每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;电报群 t.me/openingsource
今日推荐开源项目:《基于H5 Canvas的交互框架——Konva》;GitHub地址
推荐理由:Knova.js 是一个基于HTML5 Canvas 的JavaScript 框架,可以实现高性能的动画,转换,节点嵌套,分层,过滤,缓存,时间处理等等,并且具有良好的响应式布局,可以同时支持电脑桌面和移动应用。
在使用Knova时,可以在Knova.Stage上开始绘制,为它们添加事件监听器,移动它们,缩放它们,即使您的应用程序使用了数千种形状,并将它们从其他形状中独立出来以支持高性能的动画。
实现方式
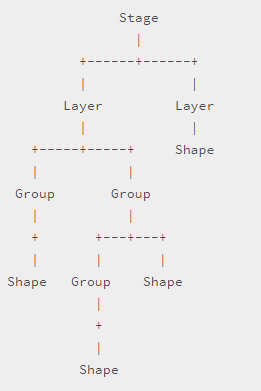
所有工作都从Konva.Stage开始,每个stage可以包含多个图层,而每个图层则包含两个canvas渲染器,其中一个是我们所看见的,另一个隐藏,用来提高实现事件监听的效率。
使用示例
<script src="https://cdn.rawgit.com/konvajs/konva/1.7.3/konva.min.js"></script>
<div id="container"></div>
<script>
//首先创建一个stage
var stage = new Konva.Stage({
container: 'container',
width: window.innerWidth,
height: window.innerHeight
});
// 创建图层并添加到stage中
var layer = new Konva.Layer();
stage.add(layer);
// 创建图形
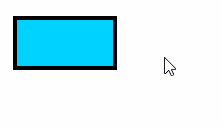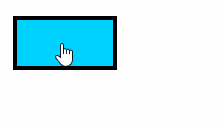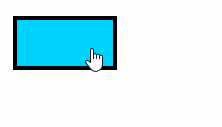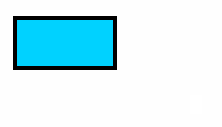
var box = new Konva.Rect({
x: 50,
y: 50,
width: 100,
height: 50,
fill: '#00D2FF',
stroke: 'black',
strokeWidth: 4,
draggable: true
});
//将图像添加到图层
layer.add(box);
//绘图
layer.draw();
// 添加光标的效果
box.on('mouseover', function() {
document.body.style.cursor = 'pointer';
});
box.on('mouseout', function() {
document.body.style.cursor = 'default';
});
</script>
效果演示
加载和安装
Konva支持UMD加载。因此,您可以使用所有可能的变体将框架加载到您的项目中:
- 通过<script>标签来加载Konva:
<script src ="https://cdn.rawgit.com/konvajs/konva/1.7.3/konva.min.js"> </ script >
2. 通过AMD加载:
define(['./konva'], function(Konva) { // your code});
3. 通过npm:
npm install konva --save
导入代码
// old way
var Konva = require('konva');
// modern way
import Konva from 'konva';
// typescript
import * as Konva from 'konva';
4. 如果您使用的是webpack或browserfy,则可以使用此方法仅加载所需的Konva零件:
import Konva from 'konva/src/Core'; // now you have Konva object with Stage, Layer, FastLayer, Group, Shape and some additional utils function // so there are no shapes (rect, circle, etc), no filters, no d&d support. // but you can simply add anything you need: import 'konva/src/shapes/rect'; //now Konva.Rect is available to use
了解更多欢迎进入官方演示站:
今日推荐英文原文:《What is open source programming?》
推荐理由:很多时候我们都在说开源软件,但是什么叫开源呢?把源代码放在 GitHub 上就叫开源了吗?恐怕不是,那么,一起来听听看,什么是开源?什么不是开源?
What is open source programming?
At the simplest level, open source programming is merely writing code that other people can freely use and modify. But you’ve heard the old chestnut about playing Go, right? “So simple it only takes a minute to learn the rules, but so complex it requires a lifetime to master.” Writing open source code is a pretty similar experience. It’s easy to chuck a few lines of code up on GitHub, Bitbucket, SourceForge, or your own blog or site. But doing it right requires some personal investment, effort, and forethought.
