purpose.
If you were to use the function it would read like so: “traverse up until el passes f” which could probably better read as “traverse up until f passes, from el”. Granted, the best way to actually do this would to allow the function to be called like el.traverseUpUntil(f) but that’s a different problem.
let p = el.parentNode
This is the second line. Again we have a naming issue, this time with a variable. If one were to look at the code they would most likely understand what p is. It is the parentNode of parameter el . However, what happens when we look at p used anywhere else, we no longer have the context that explains what it is.
while (p.parentNode && !f(p)) {
In this line, the main problem we encounter is not knowing what !f(p) means or does, because “f”could mean anything at this point. What the person reading the code is supposed to understand is that !f(p) is a check to see if the current node passes the condition. If it does, stop the loop.
p = p.parentNode
This one is pretty self-explanatory.
return p
Not 100% clear what is being returned due to the bad variable name.
Part 2: Let’s make improvments
First we modify the parameter names and their order:(el, f) => into (condition, node) => (you can also do condition => node => which adds an extra layer of useability)
You might be wondering why, instead of using “element”, I used “node”. I used it because of the following:
We are already writing code in terms of nodes, for example .parentNode , so why not make it all the same.
It’s shorter than writing element without losing it’s meaning. And the reason why I say this is that it works with all forms of nodes that have the property “parentNode”, not just HTML elements.
Next we touch up on the variable name(s):
let parent = node
It’s very important to fully elaborate the meaning of your variable within its name, “p” is now “parent”. You may have also noticed we aren’t starting out by getting node.parentNode , instead we only get node .
This leads us into our next few lines:
do {
parent = parent.parentNode
} while (parent.parentNode && !condition(parent))
Instead of a regular while loop I’ve opted for a do … while loop. This means that we only have to get the parent node once, as it runs the condition after the action, not the other way around. The use of the do … while loop also reaches back to being able to read the code like writing.
Let’s try reading it: “Do parent equals parent’s parent node while there is a parent node and the condition function doesn’t return true.” While that may seem a bit weird it helps us understand what the code means when we can easily read it.
return parent
While many people opt to use the generic ret variable (or returnValue), it is not a good practice to name the variable you return “ret”. If you name your return variables appropriately it becomes obvious to what is being returned. However, sometimes functions can be long and daunting causing it to be more confusing. In this instance, I would suggest splitting your function into multiple functions and if it’s still too complicated adding comments can help.
Part 3: Simplify the code
Now that you’ve made the code readable it’s time to take out any unnecessary code. As I’m sure some of you have already noticed, we probably don’t need the variable parent at all.
const traverseUpUntil = (condition, node) => {
do {
node = node.parentNode
} while (node.parentNode && !condition(node))
return node
}
What I’ve done is taken out the first line and replaced “parent” with “node”. This bypasses the unnecessary step of creating “parent” and goes straight to the loop.
But what about the variable name?
While “node” isn’t the best descriptor for this variable, it’s a decent one. But let’s not settle for decent, let’s rename it. How about “currentNode”?
const traverseUpUntil = (condition, currentNode) => {
do {
currentNode = currentNode.parentNode
} while (currentNode.parentNode && !condition(currentNode))
return currentNode
}
That’s better! Now when we read it we know that no matter what currentNode will always represent the node we are currently at instead of it just being some node.
Art is not merely an imitation of the reality of nature, but in truth a metaphysical supplement to the reality of nature, placed alongside thereof for its conquest.
– Friedrich Nietzsche
The history of art and technology have always been intertwined. Artistic revolutions which has happened in history were made possible by the tools to make the work. The precision of flint knives allowed humans to sculpt the first pieces of figurative art out of mammoth ivory. In the present age , artists work with tools ranging from 3D printing to virtual reality, stretching the possibilities of self-expression.
We are entering an age where AI is becoming increasingly present in almost every field . Elon Musk thinks it will exceed humans at everything in by 2030 , but art has been viewed as a pantheon of humanity, something quintessentially human that an AI could never replicate. In this series of articles , we will create awesome pieces of art with the help of machine learning .
Project 1: Neural Style Transfer
What is neural style transfer ?
It is simply the process of re-imagining one image in the style of other. It is one of the coolest applications of image processing using convolution neural networks. Imagine you could have any famous artist(for example Michelangelo)paint you a picture of your whatever you want in just milli-seconds. In this article I will try to give a brief description about the implementation details. For more information you can refer paper by Gatys et al., 2015 . The paper achieves what we are trying to do as an optimization problem
Let’s think that we are trying to build an image classifier that can predict what an image is . We use supervised learning for solving this. Given a color image (RGB image) which consists of D = W X H X 3 (color depth = 3) be stored as an array .We assume that there are “n” categories to be classified into.The task is to come up with a function which classify our image as being one of “n” images.
