A look at open source image recognition technology
At the Supercomputing Conference in Denver last year, I discovered an interesting project as I walked the expo floor. A PhD student from Louisiana State University, Shayan Shams, had set up a large monitor displaying a webcam image. Overlaid on the image were colored boxes with labels. As I looked closer, I realized the labels identified objects on a table.
Of course, I had to play with it. As I moved each object on the table, its label followed. I moved some objects that were off-camera into the field of view, and the system identified them too.
When I asked Shams about the project, I was surprised to learn that he did not need to write any code to create it—the entire thing came together from open software and data. Shams used the Common Objects in Context (COCO) dataset for object recognition, reducing unnecessary classes to enable it to run on less powerful hardware. “Detecting some classes, such as airplane, car, bus, truck, and so on in the SC exhibition hall [was] not necessary,” he explained. To do the actual detection, Shams used the You Only Look Once (YOLO) real-time object detection system.
The hardware was the only part of the setup that wasn’t open. Shams used an NVIDIA Jetson TX2 module to run the detection. The TX2 is designed to act as an edge device for AI inference (as opposed to the more computationally intensive AI training). This $300 device allows live video analysis to happen away from central computing resources, which is key to applications like self-driving cars and other scenarios where network latency or bandwidth constraints require compute at the edge.
While this setup makes an interesting demonstration of the capabilities of live image recognition, Shams’ efforts go far beyond simply identifying pens and coffee mugs. Working under LSU professor Seung-Jong Park, Shams is applying his research to the field of biomedical imaging. In one project, he applied deep learning to mammography: By analyzing mammogram images, medical professionals can reduce the number of unnecessary biopsies they perform. This not only lowers medical costs, but it saves patients stress.
Shams is also working on LSU’s SmartCity project, which analyzes real-time data from traffic cameras in Baton Rouge to help detect criminal activities such as robbery and drunk driving. To address ethical considerations, Shams explained that all videos are discarded except those in which abnormal or criminal activity is detected. For these, the video for the specific vehicle or person is time-stamped, encrypted, and saved in a database. Any video the model flags as suspicious is reviewed by two on-site system administrators before being sent to the officials for further investigation.
In the meantime, if you’re interested in experimenting with image-recognition technology, a Raspberry Pi with a webcam is sufficient hardware (although the recognition may not be immediate). The COCO dataset and the YOLO model are freely available. With autonomous vehicles and robots on the horizon, experience with live image recognition will be a valuable skill.
We used to believe many things to be true. We believed the sun orbited the earth. We believed the plague was a punishment from the gods. We believed that Model-View-Controller architectures and two-way data binding were the best ways to structure user interface programs on the web.
All these beliefs were true to those who believed them at the time, as we didn’t yet have better ways to reason about the world.
Eventually, astronomers proved the heliocentric solar system, doctors discovered the microbial theory of disease, and React introduced us to the concept of unidirectional data flow.
None of these discoveries were immediately universally accepted. Galileo was tried for heresy. Dr. Semmelweis, who discovered the germ-based origin of diseases, was driven insane by his peers’ refusal to accept his research and died in an asylum. And still today, we haven’t yet agreed that not all UI architectures are created equal.
I strongly believe that React — or something like it — is the future of user interface development. But before you scroll to the end of the article to post an angry comment (or ? because you happen to agree), let me tell you why.
The forest, not the trees
React is a collection of clever ideas created by extremely clever people. When React was first announced, the selling point people used to talk about was its rendering approach — the idea that if we separate the representation of our application structure from the underlying rendered DOM, we can achieve a declarative view rendering syntax while still applying optimal DOM mutations.
This was paired with other controversial ideas, the main one being the insight that separating code across technology boundaries — HTML, JavaScript and CSS — is not real separation of concerns. In order to create programs with high internal cohesion and low external coupling, we’re better off colocating the presentation, behaviour and state of a piece of UI in a single file in JavaScript. This approach has the unfortunate side effect of making UIs hard to author in plain JavaScript, and thus React shipped with a language syntax extension called JSX.
