For the past month, we ranked nearly 250 Python Open Source Projects to pick the Top 10.
We compared projects with new or major release during this period. Mybridge AI ranks projects based on a variety of factors to measure its quality for professionals.
Average number of Github stars in this edition: 570⭐️
“Watch” Python Top 10 Open Source on Github and get email once a month.
Unimatrix: Python script to simulate the display from “The Matrix” in terminal. Uses half-width katakana unicode characters by default, but can use custom character sets. Accepts keyboar… [558 stars on Github]. Courtesy of Will8211
What’s the Difference Between Artificial Intelligence, Machine Learning, and Deep Learning?
This is the first of a multi-part series explaining the fundamentals of deep learning by long-time tech journalist Michael Copeland.
Artificial intelligence is the future. Artificial intelligence is science fiction. Artificial intelligence is already part of our everyday lives. All those statements are true, it just depends on what flavor of AI you are referring to.
For example, when Google DeepMind’s AlphaGo program defeated South Korean Master Lee Se-dol in the board game Go earlier this year, the terms AI, machine learning, and deep learning were used in the media to describe how DeepMind won. And all three are part of the reason why AlphaGo trounced Lee Se-Dol. But they are not the same things.
The easiest way to think of their relationship is to visualize them as concentric circles with AI — the idea that came first — the largest, then machine learning — which blossomed later, and finally deep learning — which is driving today’s AI explosion — fitting inside both.
From Bust to Boom
AI has been part of our imaginations and simmering in research labs since a handful of computer scientists rallied around the term at the Dartmouth Conferences in 1956 and birthed the field of AI. In the decades since, AI has alternately been heralded as the key to our civilization’s brightest future, and tossed on technology’s trash heap as a harebrained notion of over-reaching propellerheads. Frankly, until 2012, it was a bit of both.
Over the past few years AI has exploded, and especially since 2015. Much of that has to do with the wide availability of GPUs that make parallel processing ever faster, cheaper, and more powerful. It also has to do with the simultaneous one-two punch of practically infinite storage and a flood of data of every stripe (that whole Big Data movement) – images, text, transactions, mapping data, you name it.
Let’s walk through how computer scientists have moved from something of a bust — until 2012 — to a boom that has unleashed applications used by hundreds of millions of people every day.
Artificial Intelligence — Human Intelligence Exhibited by Machines
King me: computer programs that played checkers were among the earliest examples of artificial intelligence, stirring an early wave of excitement in the 1950s.
Back in that summer of ’56 conference the dream of those AI pioneers was to construct complex machines — enabled by emerging computers — that possessed the same characteristics of human intelligence. This is the concept we think of as “General AI” — fabulous machines that have all our senses (maybe even more), all our reason, and think just like we do. You’ve seen these machines endlessly in movies as friend — C-3PO — and foe — The Terminator. General AI machines have remained in the movies and science fiction novels for good reason; we can’t pull it off, at least not yet.
What we can do falls into the concept of “Narrow AI.” Technologies that are able to perform specific tasks as well as, or better than, we humans can. Examples of narrow AI are things such as image classification on a service like Pinterest and face recognition on Facebook.
Those are examples of Narrow AI in practice. These technologies exhibit some facets of human intelligence. But how? Where does that intelligence come from? That get us to the next circle, Machine Learning.
Machine Learning — An Approach to Achieve Artificial Intelligence
Spam free diet: machine learning helps keep your inbox (relatively) free of spam.
Machine Learning at its most basic is the practice of using algorithms to parse data, learn from it, and then make a determination or prediction about something in the world. So rather than hand-coding software routines with a specific set of instructions to accomplish a particular task, the machine is “trained” using large amounts of data and algorithms that give it the ability to learn how to perform the task.
Machine learning came directly from minds of the early AI crowd, and the algorithmic approaches over the years included decision tree learning, inductive logic programming. clustering, reinforcement learning, and Bayesian networks among others. As we know, none achieved the ultimate goal of General AI, and even Narrow AI was mostly out of reach with early machine learning approaches.