To build this we start with a set of previously classified labeled “training data”. We can use a simple linear activation function [F(x,W,b) = Wx +b] for score function.W — matrix of size n X D called weights and vector b of size n X 1 called biases. To predict probability for each category , we pass this output through something called a softmax functionσ that squashes the scores to a set of numbers between 0 and 1 that add up to 1. Let’s suppose our training data is a set of N pre-classified examples xi∈ℝD, each with correct category yi∈1,…,K. To determine the total loss across all these examples is the cross entropy loss:
L(s)=−∑i log(syi)
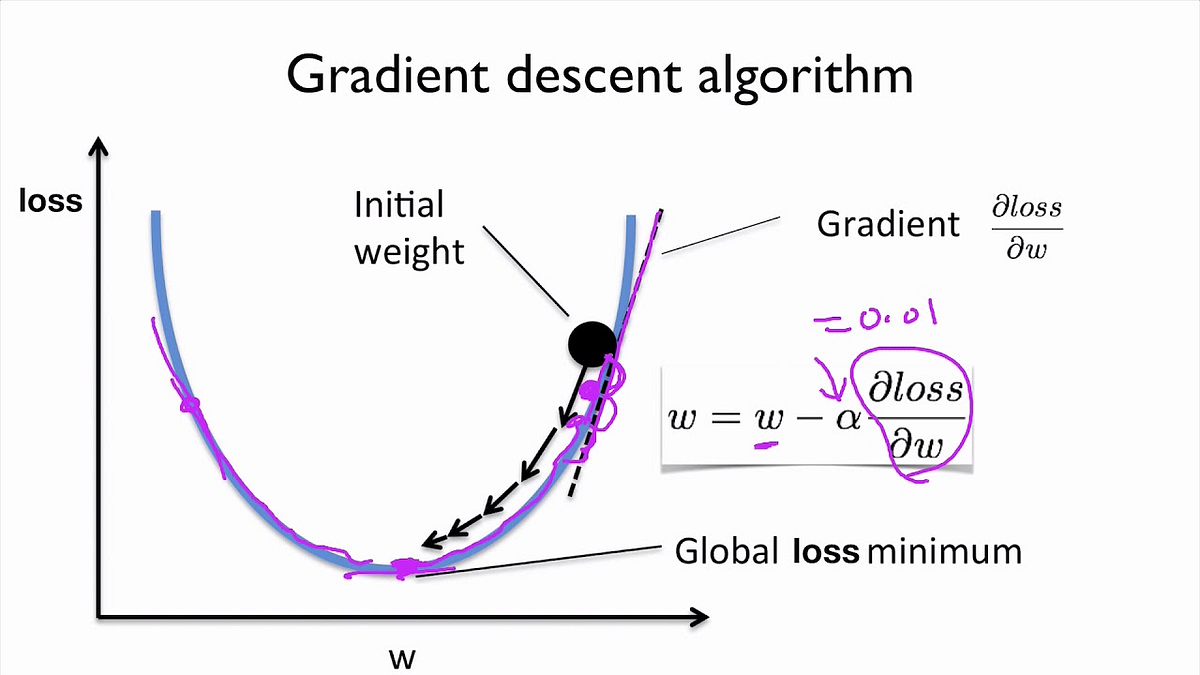
For the optimization part ,we use gradient descent. We have to find weights and biases that minimizes this loss.
Our aim here is to find the global loss minimum which is at the bottom of the curve. We also use a parameter called the learning rate(α), which is a measure of how fast we modify our weights.
Summing it all up, initially we gave some image as a raw array of numbers, we have a parameterised score function (linear transformation followed by a softmax function) that takes us to category scores. We have a way of evaluating its performance (the cross entropy loss function). Then we improve the classifier’s parameters (optimisation using gradient descent). But here the accuracy is less , therefore we use Convolutional Neural Networks to improve accuracy.
