开源日报 每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,坚持阅读《开源日报》,保持每日学习的好习惯。
今日推荐开源项目:《云场景操作系统 TencetOS Server kernel》
今日推荐英文原文:《Well-Intentioned but Bad Advice for Beginner Programmers》

今日推荐开源项目《云场景操作系统 TencetOS Server kernel》:传送门:
GitHub链接
推荐理由:TencentOS Server( 又名Tencent Linux 简称Tlinux) 是腾讯针对云的场景研发的 Linux 操作系统,提供了专门的功能特性和性能优化,为云服务器实例中的应用程序提供高性能,且更加安全可靠的运行环境。Tencent Linux 使用免费,在 CentOS(及发行版)上开发的应用程序可直接在 Tencent Linux 上运行,用户还可持续获得腾讯云的更新维护和技术支持。
今日推荐英文原文:《Well-Intentioned but Bad Advice for Beginner Programmers》作者:Ray Heberer
原文链接:
https://medium.com/better-programming/well-intentioned-but-bad-advice-for-beginner-programmers-dc806edd20bd
推荐理由:对于程序员到底应该告诉新人什么呢?作者尝试从另外的角度看待已经成为传统的词语,指出了数个虽然善意却不太好的建议。
Well-Intentioned but Bad Advice for Beginner Programmers