As it turned out, one of the very best application areas for machine learning for many years was computer vision, though it still required a great deal of hand-coding to get the job done. People would go in and write hand-coded classifiers like edge detection filters so the program could identify where an object started and stopped; shape detection to determine if it had eight sides; a classifier to recognize the letters “S-T-O-P.” From all those hand-coded classifiers they would develop algorithms to make sense of the image and “learn” to determine whether it was a stop sign.
Good, but not mind-bendingly great. Especially on a foggy day when the sign isn’t perfectly visible, or a tree obscures part of it. There’s a reason computer vision and image detection didn’t come close to rivaling humans until very recently, it was too brittle and too prone to error.
Time, and the right learning algorithms made all the difference.
Deep Learning — A Technique for Implementing Machine Learning
Another algorithmic approach from the early machine-learning crowd, Artificial Neural Networks, came and mostly went over the decades. Neural Networks are inspired by our understanding of the biology of our brains – all those interconnections between the neurons. But, unlike a biological brain where any neuron can connect to any other neuron within a certain physical distance, these artificial neural networks have discrete layers, connections, and directions of data propagation.
You might, for example, take an image, chop it up into a bunch of tiles that are inputted into the first layer of the neural network. In the first layer individual neurons, then passes the data to a second layer. The second layer of neurons does its task, and so on, until the final layer and the final output is produced.
Each neuron assigns a weighting to its input — how correct or incorrect it is relative to the task being performed. The final output is then determined by the total of those weightings. So think of our stop sign example. Attributes of a stop sign image are chopped up and “examined” by the neurons — its octogonal shape, its fire-engine red color, its distinctive letters, its traffic-sign size, and its motion or lack thereof. The neural network’s task is to conclude whether this is a stop sign or not. It comes up with a “probability vector,” really a highly educated guess, based on the weighting. In our example the system might be 86% confident the image is a stop sign, 7% confident it’s a speed limit sign, and 5% it’s a kite stuck in a tree ,and so on — and the network architecture then tells the neural network whether it is right or not.
Even this example is getting ahead of itself, because until recently neural networks were all but shunned by the AI research community. They had been around since the earliest days of AI, and had produced very little in the way of “intelligence.” The problem was even the most basic neural networks were very computationally intensive, it just wasn’t a practical approach. Still, a small heretical research group led by Geoffrey Hinton at the University of Toronto kept at it, finally parallelizing the algorithms for supercomputers to run and proving the concept, but it wasn’t until GPUs were deployed in the effort that the promise was realized.
If we go back again to our stop sign example, chances are very good that as the network is getting tuned or “trained” it’s coming up with wrong answers — a lot. What it needs is training. It needs to see hundreds of thousands, even millions of images, until the weightings of the neuron inputs are tuned so precisely that it gets the answer right practically every time — fog or no fog, sun or rain. It’s at that point that the neural network has taught itself what a stop sign looks like; or your mother’s face in the case of Facebook; or a cat, which is what Andrew Ng did in 2012 at Google.
Ng’s breakthrough was to take these neural networks, and essentially make them huge, increase the layers and the neurons, and then run massive amounts of data through the system to train it. In Ng’s case it was images from 10 million YouTube videos. Ng put the “deep” in deep learning, which describes all the layers in these neural networks.
Today, image recognition by machines trained via deep learning in some scenarios is better than humans, and that ranges from cats to identifying indicators for cancer in blood and tumors in MRI scans. Google’s AlphaGo learned the game, and trained for its Go match — it tuned its neural network — by playing against itself over and over and over.
Thanks to Deep Learning, AI Has a Bright Future
Deep Learning has enabled many practical applications of Machine Learning and by extension the overall field of AI. Deep Learning breaks down tasks in ways that makes all kinds of machine assists seem possible, even likely. Driverless cars, better preventive healthcare, even better movie recommendations, are all here today or on the horizon. AI is the present and the future. With Deep Learning’s help, AI may even get to that science fiction state we’ve so long imagined. You have a C-3PO, I’ll take it. You can keep your Terminator.
First, software ate the world, the web ate software, and JavaScript ate the web. In 2018, React is eating JavaScript.
