每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;电报群 https://t.me/OpeningSourceOrg
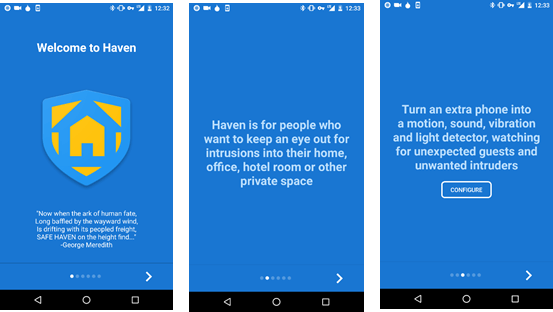
今日推荐开源项目:《捍卫隐私的秘器 Haven》
推荐理由:很多朋友肯定听说过 Haven 的神秘背景,小编就不提了,不过说到需求,你是否曾为找不到有效的保护私人信息的方法而苦恼?是否还在苦苦寻求保护私人空间和信息的方法?如果有的话,Haven将会是一个绝佳的选择!
Haven 是一款Android应用程序,能为那些需要一种方法来保护自己的个人空间和财产,而不损害自己的隐私的人提供的应用。
Haven利用设备上的传感器来提供对物理空间的监视和保护。避风港把任何Android手机变成运动,声音,振动和光检测器,注意意外的客人和不必要的入侵者。并且只在运动或音量触发时才保存图像和声音,并将所有内容存储在设备上。您可以放置设备的摄像头以捕捉可见的动作,或将手机放置在某个谨慎的地方,只听声音。立即获取入侵事件的安全通知,并在以后远程或随时访问日志。
监测下列传感器的可测量变化,然后记录到设备上的事件日志中:
- 加速度计:手机的运动和振动
- 相机:从前置或后置摄像头移动到手机可见的环境中
- 麦克风:环境中的噪音
- 灯光:来自环境光线传感器的光线变化
- 电源:检测到设备被拔出或掉电
当其中一个传感器被触发(达到配置的灵敏度阈值)时,将通过以下通道发送通知(如果启用):
- 短信:当监控开始时,一条消息被发送到指定的号码
- 信号:如果配置,可以通过信号发送端到端的加密通知
相关链接:
Haven 的完整演示文稿: Haven App Overview
安装F-Droid链接:install F-Droid
从GitHub处获取链接:GitHub releases page
今日推荐英文原文:《Resolving Boot Loader Issues》作者:Kshitij Upadhyay
原文链接:https://opensourceforu.com/2018/05/resolving-boot-loader-issues/
推荐理由:大部分朋友在安装 Linux 或者 BSD 等非 Windows 系统时都会遇到 BIOS/UEFI 相关的问题,这里有一个完整的 Boot Loader 问题解决方案来帮你扫请障碍。
Resolving Boot Loader Issues

Boot loader issues often plague computer systems. This article demystifies the booting process, both for BIOS based systems as well as UEFI systems.
A Basic Input Output System (BIOS) powered system goes through a number of steps from when it is powered up to when it runs a Red Hat Enterprise Linux (RHEL) system. The following list of steps gives a high-level overview of what exactly takes place. This list also applies to virtual machines that emulate a traditional BIOS system. The list assumes that the GRUB2 boot loader is being used. For different boot loaders, the list will differ.
1) The BIOS firmware is started and performs a ‘power on self-test’ (POST).
2) The BIOS scans for possible boot devices, and orders them according to a user-set preference.
3) The boot devices are scanned for boot firmware (such as a PXE ROM on network cards), a Master Boot Record (MBR), or a partition marked as bootable. If found, the BIOS executes them.
4) The first-stage boot loader stored in the MBR loads the Stage 1.5 (drivers) and Stage 2 boot loaders from the disk, and executes them.