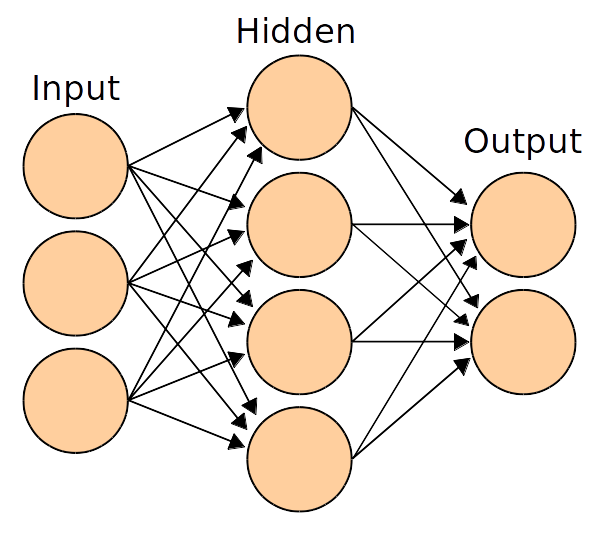
Basics of Convolutional Neural Network(CNN)
Diagram of a simple network from Wikipedia
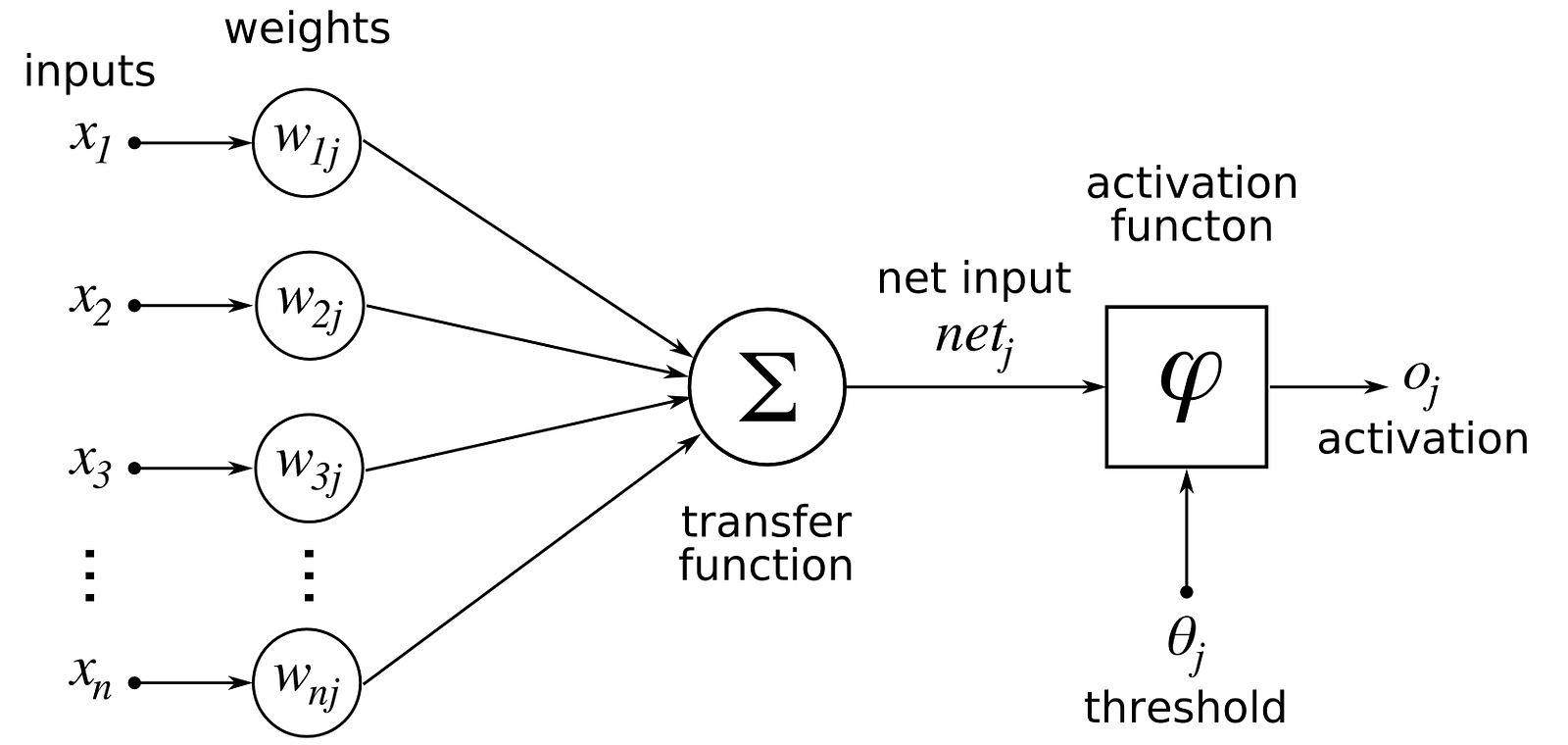
Previously we used linear score function ,but here we will use non-linear score function.For this we use neurons which are functions which first multiplies each of its inputs by a weight and sums these weighted inputs to a single number and adds a bias. It then passes this number through a nonlinear function called the activation and produces an output.
Normally to improve the accuracy of our classifier, we’d probably think that it is easy to do so by adding more layers to our score function.But there are some problems to that –
1. Generally, neural networks entirely disregard the 2D structure of the image . For example if we are working with the input image as a 30×30 matrix, they worked with the input as a 900 number array. And you can imagine there is some useful information in pixels sharing proximity that’s being lost.
2. Number of parameters we would need to learn grows really rapidly as we add more layers.
To solve these problems , we use convolutional neural networks.