(Photo by Riccardo Annandale on Unsplash)
I bet you didn’t wake up today expecting to be advised to reinvent the wheel.
These days, the internet is chock full of articles containing well-meaning tips directed toward aspiring programmers. Many of these articles contain solid advice, but many also carry pernicious statements that can be harmful to a beginner’s growth.
Often, it isn’t so much that the advice is generally bad or patently untrue; those giving it are smart and experienced enough not to commit such blatant errors. Rather, it’s the fact that the authors are experienced that leads them to present seemingly sound information in a way that may not be interpreted by a beginner in the way they would expect or hope. In my view, well-intentioned bad advice often has the following characteristics:
- It’s good advice for a professional’s day-to-day work, but it’s bad advice for someone learning.
- It’s based on truth, but it can be interpreted in a way that damages growth.
In this article, I’ll examine three pieces of advice I often see directed at beginner programmers (whether they want to be software engineers, data scientists, developers, etc.) and explain why I believe them to be dangerous. At the end of the day, what follows is my personal opinion. So, if you get anything out of this, I would prefer it to be the importance of approaching things with a healthily skeptical attitude rather than to not listen to some particular piece of conventional wisdom.
“Don’t Reinvent the Wheel”
You may have heard that good software engineers are productively lazy people. They automate processes that get repetitive, putting in work (but not too much work) now to avoid more later. They also reuse existing solutions that they or others have made in order to make solving new problems easier. Reusing existing solutions instead of building them from scratch every time is also known as “not reinventing the wheel.”
While avoiding unnecessary reinventions is good practice, I also don’t think it’s a practice that really needs to be shared as one of the main pieces of advice for beginners. In fact, I even think there are ways in which doing so can do more harm than good.
The first reason is related to the fact that our needs are different when we’re learning something new compared to when we’re using skills we already have. If you’re being paid to write a certain kind of code, then it’s certainly efficient and worthwhile to not spend too much time mucking around reimplementing solutions to linear algebra problems that have been around since the Vietnam War. But if your objective is to learn and grow, then you should be wary about passing up valuable opportunities to challenge yourself. Inventing wheels is surprisingly difficult. The fact that many solutions seem obvious in hindsight may mask the amount of value that can be gained by tackling a problem that others have solved.
Also, being too reluctant to get your hands dirty can be harmful long-term, even once you’ve landed the job. I fear that all the emphasis on not doing work others have already done, and focusing instead on honing search engine skills, is encouraging the bad practice of copying solutions from the internet without fully understanding what they do. This incurs technical debt every time it’s done, and it could end up seriously costing your organization.
Don’t get me wrong; I find myself typing into Google many times a day. But I almost never copy what I find. Usually, what I’m looking for is an approach to solving a general problem that can be adapted to my specific issue. This issue is typically too use-case specific to expect a perfect slot-in solution for.
Honestly, I’m good at looking things up, but those skills were acquired quickly and easily by reading a few cheat sheets. What allows me to gain value from non-exact solutions I find, and not get stuck even when nothing useful can be found, are the thousands of hours I spent building things from scratch when I didn’t need to.
Taking a crack at the problems you come across while learning programming — even if you know a solution exists that will almost certainly be more optimized and elegant than what you come up with — builds a sort of creativity and problem-solving intuition that’s hard to gain by just pushing toward the product (e.g. a portfolio project) at any cost.
“Don’t reinvent the wheel” is good advice for professionals, but it’s bad advice for learners.
“There’s No Such Thing as Bug-Free Software”
Before I get started, I’d like to say that I do recognize that some people very much need to hear phrases such as this, and there’s an intended audience for advice like this. It’s just like how a professor saying, “there’s no such thing as a stupid question,” is good for the perceptive yet shy students in the classroom, but bad for certain other students who simply like the sound of their own voice. I’ll expand on this general idea a little when I wrap up, but for now, I’ll focus on identifying the signs that someone is interpreting well-meaning advice in a way that hurts them.
Let’s first determine what one should take away from statements about the impossibility of bug-free software. For one, it should encourage a resilient attitude while learning, where one is not discouraged the moment something doesn’t work as intended. And in terms of a mindset that can be useful throughout a career, I think maxims like the above can encourage a healthy respect for the intellectual challenge of programming. One that leads to increased diligence in writing more unit tests and developing an intuition for the sort of bugs that can occur.
Now, what would I consider an unhealthy response? In my view, there are both productive and unproductive forms of humility. Humility that takes a form like, “it’s possible I made a mistake so I should take steps to safeguard against that” is productive. On the other hand, humility like, “there’s no such thing as bug-free software anyway, so why bother today when I’ll just have to fix things tomorrow no matter what” is unproductive.
When juxtaposed like that, it might seem like no one in their right mind would be unproductively humble. But be honest. Have you ever taken a class that had a reputation for being difficult, where because it was acceptable to struggle, people were fine with finishing the semester not understanding things? I think many of us — myself included — are more tempted to let difficulty encourage complacency than we think. For this reason, I think advice like “don’t expect to ever write bug-free software” can be interpreted in a way we don’t intend.
The ubiquity of bugs in code is less like a law of motion, and more like the second law of thermodynamics. By that I mean it’s more of a tendency than a physical guarantee. And it’s a tendency that can be mitigated by applying a little of our own energy.
Together, let’s think of a way to encourage people to respect the intellectual endeavour of programming without resigning themselves to striving for less than perfection — even if perfection may never be achieved.
“Premature Optimization Is the Root of All Evil”
Now, what would I have against the words of eminent and historically important computer scientist Donald Knuth? Surely I don’t disagree with him?
That’s right, I don’t disagree. What I do object to is passing on this one quote, out of context, to people who are still in the early stages of learning to code. Even aside from it being taken out of context, two basic questions stand out that more experienced engineers often forget to even address:
- What is meant by “optimization?”
- What is meant by “premature?”
To start, let’s get the paragraph that the line comes from. You should still read the full source, but I feel this is already an improvement.
“There is no doubt that the grail of efficiency leads to abuse. Programmers waste enormous amounts of time thinking about, or worrying about, the speed of noncritical parts of their programs, and these attempts at efficiency actually have a strong negative impact when debugging and maintenance are considered. We should forget about small efficiencies, say about 97 % of the time: pre mature optimization is the root of all evil.”
Already, this tells us a bit about what is meant by optimization. When writing code, some things to consider are:
- How much time does it take to run?
- How much memory does it require?
- How easy is it for a human to understand?
- How easily could the code be used to solve another problem somewhere else?
The first two points are related to how the software interacts with the machine (computational complexity). They most closely fit what Donald Knuth is referring to as optimization in his famous phrase. The third, however, relates to how the code interacts with other humans (including you, the author of the code, in a couple of weeks).
Making adjustments to code that make it easier to read and interpret is often worthwhile, and — I would argue — almost never premature. It’s definitely possible to write legible code from the start without wasting your own time. Remember, Donald Knuth is also the man behind the concept of Literate Programming!
As for making code more adaptable for use in other places, this is also something that can often be done without wasting time. Not from the beginning, but also not never.
Finally, one must realize that there does come a time to optimize the code’s actual performance. This can be when the scope of the problem is understood and a full prototype has been implemented.
“Premature” doesn’t apply at all times, and “optimization” doesn’t refer to all possible types of improvements.
I fear that beginner programmers might not have the context necessary to understand this. They may learn to take the principle of “move fast, break things” to its extreme in a way that’s ultimately inefficient and frustrating.
Conclusion
I hope that while reading this article, it became clear that I’m in no way pointing fingers at the experienced programmers among us who have said or written down advice like the three topics I covered. I’m not even saying they should necessarily stop.
What I do hope has been made clear is that communication, and especially communication across skill gaps, is a dynamic and difficult process. It’s hard to predict the outcome of giving advice — it depends on where the recipient is coming from and even on the frequency with which similar things have been said by others.
Many of us genuinely want to help others, and it warms my heart to see so many people out there sharing their knowledge, often more effectively than I’m currently capable of. What I wanted to achieve with this was another perspective on a few phrases that seem to have become conventional wisdom. I urge my fellow engineers to recognize that when something becomes conventional wisdom, it can be easy for us to forget to communicate the surrounding context needed to truly understand it.
And I urge my fellow learners to strive to find the most productive way to interpret every piece of information you come across. Happy coding. You’ve got this!
Resources
- The Curse of Knowledge — Wikipedia
- Project Euler: a great place to reinvent wheels
- Hindsight Bias — Wikipedia
- Structured Programming with go to Statements — Donald Knuth
- Literate Programming
下载开源日报APP:
https://opensourcedaily.org/2579/
加入我们:
https://opensourcedaily.org/about/join/
关注我们:
https://opensourcedaily.org/about/love/

 Caption: Not all data is created equal. Example of a common highway scene (top left) vs. some unusual driving scenarios (top right: cyclist doing a wheelie at night, bottom left: truck towing trailer towing quad, bottom right: pedestrian on jumping stilts).
Caption: Not all data is created equal. Example of a common highway scene (top left) vs. some unusual driving scenarios (top right: cyclist doing a wheelie at night, bottom left: truck towing trailer towing quad, bottom right: pedestrian on jumping stilts).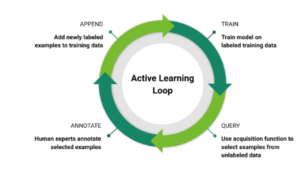 Active learning has already shown it can improve the detection accuracy of self-driving DNNs over manual curation. In our own research, we’ve found that the increase in precision when training with active learning data can be 3x for pedestrian detection and 4.4x for bicycle detection relative to the increase for data selected manually.
Active learning has already shown it can improve the detection accuracy of self-driving DNNs over manual curation. In our own research, we’ve found that the increase in precision when training with active learning data can be 3x for pedestrian detection and 4.4x for bicycle detection relative to the increase for data selected manually.