2018: The Year of React
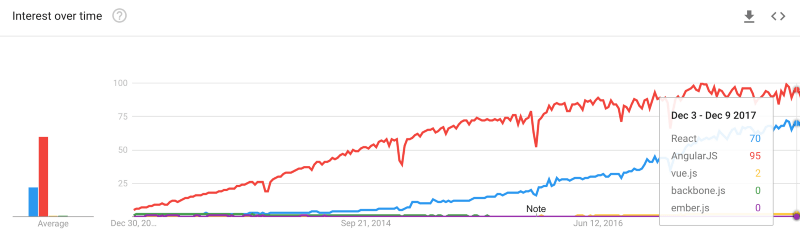
React won the popularity battle in 2017.
There are still lots of developers working on Angular code bases, which shows up in Google trends:
But as React continues to win customer satisfaction surveys, React growth has left Angular (and everything else) in the dust.
What About Vue.js? I Heard it’s Hot
Everybody loves paying lip service to alternatives like Vue.js. Here’s what I said about it last year:
Vue.js has a ton of GitHub stars and downloads. If things continue the way they are going, it will do very well in 2017, but I don’t think it will unseat either React or Angular (both of which are also growing fast) in the next year or so. Learn this after you have learned React or Angular.
Vue.js did do very well in 2017. It got a lot of headlines and a lot of people got interested. As I predicted, it did not come close to unseating React, and I’m confident to predict it won’t unseat React in 2018, either. That said, it could overtake Angular in 2018:
Vue.js downloads/month
As you can see, Vue.js is gaining on Angular downloads:
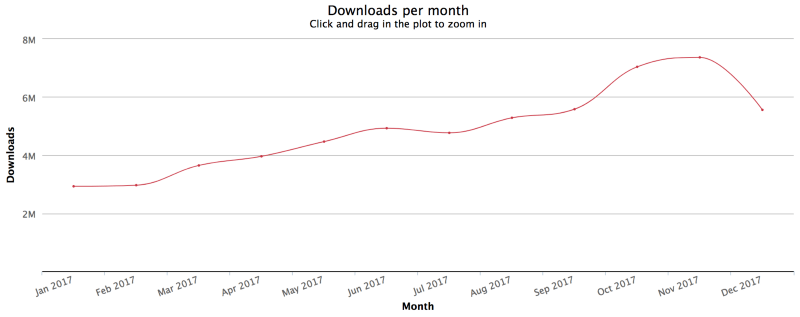
angular/core downloads/month
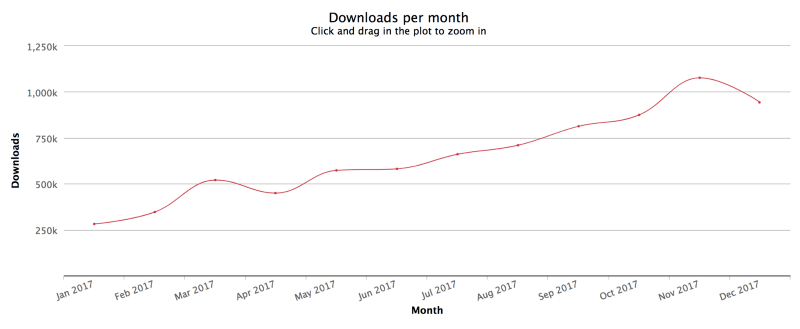
But React has a strong lead and a strong growth rate to match:
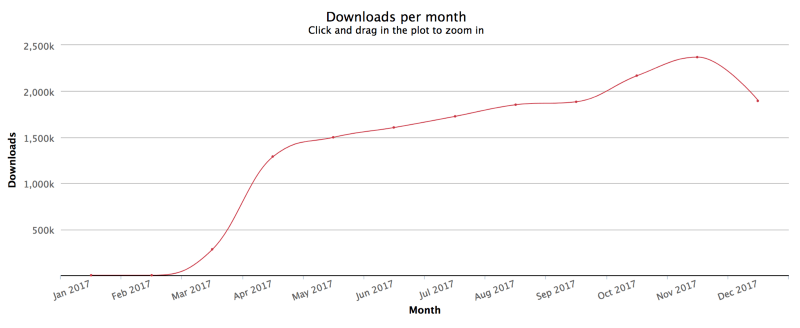
React downloads/month
Vue.js is still growing faster than React. Why should it be any different than React vs Angular in 2017?