Difference between normal networks and CNN is that instead of using input data as linear arrays, it uses input data with width, height and depth and outputs a 3D volume of numbers. What one imagines as a 2D input image (W×H) gets transformed into 3D by introducing the colour depth as the third dimension (W×H×d). (it is 1 for greyscale and 3 for RGB.) Similarly what one might imagine as a linear output of length C is actually represented as 1×1×C. There are two layer types which we use –
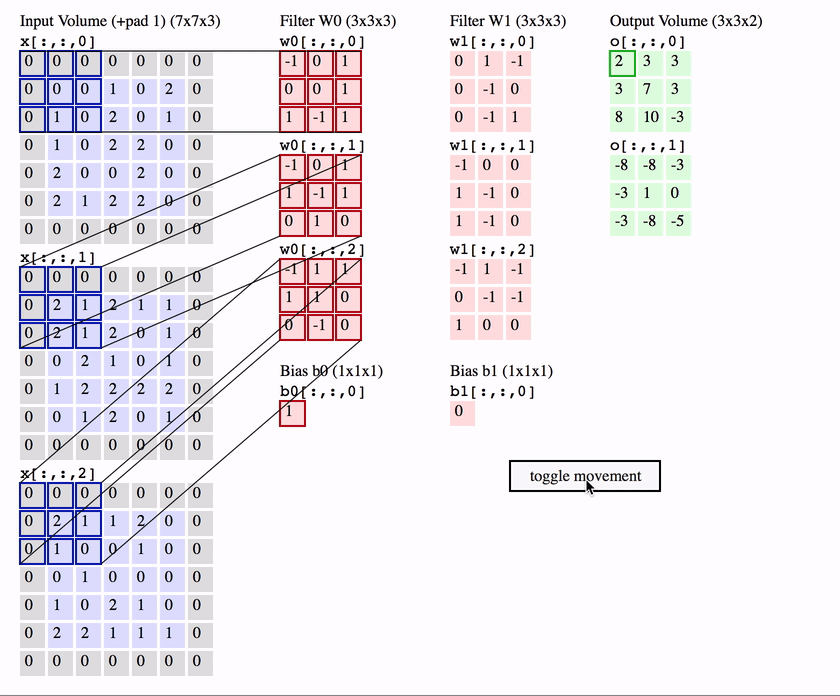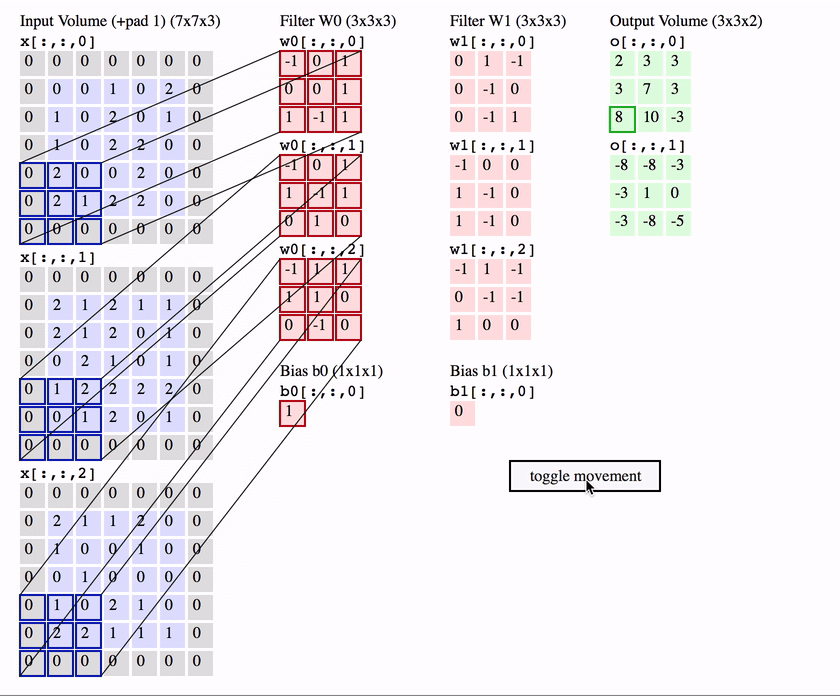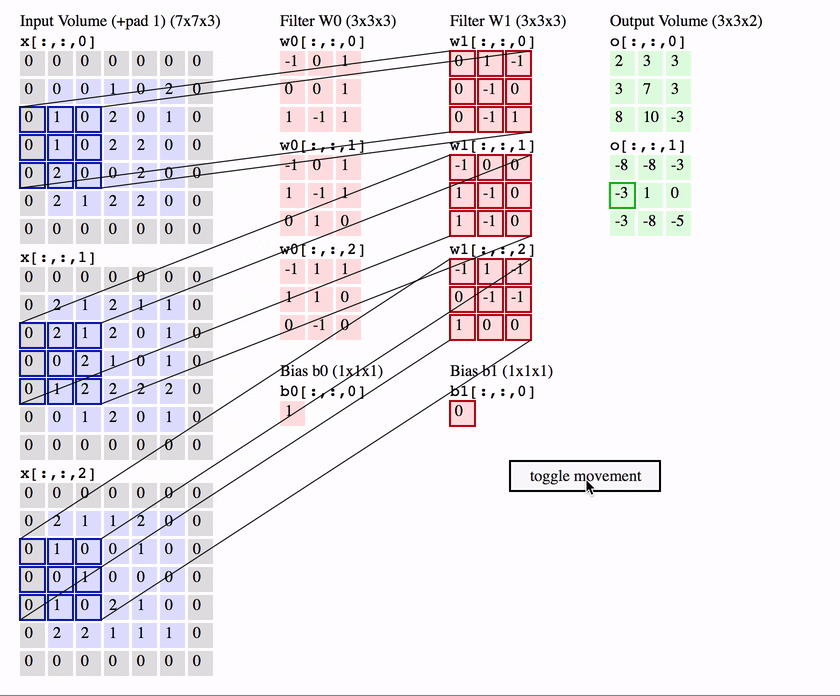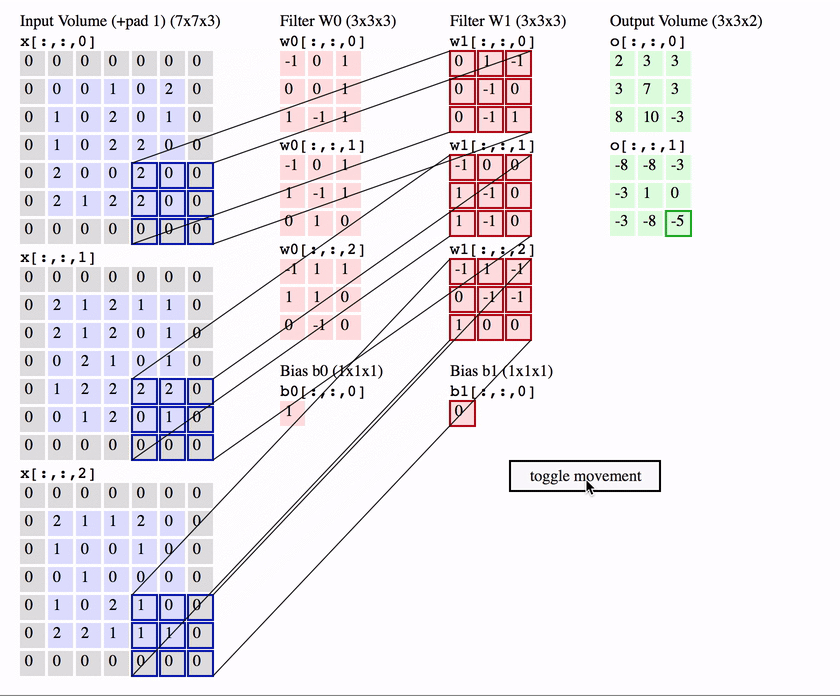
1. Convolutional layer
The first is the convolutional (Conv) layer. Here we have a set of filters. Let’s assume that we have K such filters. Each filter is small , with an extent denoted by F and has depth value of its input. e.g. A typical filter might be 3×3×3 (3 pixels wide and high, and 3 from the depth of the input 3-channel color image).
Convolutional layer with K = 2 filters, each with a spatial extent F = 3 , moving at a stride S = 2, and input padding P = 1. (Reproduced from CS231n notes)
We slide the filter set over the input volume with a stride S that denotes how fast we move. This input can be spatially padded (P) with zeros as needed for controlling output spatial dimensions. As we slide, each filter computes dot product with the input to produce a 2D output, and when we stack these across all the filters we have in our set, we get a 3D output volume.
2. Pooling layer
Its function is to progressively reduce the spatial size of the representation to reduce the amount of parameters and computation in the network. It does not have any parameters to learn.
For example, a max pooling layer with a spatial extent F=2 and a stride S=2 halves the input dimensions from 4×4 to 2×2, leaving the depth unchanged. It does this by picking the maximum of each set of 2×2 numbers and passing only those along to the output.
This wraps up fundamentals and I hope you have got the idea about the basic workings.
Let’s begin !
Content image and style image
Content image (c) is the image that you would want to be re-create. It provides the main content to the new output image. It could be any image of a dog, a selfie or almost anything that you would want to be painted in a new style. Style image (s) on the other hand provides the artistic features of an image such as pattern, brush strokes, color, curves and shapes. Let’s call the style transferred output image as x.
Loss functions
Lcontent(c,x) : Here our aim is to minimize loss between content image and output image, which means we have a function that tends to 0 when its two input images (c and x) are very close to each other in terms of content, and grows as their content deviates. We call this function the content loss.
Lstyle(s,x): This is the function which shows how close in style two images are to one another. Again, this function grows as its two input images (s and x) tend to deviate in style. We call this function the style loss.
Now we need to find an image x such that it differs little from content image and style image.
α and β are used to balance the content and style in the resultant image.