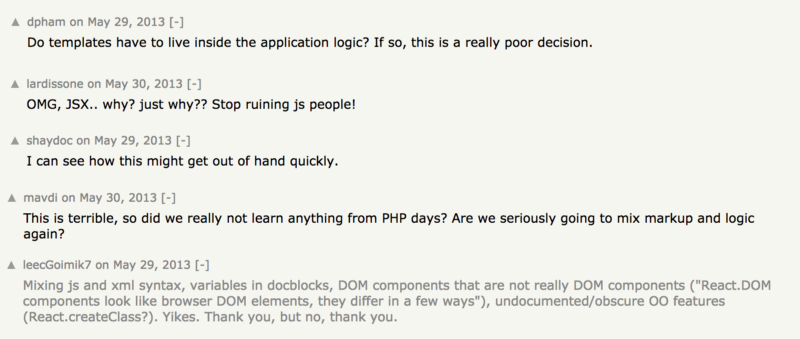
If you’re not a web frontend developer, it’s really hard to understand how anyone can get upset over a language extension, but web is a weird place, and some people sure did.
Premium vintage HN hot takes after React’s announcement
Naturally, nobody likes being told their core beliefs are wrong. And so, among the blowback and the conceptual novelty, the core value of React still often gets forgotten.
React is a Component platform
React, at its core, is all about its components. The Virtual DOM is a cool piece of technology, but it’s only an implementation detail — if React could’ve been created without it, it wouldn’t need to even exist. JSX is a clever hack, but it’s only syntax sugar on top.
By now components are a well-established concept, and they did exist before React. The Web Components specification was already standardised when React was released. Much like Galileo wasn’t the first to discover heliocentricity, React didn’t invent components — it just found the right recipe for them.
React components are all about their composability and encapsulation. In addition, they benefit from being functional and multi-purpose. Let me break down what that means:
Composability gives us the ability to build large programs from small programs using a model that doesn’t require one component to extend or depend on another — code can be written, modified, deleted and replaced independently of other code in the system, or even written before the future code exists.
Encapsulation makes it possible to contain the entire presentation, behaviour and state of a component. This means that outside code can not influence its behaviour (other than by composing another component by wrapping it).
Functional style of programming — props in, renderables out — makes React components robust and their behaviour easy to document and easy to understand, allowing developers to use components developed by others without needing to know how they work.
Multi-purpose is just a fancy way of saying that a component can be either a container component (controller) responsible for data and behaviour, or a presentational component (view). This separation was always the key insight of MV* architectures, and the elegant React Component API allows true separation of concerns while retaining the desirable qualities of composability and encapsulation.
This small and focused component abstraction gives us all the qualities we as developers seek: it’s easy to learn and remember, ergonomic to use, and results in programs that are possible to maintain and collaborate on.
But there is one more quality of components that I haven’t talked about yet, and that, it turns out, is the most important one.
Components are an Innovation Primitive
I began this article by praising the virtues of React, but I’m happy to admit React is not perfect; there are still tons of missed optimisation opportunities that the React core team is actively working on, and new ideas are constantly discussed, implemented, and discarded. When you look at the larger ecosystem of libraries, patterns and practices around React, they’re even further from perfect. We can’t even decide if composition should be done with Higher-Order Components, Render Props, Functional Children Props, or, god forbid, with Component Components!
While the wealth of options can sometimes be fatiguing, it is in fact a perfect example of the true strength of React’s component model. By having a universal, small, composable, flexible and reliable building block, we are able to discuss, test and accept new ideas without having to discard all our existing work.
It’s absolutely crazy to me that individual developers on different sides of the world can build revolutionary libraries like Redux, Apollo or styled-components, and application developers can adopt each of these new tools alongside their existing toolset without having to modify their existing code, or replace each individual piece without having to throw the baby out with the bathwater.