At the end of 2016, the JavaScript world was ready for a new framework. Angular users were very unsatisfied, React users were very satisfied, lots of people wanted to learn React, and very few wanted to learn Angular. At the end of 2017, Angular 2+ user satisfaction is still less than half, at 49%.
The story is very different for React vs Vue.js.React is beating Vue.js in user satisfaction (93% to 90%). The big incentive to switch from React in early 2017 was because of confusion over the React license. Facebook heard the users and switched the license.
At this stage, I simply don’t see compelling evidence that the market is motivated to switch from React to anything else. Vue.js is going to have a much harder time stealing users from React than they are having stealing users from jQuery and Angular.
There’s plenty of room for Vue.js to pick up a lot of Angular and jQuery users at a fast clip, but they will likely hit a brick wall when they have to start stealing users from React to continue the growth streak.
I predict strong Vue.js growth for another year or two, followed by a much harder battle with React in the top spot and Vue.js relegated to second fiddle unless something big changes to upset the balance.
Jobs
jQuery has fallen.
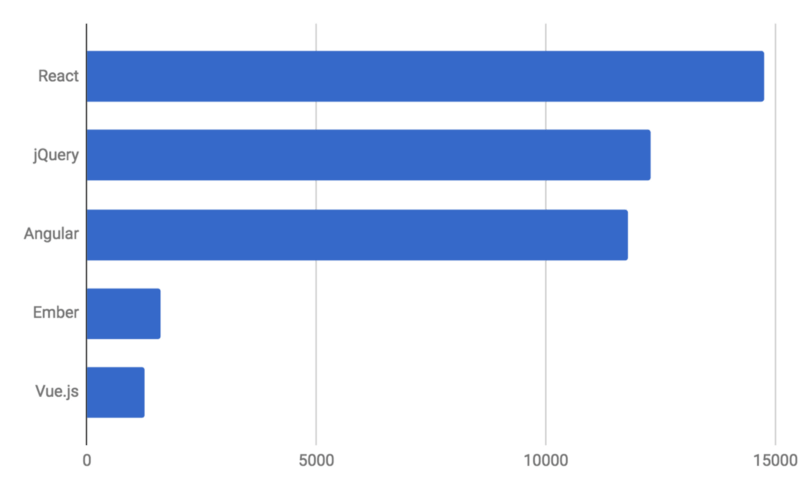
In the job listings, React completely took off and blew right past jQuery — the first library to pass jQuery in job popularity in a decade.¹ What we’re witnessing here is the end of an era.
React Rising — the first library to unseat jQuery this decade (source: Indeed.com)
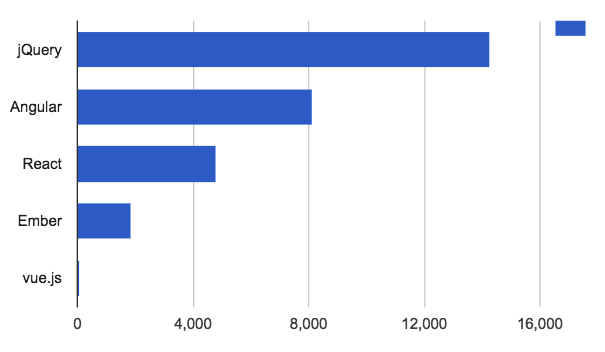
Compare to last year’s chart:
jQuery is so 2016
What’s really interesting in these charts is that other libraries grew a lot more than jQuery fell. The total open jobs mentioning a front-end framework are up by more than ~10k over last year.
With the job growth, we have also seen a boost in average salaries, too: $110k compared to $93k at the end of 2016. The inflation rate for the same period stayed below 2%, accounting for only a small percentage of the salary boost.
Clearly, it’s still a candidate’s market in 2018.
1. Methodology: Job searches were conducted on Indeed.com. To weed out false positives, I paired searches with the keyword “software” to strengthen the chance of relevance, and then multiplied by ~1.5 (roughly the difference between programming job listings that use the word “software” and those that don’t.) All SERPS were sorted by date and spot checked for relevance. The resulting figures aren’t 100% accurate, but they’re good enough for the relative approximations used in this article.
Framework Recommendations
After looking at this year’s numbers, I’m prepared to strongly recommend React for most general app development use cases, including mobile apps (PWAs, React Native), web applications, most office productivity applications, and desktop media content production apps (see Electron).