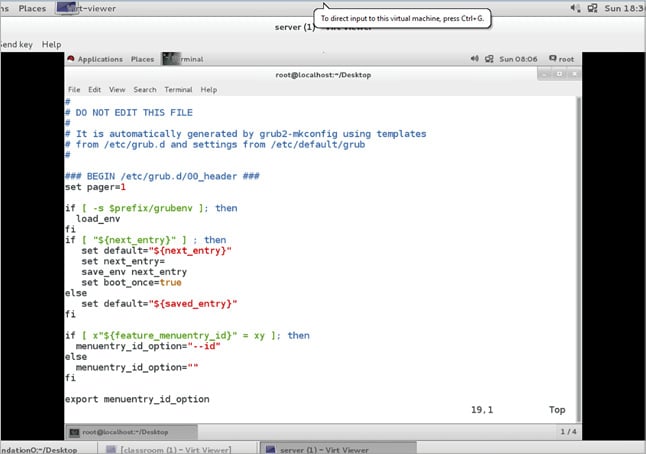
5) The boot loader loads a configuration file from the disk. In the case of GRUB2, this will be /boot/grub2/grub.cfg. The file is shown in Figure 1. This file is auto generated and should not normally be edited manually.
6) The configuration file is parsed and, based on its contents, a boot entry is selected automatically by the user.
7) The kernel and initial RAM disk referenced in the boot entry are loaded from the disk, and control is handed over to the kernel.
8) The kernel starts and initialises hardware using the drivers found in the initial RAM disk. A simple init system is also started from the RAM disk.
9) The scripts in the initial RAM disk mount the root file system of the target system; they then switch the root to the newly mounted file system and hand over control to /sbin/init on the target root file system.
10) The init system mounts file systems and starts services according to its configuration.
GRUB2
The boot loader used on RHEL is GRUB2, the second major version of the GRand Unified Bootloader. GRUB2 stores its files on a BIOS system in a number of different locations, as listed below.
The kernel and initial RAM disks are stored here. Sub-directories contain other files.
This contains the configuration files, extension modules and themes.
This has the main GRUB2 configuration file. This file is auto generated, and should normally not be edited manually. As a convenience, /etc/grub2.cfg is a symbolic link to this file.
This directory contains a helper script to generate a main GRUB2 configuration file.
This file contains variables used in the generation of the main GRUB2 configuration file, as shown in Figure 2.
This contains a file of exactly 1KiB, which is used as storage for variables, such as a default or ‘saved’ boot entry.
The grub2-editenv tool can be used to read and modify these settings. The Master Boot Record (MBR)
The Master Boot Record (MBR)
In order to boot GRUB2 from the disk on a BIOS system, there are two options—store the first part of the GRUB2 boot loader in the Master Boot Record (MBR) of a disk, or store it in the first sector of a partition that is marked as ‘bootable’.
The problem with the MBR
There is a major constraint with using the MBR. A typical MBR is only 512 bytes in size, and part of that space is used for the partition table of that disk, leaving only 446 bytes for the boot loader.
To work around this issue, GRUB2 can use the ‘boot track’, ‘MBR gap’, or ‘embedding area’ on the disk to store the extra modules and files it needs. This is the space between the MBR and the first partition on the disk. In order to work reliably, there needs to be at least 31KiB of space available this way (63 sectors on a 512-byte sector disk). If a disk has been partitioned by Anaconda, the first partition will usually start at sector 2048, leaving roughly 1MiB of space for the embedding area, which is ample room for GRUB2.
Note: The ibi (or binary prefix) units KiB, MiB, GiB are based on 2^10(1024) whereas standard decimal units
(KB, MB, GB) are based on 10^3(1000). In this article, we have used the units KiB, MiB and TiB.
1KB= 1000 bytes 1KiB=1024 bytes
1MB=1000KB 1MiB=1024KB
1GB=1000MB 1GiB=1024MB
1TB=1000GB 1TiB= 024GB
Configuring GRUB2
Under normal circumstances, an administrator should not have to manually configure the GRUB2 boot loader. When a new kernel is installed, it will be added to the configuration automatically and when a kernel is removed, the corresponding entry in the boot loader menu is removed automatically as well.
An administrator might want to tweak some parameters that are passed into the kernel at startup by GRUB2. The best way to do this is by editing /etc/defaults/grub and then forcing a recreation of the main GRUB2 configuration file.