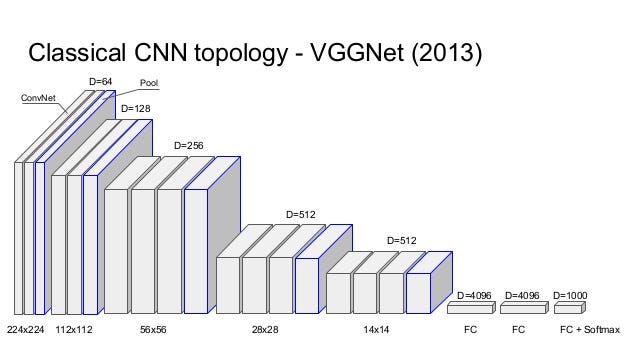
Here we will be using VGGNet which is a CNN-based image classifier which has already learnt to encode perceptual(e.g., stroke size,spatial style control, and color control) and semantic information that we need to measure these semantic difference terms.
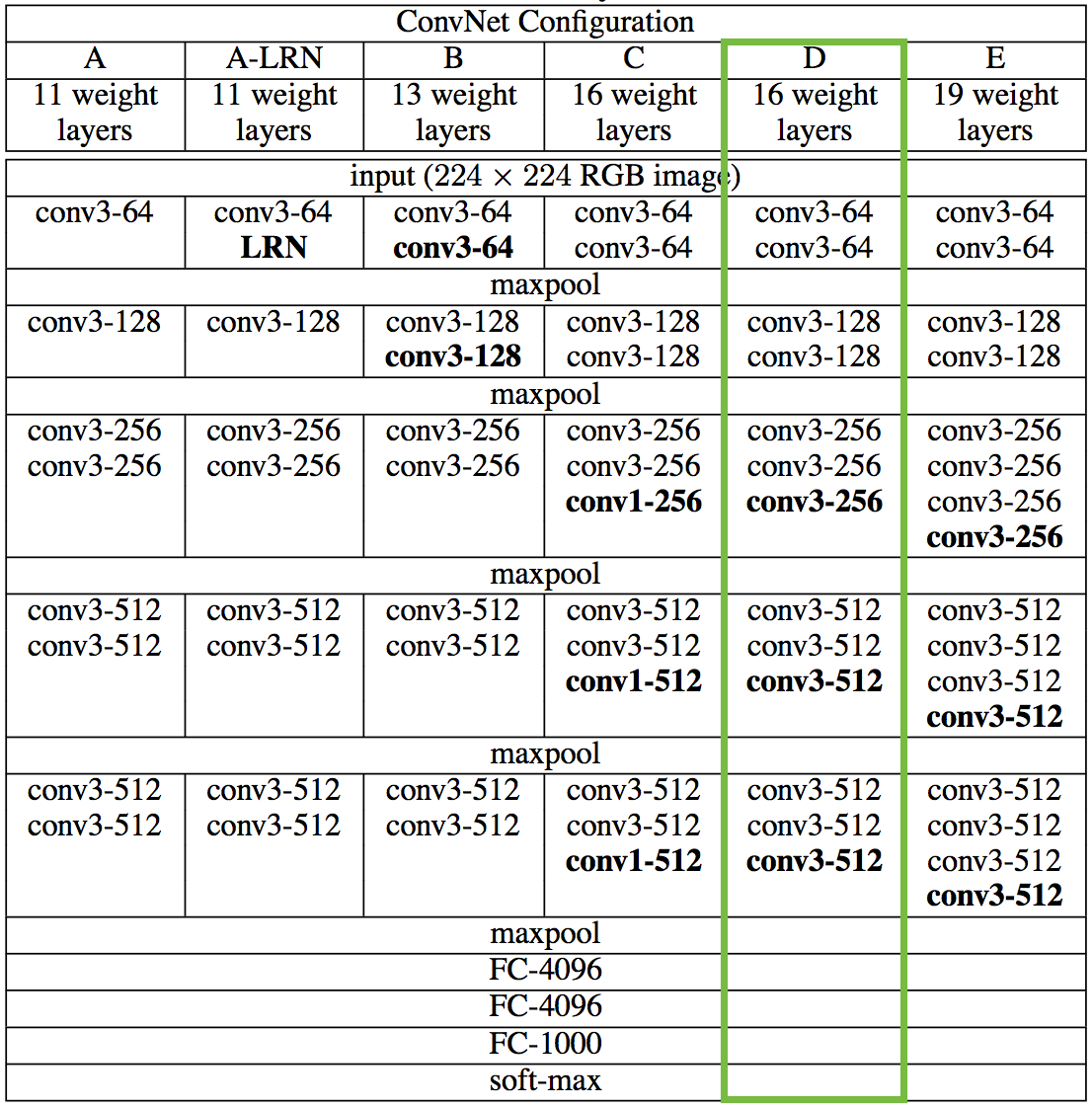
VGGNet considerably simplified the ConvNet design, by repeating the same smaller convolution filter configuration 16 times: All the filters in VGGNet were limited to 3×3 , with stride and padding of 1, along with 2×2 maxpooling filters with stride of 2.
We’re going to first reproduce the 16 layer variant marked in green for classification, and in the next notebook we’ll see how it can be repurposed for the style transfer problem.