What open source programming isn’t
Let’s be clear up front about something: Just being on GitHub in a public repo does not make your code open source. Copyright in nearly all countries attaches automatically when a work is fixed in a medium, without need for any action by the author. For any code that has not been licensed by the author, it is only the author who can exercise the rights associated with copyright ownership. Unlicensed code—no matter how publicly accessible—is a ticking time bomb for anyone who is unwise enough to use it.

A well-meaning author may think, “well, it’s obvious this is free to use,” and have no plans ever to sue anyone, but that doesn’t mean the code is safe to use. No matter what you think someone will do, that author has the right to sue anyone who uses, modifies, or embeds that code anywhere else without an expressly granted license.Clearly, you shouldn’t put your own code out in public without a license and expect others to use or contribute to it. I would also recommend you avoid using (or even looking at) such code yourself. If you create a highly similar function or routine to a piece of unlicensed work you inspected at some point in the past, you could open yourself or your employer to infringement lawsuits.
Let’s say that Jill Schmill writes AwesomeLib and puts it on GitHub without a license. Even if Jill never sues anybody, she might eventually sell all the rights to AwesomeLib to EvilCorp, who will. (Think of it as a lurking vulnerability, just waiting to be exploited.)
Unlicensed code is unsafe code, period.
Choosing the right license
OK, you’ve decided you want to write a new program, and you want people to have open source rights to use it. The next step is figuring out which license best fits your needs. You can get started with the GitHub-curated choosealicense.com, which is just what it says on the tin. The site is laid out a bit like a simple quiz, and most people should be one or two clicks at most from finding the right license for their project.
A word of caution: Don’t get overly fancy or self-important. If you choose a commonly used and well-known license like the Apache License or the GPLv3, it’s easy for people to understand what their rights are and what your rights are without needing a team of lawyers to look for pitfalls and problems. The further you stray from the beaten path, though, the more problems you open yourself and others up to.Most importantly, do not write your own license! Making up your own license is an unnecessary source of confusion for everyone. Don’t do it. If you absolutely must have your own special terms that you can’t find in any existing license, write them as an addendum to an otherwise well-understood license… and keep the main license and your addendum clearly separated so everyone involved knows which parts they’ve got to be extra careful about.
I know some people stubborn up and say, “I don’t care about licenses and don’t want to think about them; it’s public domain.” The problem with that is that “public domain” isn’t a universally understood term in a legal sense. It means different things from one country to the next, with different rights and terms attached. In some countries, you can’t even place your own works in the public domain, because the government reserves control over that. Luckily, the Unlicense has you covered. The Unlicense uses as few words as possible to clearly describe what “just make it public domain!” means in a clear and universally enforceable way.
How to apply the license
Once you’ve chosen a license, you need to clearly and unambiguously apply it. If you’re publishing somewhere like GitHub or GitLab or BitBucket, you’ll have what amounts to a folder structure for your project’s files. In the root folder of your project, you should have a plaintext file called LICENSE.txt that contains the text of the license you selected.
Putting LICENSE.txt in the root folder of your project isn’t quite the last step—you also need a comment block declaring the license at the header of each significant file in your project. This is one of those times where it comes in handy to be using a well-established license. A comment that says: # this work (c)2018 myname, licensed GPLv3—see https://www.gnu.org/licenses/gpl-3.0.en.html is much, much stronger and more useful than a comment block that merely makes a cryptic reference to a completely custom license.
If you’re self-publishing your code on your own site, you’ll want to follow basically the same process. Have a LICENSE.txt, put the full copy of your license in it, and link to your license in an abbreviated comment block at the head of each significant file.
Open source code is different
A big difference between proprietary and open source code is that open source code is meant to be seen. As a 40-something sysadmin, I’ve written a lot of code. Most of it has been effectively proprietary—I started out writing code for myself to make my own jobs easier and scratch my own and/or my company’s itches. The goal of such code is simple: All it has to do is work, in the exact way and under the exact circumstance its creator planned. As long as the thing you expected to happen when you invoked the program happens more frequently than not, it’s a success.