The settings in /etc/defaults/grub that are of interest are listed here.
This is the number of seconds the GRUB2 menu is displayed before the default entry is booted automatically.
This is the number of the default entry that should be started whenever a user does not select another entry, which is when GRUB2 starts counting at 0. If this variable is set to the string saved, the entry will be taken from /boot/grub2/grubenv.
This variable contains a list of extra kernel command-line options that should be added to every single Linux kernel. Typical uses include ‘rhgb quiet’ for a graphical boot, ‘console=xxxxxx’ for selecting a kernel console device, and ‘crashkernel=xxxx’ for configuring automatic kernel crash dumping.
After updating the file /etc/default/grub, changes can be applied by running the command grub2-mkconfig –o /boot/grub2/grub.cfg. This will generate a fresh configuration file using the scripts in /etc/grub.d and the settings in /etc/defaults/grub. If no output file is specified with the –o option, a configuration file will be written to the standard output.
Reinstalling GRUB2 into the MBR
If, for some reason, the MBR, or the embedding area, has become damaged, an administrator will have to reinstall GRUB2 into the MBR. Since this implies that the system is currently unbootable, this is typically done from some live CD or from within the rescue environment provided by the Anaconda installer.
The following procedure explains how to boot into a rescue environment and reinstall GRUB2 into the MBR from there. If an administrator is still logged into a running system, the procedure can be shortened to just the grub-install command.
1. Boot from an installation source; this can be a DVD image, a netboot CD, or from PXE providing a RHEL installation tree.
2. In the boot menu for the installation media, select the ‘Rescue an installed system’ option, or edit the kernel command line to include the word ‘rescue’.
3. When prompted about mounting the disks for the target system to be rescued, select Option 1 (continue). This will mount the system under /mnt/sysimage.
4. Press Enter to obtain a shell when prompted. This shell will live inside the installation/rescue environment, with the target system mounted under /mnt/sysimage.
This shell has a number of tools available for rescuing a system, such as all common file systems, disks, LVMs, and networking tools. The various bin directories of the target system are added to the default executable search path (${PATH}) as well.
5. chroot into the /mnt/sysimage directory, using the following command:
6. Verify that /boot is mounted, using the command given below. Depending on the type of installation, /boot can be on a separate partition, or it can be part of the root file system.
7. Use the command grub2-install to rewrite the boot loader sections of the MBR and the embedding area. This command will need the block device that represents the main disk as an argument. If unsure about the name of the main disk, use lsblk and blkid to identify it.
8. Reboot the system. This can be done by exiting both the chroot shell and the rescue shell.
9. Wait for the system to reboot twice. After the first reboot, the system will perform an extensive SELinux file system relabel, after which it will reboot again automatically to ensure that proper contexts are being used. This relabel is triggered automatically by the Anaconda rescue system creating the /. autorelabel.
Resolving boot loader issues on UEFI systems
What is UEFI?
Introduced in 2005, the Unified Extensible Firmware Interface (UEFI) replaces the older Extensible Firmware Interface (EFI) and the system BIOS. A replacement for the older BIOS was sought to work around the limits that the BIOS imposed, such as 16-bit processor mode and only 1 MiB of addressable space.
UEFI also allows booting from disks larger than 2 TiB, as long as they are partitioned using a GUID Partition Table (GPT).
One of the big differences between UEFI systems and BIOS systems is the way they boot. While in the case of the latter, the BIOS has to search for bootable devices, operating systems can ‘register’ themselves with the UEFI firmware. This makes it easier for end users to select which operating system they want to boot in a multi-boot environment — GRUB2 or UEFI.
GRUB2 and UEFI
In order to boot a UEFI system using GRUB2, an EFI system partition (ESP) needs to be present on the disk. This partition should have a GPT UUID or the MBR type. The partition needs to be formatted with a FAT file system, and should be large enough to hold all bootable kernels and the boot loader itself. A size of 512MiB is recommended, but smaller sizes will work. This partition should be mounted at /boot/efi and will normally be created by the Anaconda installer.