Normal VGG takes an image and returns a category score, but here we take the outputs at intermediate layers and build Lcontent and Lstyle. Here we don’t include any of the fully-connected layers.
Let’s get coding ,
Import the necessary packages.
from keras.applications.vgg16 import preprocess_input, decode_predictions
import time
from PIL import Image
import numpy as np
from keras import backend
from keras.models import Model
from keras.applications.vgg16 import VGG16
from scipy.optimize import fmin_l_bfgs_b
from scipy.misc import imsave
Now we convert these images into a suitable form for numerical processing. In particular, we add another dimension (beyond height x width x 3 dimensions) so that we can later concatenate the representations of these two images into a common data structure.
Now we’re ready to use these arrays to define variables in Keras backend . We also introduce a placeholder variable to store the combination image that retains the content of the content image while incorporating the style of the style image.
The original paper uses the 19 layer VGG network model from Simonyan and Zisserman (2015), but we’re going to instead follow Johnson et al. (2016) and use the 16 layer model (VGG16) . Since we are not interested in image classification , we can set include_top=False so that we don’t include any of the fully-connected layers.
model = VGG16(input_tensor=input_tensor, weights='imagenet', include_top=False)
The loss function we want to minimise can be decomposed into content loss, style loss and the total variation loss.
The relative importance of these terms are determined by a set of scalar weights. The choice of these values are up to you , but the following have worked better for me
For the content loss, we draw the content feature from block2_conv2.The content loss is the squared Euclidean distance between content and combination images.
loss += content_weight * content_loss(content_image_features,
combination_features)
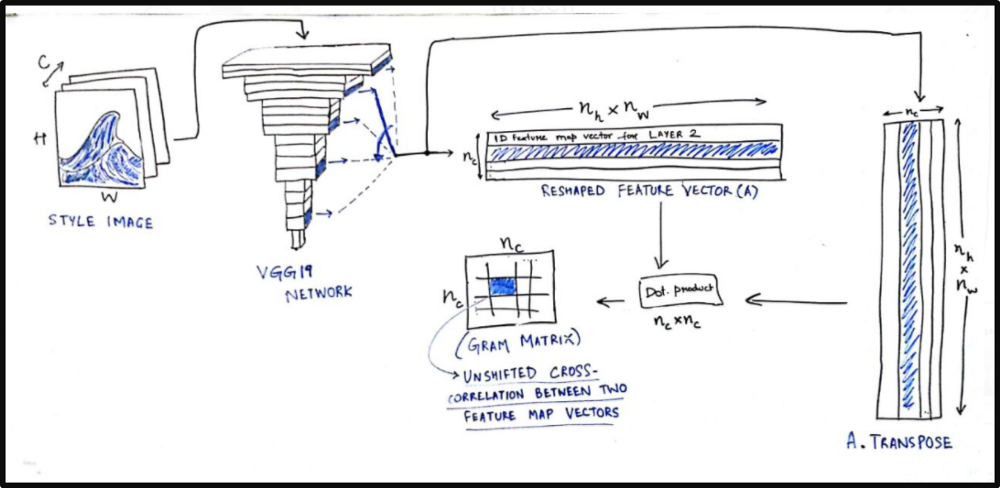
For the style loss, we first define something called a Gram matrix. Gram matrix of a set of images which represents the similarity or difference between two images. If you have an (m x n) image, reshape it to a (m*n x 1) vector. Similarly convert all images to vector form and form a matrix ,say, A.
then the gram matrix G of these set of images will be
G = A.transpose() * A;
Each element G(i,j) will represent the similarity measure between image i and j.
We obtain the style loss by calculating Frobenius norm(It is the matrix norm of a matrix defined as the square root of the sum of the absolute squares of its elements) of the difference between the Gram matrices of the style and combination images.
The resultant image is available in the image_final.
Raja Ravi Varma painting in Van Gogh style
Conclusion
This project will give you a broad idea about the working of CNN and clarify a lot of basic doubts. In this series of articles we will explore the various ways in which deep learning can be used for creative purposes.
推荐理由:面向喜爱 Linux 和开源的孩子们的书籍,兴许等有了孩子之后我们可以推荐给他们看一看,这些书大部分都是简单易懂的
15 books for kids who (you want to) love Linux and open source
In my job I’ve heard professionals in tech, from C-level executives to everyone in between, say they want their own kids to learn more about Linux and open source. Some of them seem to have an easy time with their kids following closely in their footsteps. And some have a tough time getting their kids to see what makes Linux and open source so cool. Maybe their time will come, maybe it won’t. There’s a lot of interesting, valuable stuff out there in this big world.
Either way, if you have a kid or know a kid that may be interested in learning more about making something with code or hardware, from games to robots, this list is for you.