Notable category exceptions where something else may serve you better: Featherweight marketing landing pages (skip the framework entirely), 3D games, AR/VR. For 3D content, check out Unity, Unreal, or PlayCanvas. That said, React is being used for 3D content UIs, too.
I’m rating all other front-end frameworks strictly optional this year. This doesn’t mean they’re not cool, just not serious contenders to React in the job market. Remember, this list is about learning ROI, not which tech is the “best”.
Why so Much Interest in React?
Browsing through the React job listings, I noticed an interesting trend — a lot of them were for things that we don’t think of as front-end web work:
React Native (for perspective, there are more of these openings than the total number of Vue.js openings)
React for IoT
React for AR/VR (with Oculus Rift leading the hiring charge)
React for obscure computing thing you’ve never heard of
React has broken free of its web roots.
Versatility is one of the big selling points of React. Unlike many other frameworks, buying into React doesn’t entail buying into some baked in data model, or even the browser or DOM itself. In fact, I found quite a few React job listings that didn’t even mention JavaScript.
React also offers a rich, vibrant ecosystem piggybacking on React’s de-facto standards — something the JavaScript world hasn’t seen since jQuery plugins ruled the web.
The question is no longer “which framework?”
The question is “which tech pairs best with React?”
Nothing is going to unseat React in 2018 (maybe even 2019). You’re safe. JavaScript fatigue seems to be settling down. We have a great framework to build apps on now, and there’s a great ecosystem settling in around React.
Which Topics Should You Study?
Like last year, you can’t go wrong focusing on the essentials, but you should place more emphasis on functional programming for React apps.
React is great for two primary reasons:
Deterministic view renders
Abstracting the view layer away from direct DOM manipulation
Determinism is best served by building applications using pure functions, which is essentially the definition of functional programming.
With that in mind, here are some topics you should study:
Class syntax and its many pitfalls — It’s OK to use class for React components, but avoid extending from your own classes, avoid instanceof, and avoid forcing users of your classes to use the new keyword.
GraphQL matured a lot in 2017, and is quickly taking over from REST APIs. Apollo is adding built-in offline first client cache architecture that will make Apollo+GraphQL a serious alternative (or complement) to Redux in 2018.
Libraries & Tools
These are the libraries and tools I’m finding most useful:
RxJS: Observables for JavaScript. I’ve been using transducers more, lately. Remember to use pipeable operators to avoid blowing up your bundle size.
TypeScript did well in 2017, but I’ve seen it get in the way and complicate apps more than it helped. It’s primary shortcomings are over reliance on annotations as opposed to inference, and an inability to properly type higher-order functions without indescribable contortions. I gave it a full-time daily trial for a while, but these still apply: “The Shocking Secret About Static Types” &“You Might Not Need TypeScript”. Flow shares the same problems and the developer tools are not as good as TypeScript’s.
Tech to Watch in 2018
All of these areas of R&D are creating real jobs in 2018:
Progressive Web Apps (PWAs)
Blockchain & fintech
Medical technology
AR/VR — Hololens, Meta, and ODG are shipping today. ODG R-9 was scheduled to ship in 2017 but will likely ship in 2018 instead. MagicLeap has promised to ship in 2018. AR will transform the human experience more than the cell phone did.
3D printing
AI
Drones
Quantum computing is also poised to transform the world, but it may be 2019 or later before the disruption really starts. There are working quantum computers online, but they can’t do much yet. It’s still too early for most developers to even begin to experiment productively. Microsoft recently announced its Q# programming language for quantum computing. Meanwhile, IBM and Google also continue to invest heavily to own the embryonic cloud quantum computing market.
If you want to be prepared to learn quantum computing, you’ll want to study up on linear algebra. There are also functional explorations of quantum computing based on lambda calculus.
It’s likely that, as we’ve seen with AI, cloud APIs will be developed that will let people with less math background take advantage of some of the capabilities of quantum computing.
I have written several books that use Python to explain topics like Bayesian Statistics and Digital Signal Processing. Along with the books, I provide code that readers can download from GitHub. In order to work with this code, readers have to know some Python, but that’s not enough. They also need a computer with Python and its supporting libraries, they have to know how to download code from GitHub, and then they have to know how to run the code they downloaded.