The main GRUB2 difference between BIOS and UEFI
While most of the configuration syntax and tools remain the same between BIOS and UEFI boots, some of the following small changes do apply.
Linux16/initrd16 vs linuxefi/initrdefi
The configuration commands to load a kernel and initial RAM disk switch from linux16 and initrd16 to linuxefi and initrdefi, respectively.
The change is necessary since kernels need to be loaded differently on a UEFI system than on a BIOS system. The grub2-mkconfig command automatically recognises a UEFI system and makes the correct changes.
/boot/grub2 vs /boot/efi/EFI/redhat
On UEFI systems the directory holding all grub2 configuration files and extras is moved to /boot/efi/EFI/redhat. This is a location on the ESP, making it accessible to the UEFI firmware.
grub2-install
While a grub2-install command is more than capable of installing a boot loader onto a UEFI system, it should never be used directly. Calling grub2-install on a UEFI system will generate a new /boot/efi/EFI/redhat/grubx64.efi file. On Red Hat Enterprise Linux 7 systems, this file should be the prebaked version from the grub2-efi-package.
The grub2-install command will also register a bootable target in the UEFI firmware using this updated grubx64.efi application, instead of the shim.efi application.
Warning: Using grub2-install will install a custom grubx64.efi. If a system was set up for a secure boot, this will cause the boot to fail.
/boot/grub2/grub.cfg vs /boot/efi/EFI/redhat/grub.cfg
Included in the move from /boot/grub2 to /boot/efi/EFI/redhat/ is the move of the main GRUB2 configuration file. The symbolic link /etc/grub.cfg is also moved to /etc/grub2-efi.cfg.
Reinstalling GRUB2 on UEFI-based machines
If, for some reason, any of the files needed to boot in /boot/efi have been removed, or if the partition has been recreated, these files can be recovered by reinstalling both the grub2-efi and shim packages, as follows:
If /boot/efi/EFI/redhat/grub.cfg has been removed, it can be restored with the following command:
If the Red Hat entry has been removed from the UEFI boot menu, booting from the disk that has an installation of Red Hat Enterprise Linux 7 will automatically add it back.
The UEFI based chain
In order to work with secure boot systems, where signatures on boot loaders, kernels, etc, can be checked by the firmware to authenticate that only unmodified software is run, Red Hat Enterprise Linux 7 uses the shim UEFI bootloader.
The shim.efi application is signed with a key trusted by most UEFI firmware. When started, it will attempt to load grubx64.efi using the normal UEFI firmware calls. If the UEFI firmware refuses to load the application due to a bad signature, shim will attempt to verify the application using other keys compiled into it, or a user-generated key stored in UEFI NVRAM (machine owner key (MOK)). When attempting to start a signed application for which no keys have been registered, the MokManager.efi application is started automatically so that an end user can register a personal key.
The shim.efi application also registers a new UEFI system call that can be used by GRUB2 to verify kernel signatures.
If shim.efi is not registered with the UEFI firmware, booting from the disk that contains the ESP will launch the /boot/efi/EFI/BOOT/BOOTX64.efi application. This, in turn, will launch the fallback.efi application, which automatically registers the shim.efi application and boots the system, based on the settings in /boot/efi/EFI/redhat/BOOT.CSV.
Early root shell
In some cases, startup tasks can take far longer than anticipated, or even fail to complete after minutes or hours. To help debug these types of problems, the systemctl list-jobs command can show all current jobs that sytemd is executing, allowing an administrator to stop or kill them, or fix the reason these jobs are taking so long.
To obtain a root shell during startup, an administrator can enable the debug-shell.service. This service will start a virtual console with a logged-in root shell attached to it on /dev/tty9, very early during boot—during the startup of the sysinit.target target.
Using this early root shell, an administrator can analyse, debug and sometimes remedy a failing service or unit.
Warning: Do not leave the debug-shell.service service enabled and running after debugging is done. Anyone with console access, either physical or via a management card or KVM switch, will have full, unrestricted root access to the machine.
每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;电报群 https://t.me/OpeningSourceOrg