15 books for kids with a focus on Linux and open source
The tiny, credit-card sized Raspberry Pi has become a huge hit among kids—and adults—interested in programming. It does everything your desktop can do, but with a few basic programming skills you can make it do so much more. With simple instructions, fun projects, and solid skills, Adventures in Raspberry Pi is the ultimate kids’ programming guide! (Recommendation by Joshua Allen Holm | Review is an excerpt from the book’s abstract)
This is a classic introduction to programming that’s written clearly enough for a motivated 11-year-old to understand and enjoy. Readers will quickly find themselves working on practical and useful tasks while picking up good coding practices almost by accident. The best part: If you like, you can read the whole book online. (Recommendation and review by DB Clinton)
Written for children ages 8-12 with little to no coding experience, this straightforward visual guide uses fun graphics and easy-to-follow instructions to show young learners how to build their own computer projects using Scratch, a popular free programming language. (Recommendation by Joshua Allen Holm | Review is an excerpt from the book’s abstract)
Whether you’re a student or a teacher who’s curious about how you can use Python for mathematics, this book is for you. Beginning with simple mathematical operations in the Python shell to the visualization of data using Python libraries like matplotlib, this books logically takes the reader step by easily followed step from the basics to more complex operations. This book will invite your curiosity about the power of Python with mathematics. (Recommendation and review by Don Watkins)
From the leader of the movement championed by Sheryl Sandberg, Malala Yousafzai, and John Legend, this book is part how-to, part girl-empowerment, and all fun. Bursting with dynamic artwork, down-to-earth explanations of coding principles, and real-life stories of girls and women working at places like Pixar and NASA, this graphically animated book shows what a huge role computer science plays in our lives and how much fun it can be. (Recommendation by Joshua Allen Holm | Review is an excerpt from the book’s abstract)
This book will teach you how to make computer games using the popular Python programming language—even if you’ve never programmed before! Begin by building classic games like Hangman, Guess the Number, and Tic-Tac-Toe, and then work your way up to more advanced games, like a text-based treasure hunting game and an animated collision-dodging game with sound effects. (Recommendation by Joshua Allen Holm | Review is an excerpt from the book’s abstract)
Written in the spirit of Alice in Wonderland, Lauren Ipsum takes its heroine through a slightly magical world whose natural laws are the laws of logic and computer science and whose puzzles can be solved only through learning and applying the principles of computer code. Computers are never mentioned, but they’re at the center of it all. (Recommendation and review by DB Clinton)
Java is the world’s most popular programming language, but it’s known for having a steep learning curve. This book takes the chore out of learning Java with hands-on projects that will get you building real, functioning apps right away. (Recommendation by Joshua Allen Holm | Review is an excerpt from the book’s abstract)
Kindergarten is becoming more like the rest of school. In this book, learning expert Mitchel Resnick argues for exactly the opposite: The rest of school (even the rest of life) should be more like kindergarten. To thrive in today’s fast-changing world, people of all ages must learn to think and act creatively―and the best way to do that is by focusing more on imagining, creating, playing, sharing, and reflecting, just as children do in traditional kindergartens. Drawing on experiences from more than 30 years at MIT’s Media Lab, Resnick discusses new technologies and strategies for engaging young people in creative learning experiences. (Recommendation by Don Watkins | Review from Amazon)
Jason Briggs has taken the art of teaching Python programming to a new level in this book that can easily be an introductory text for teachers and students as well as parents and kids. Complex concepts are presented with step-by-step directions that will have even neophyte programmers experiencing the success that invites you to learn more. This book is an extremely readable, playful, yet powerful introduction to Python programming. You will learn fundamental data structures like tuples, lists, and maps. The reader is shown how to create functions, reuse code, and use control structures like loops and conditional statements. Kids will learn how to create games and animations, and they will experience the power of Tkinter to create advanced graphics. (Recommendation and review by Don Watkins)
Scratch programming is often seen as a playful way to introduce young people to programming. In this book, Al Sweigart demonstrates that Scratch is in fact a much more powerful programming language than most people realize. Masterfully written and presented in his own unique style, Al will have kids exploring the power of Scratch to create complex graphics and animation in no time. (Recommendation and review by Don Watkins)
From graphic novel superstar (and high school computer programming teacher) Gene Luen Yang comes a wildly entertaining new series that combines logic puzzles and basic programming instruction with a page-turning mystery plot. Stately Academy is the setting, a school that is crawling with mysteries to be solved! (Recommendation by Joshua Allen Holm | Review is an excerpt from the book’s abstract)
Love coding? Make your passion your profession with this comprehensive guide that reveals a whole host of careers working with code. (Recommendation by Joshua Allen Holm | Review is an excerpt from the book’s abstract)
Are you looking for a playful way to introduce children to programming with Python? Bryson Payne has written a masterful book that uses the metaphor of turtle graphics in Python. This book will have you creating simple programs that are the basis for advanced Python programming. This book is a must-read for anyone who wants to teach young people to program. (Recommendation and review by Don Watkins)
These concept books familiarize young ones with the kind of shapes and colors that make up web-based programming languages. This beautiful book is a colorful introduction to coding and the web, and it’s the perfect gift for any technologically minded family. (Recommendation by Chris Short | Review from Amazon)