And that’s where a lot of readers get into trouble.
Some of them send me email. They often express frustration, because they are trying to learn Python, or Bayesian Statistics, or Digital Signal Processing. They are not interested in installing software, cloning repositories, or setting the Python search path!
I am very sympathetic to these reactions. And in one sense, their frustration is completely justified: it should not be as hard as it is to download a program and run it.
But sometimes their frustration is misdirected. Sometimes they blame Python, and sometimes they blame me. And that’s not entirely fair.
Let me explain what I think the problems are, and then I’ll suggest some solutions (or maybe just workarounds).
The fundamental problem is that the barrier between using a computer and programming a computer is getting higher.
When I got a Commodore 64 (in 1982, I think) this barrier was non-existent. When you turned on the computer, it loaded and ran a software development environment (SDE). In order to do anything, you had to type at least one line of code, even if all it did was another program (like Archon).
Since then, three changes have made it incrementally harder for users to become programmers
1) Computer retailers stopped installing development environments by default. As a result, anyone learning to program has to start by installing an SDE — and that’s a bigger barrier than you might expect. Many users have never installed anything, don’t know how to, or might not be allowed to. Installing software is easier now than it used to be, but it is still error prone and can be frustrating. If someone just wants to learn to program, they shouldn’t have to learn system administration first.
2) User interfaces shifted from command-line interfaces (CLIs) to graphical user interfaces (GUIs). GUIs are generally easier to use, but they hide information from users about what’s really happening. When users really don’t need to know, hiding information can be a good thing. The problem is that GUIs hide a lot of information programmers need to know. So when a user decides to become a programmer, they are suddenly confronted with all the information that’s been hidden from them. If someone just wants to learn to program, they shouldn’t have to learn operating system concepts first.
3) Cloud computing has taken information hiding to a whole new level. People using web applications often have only a vague idea of where their data is stored and what applications they can use to access it. Many users, especially on mobile devices, don’t distinguish between operating systems, applications, web browsers, and web applications. When they upload and download data, they are often confused about where is it coming from and where it is going. When they install something, they are often confused about what is being installed where.
For someone who grew up with a Commodore 64, learning to program was hard enough. For someone growing up with a cloud-connected mobile device, it is much harder.
Well, what can we do about that? Here are a few options (which I have given clever names):
1) Back to the future: One option is to create computers, like my Commodore 64, that break down the barrier between using and programming a computer. Part of the motivation for the Raspberry Pi, according to Eben Upton, is to re-create the kind of environment that turns users into programmers.
2) Face the pain: Another option is to teach students how to set up and use a software development environment before they start programming (or at the same time).
3) Delay the pain: A third option is to use cloud resources to let students start programming right away, and postpone creating their own environments.
In one of my classes, we face the pain; students learn to use the UNIX command line interface at the same time they are learning C. But the students in that class already know how to program, and they have live instructors to help out.
For beginners, and especially for people working on their own, I recommend delaying the pain. Here are some of the tools I have used:
2) Entire development environments that run in a browser, like PythonAnywhere; and
3) Virtual machines that contain complete development environments, which users can download and run (providing that they have, or can install, the software that runs the virtual machine).
4) Services like Binder that run development environments on remote servers, allowing users to connect using browsers.
On various projects of mine, I have used all of these tools. In addition to the interactive version of “How To Think…“, there is also this interactive version of Think Java, adapted and hosted by Trinket.
I have used virtual machines for some of my classes in the past, but recently I have used more online services, like this notebook from Think DSP, hosted by O’Reilly Media. And the repositories for all of my books are set up to run under Binder.
These options help people get started, but they have limitations. Sooner or later, students will want or need to install a development environment on their own computers. But if we separate learning to program from learning to install software, their chances of success are higher.
UPDATE: Nick Coghlan suggests a fourth option, which I might call Embrace the Future: Maybe beginners can start with cloud-based development environments, and stay there.
UPDATE: Thank you for all the great comments! My general policy is that I will publish a comment if it is on topic, coherent, and civil. I might not publish a comment if it seems too much like an ad for a product or service. If you submitted a comment and I did not publish it, please consider submitting a revision. I really appreciate the wide range of opinion in the comments so far.