Open source code is very different. When you write open source code, you know that it not only has to work, it has to work in situations you never dreamed of and may not have planned for. Maybe you only had one very narrow use case for your code and invoked it in exactly the same way every time. The people you share it with, though… they’ll expose use cases, mixtures of arguments, and just plain strange thought processes you never considered. Your code doesn’t necessarily have to satisfy all of them—but it at least needs to handle their requests gracefully, and fail in predictable and logical ways when it can’t service them. (For example: “Division by zero on line 583” is not an acceptable response to a failure to supply a command-line argument.)Your open source code also has to avoid unduly embarrassing you. That means that after you struggle and struggle to get a balky function or sub to finally produce the output you expected, you don’t just sigh and move on to the next thing—you clean it up, because you don’t want the rest of the world seeing your obvious house of cards. It means that you stop littering your code with variables like $variable and $lol and replace them with meaningful names like $iterationcounter or $modelname. And it means commenting things professionally (even if they’re obvious to you in the heat of the moment) since you expect other people to be able to follow your code later.
This can be a little painful and frustrating at first—it’s work you’re not accustomed to doing. It makes you a better programmer, though, and it makes your code better as well. Just as important: Even if you’re the only contributor your project ever has, it saves you work in the long run. Trust me, a year from now when you have to revisit your app, you’re going to be very glad that $modelname, which gets parsed by several stunningly opaque regular expressions before getting socked into some other array somewhere, isn’t named $lol anymore.
You’re not writing just for yourself
The true heart of open source isn’t the code at all: it’s the community. Projects with a strong community survive longer and are adopted much more heavily than those that don’t. With that in mind, it’s a good idea not only to embrace but actively plan for the community you hope to build around your project.
Batman might spend hundreds of hours in seclusion furiously building a project in secrecy, but you don’t have to. Take to Twitter, Reddit, or mailing lists relevant to your project’s scope, and announce that you’re thinking of creating a new project. Talk about your design goals and how you plan to achieve them. Request input, listen to similar (but maybe not identical) use cases, and build that information into your process as you write code. You don’t have to accept every suggestion or request—but if you know about them ahead of time, you can avoid pitfalls that require arduous major overhauls later.
This process doesn’t end with the initial announcement. If you want your project to be adopted and used by other people, you need to develop it that way too. This isn’t a barrier to entry; it’s just a pattern to use. So don’t just hunker down privately on your own machine with a text editor—start a real, publicly accessible project at one of the big foundries, and treat it as though the community was already there and watching.
Ways to build a real public project
You can open accounts for open source projects at GitHub, GitLab, or BitBucket for free. Once you’ve opened your account and created a repository for your project, use it—create a README, assign a LICENSE, and push code incrementally as you develop it. This will build the habits you’ll need to work with a real team later as you get accustomed to writing your code in measurable, documented commits with clear goals. The further you go, the more likely you’ll start generating interest—usually in the form of end users first.
The users will start opening tickets, which will both delight and annoy you. You should take those tickets seriously and treat their owners courteously. Some of them will be based on tremendous misunderstandings of what your project is and what is or isn’t within its scope—treat those courteously and professionally, also. In some cases, you’ll guide those users into the fold of what you’re doing. In others, however haltingly, they’ll guide you into realizing the larger—or slightly differently centered—scope you probably should have planned for in the first place.
If you do a good job with the users, eventually fellow developers will show up and take an interest. This will also both delight and annoy you. At first, you’ll probably just get trivial bugfixes. Eventually, you’ll start to get pull requests that would either hardcode really, really niche special use-cases into your project (which would be a nightmare to maintain) or significantly alter the scope or even the focus of your project. You’ll need to learn how to recognize which contributions are which and decide which ones you want to embrace and which you should politely reject.
Why bother with all of this?
If all of this sounds like a lot of work, there’s a good reason: it is. But it’s rewarding work that you can cash in on in plenty of ways. Open source work sharpens your skills in ways you never realized were dull—from writing cleaner, more maintainable code to learning how to communicate well and work as a team. It’s also the best possible resume builder for a working or aspiring professional developer; potential employers can hit your repository and see what you’re capable of, and developers you’ve worked with on community projects may want to bring you in on paying gigs.
Ultimately, working on open source projects—yours or others’—means personal growth, because you’re working on something larger than yourself.
每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;电报群 t.me/openingsource