Each of these libraries do complicated things outside the React sphere, but none of them step on each others’ toes, because each of these tools can take advantage of the component composition model. Thus, the React component model is not only a user interface primitive — it’s an innovation primitive.
Unlike a progressive sprinkling of JavaScript, React can adopt new tools without having to refactor massive amounts of code thereby making their adoption infeasible. And unlike monolithic frameworks like Ember or Angular, React has sufficient flexibility to not snap when bent by the forces of inevitable change.
Change is the only constant
Having a platform that adapts to change is paramount, because change is inevitable and revolutions are expensive.
Smart people won’t suddenly stop seeing problems in the world and coming up with solutions for them. People won’t stop being frustrated by the constraints that exist, and won’t stop trying to break free. We as a developer community won’t suddenly stop wanting to adopt better tools when they are discovered. No matter how hard you want to bury your head in the sand and hope things stay the way they are, progress can’t be stopped.
When change happens, the best you can hope of a system is that it can adapt to change, because the only alternative is an unthinkable tragedy.
After the framework wars of the last decade, we now live in a time of unprecedented productivity, prosperity and peace. Tools like React allow us to build and maintain ambitious products.
If our tools stood in the way of progress, we would eventually have to discard them to move forward. And the cost of revolution is ruination: we would have to replace all our libraries, relearn all our good practices, retrain all our teams, repeat all our mistakes, and rewrite or refactor an incredible amount of code, instead of focusing on the products we were creating.
Revolutions are inevitable
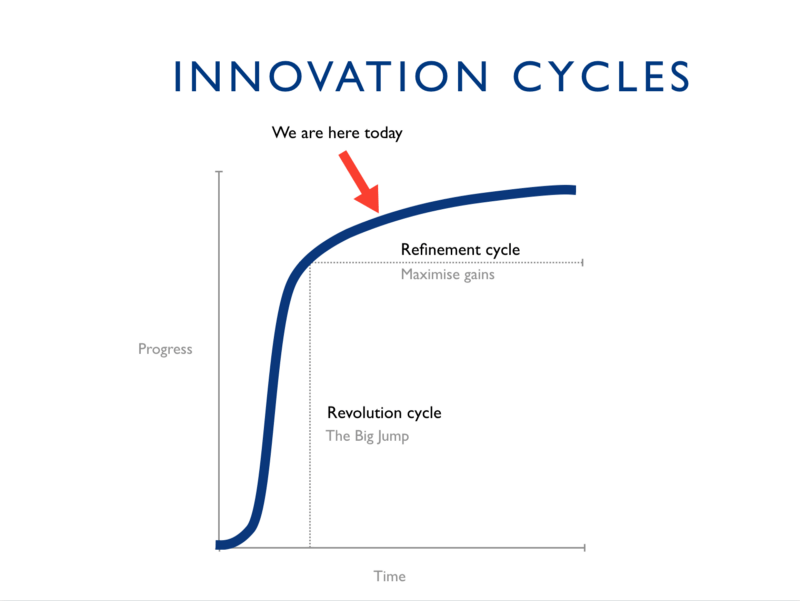
Innovation moves at two speeds:
Fast revolutionary bursts
Long tails of incremental refinement
Revolutions are rapid, refinement is slow.
React was a revolution. It overthrew the status quo of best practices of its time and provided us with a significant improvement in developer experience almost overnight. Now we’re fine tuning the engine until we can no longer squeeze more juice out of it. The refinement phase of the innovation cycle will eventually plateau, and will no longer be able to demonstrate the year-on-year progress that we’ve become accustomed to.
But the curve is not a fixed function. We can keep innovating and creating, as long as we as developers make decisions that keep our ecosystem responsive to change.
Let’s write software that’s responsive to change
No matter whether we’re working inside the React ecosystem, using another framework, building frameworkless progressive web applications, or even building software not related to the web platform at all, we can follow these lessons learned from React and its ecosystem to make the code bend instead of snap when faced with change.
Build big things from small things — compose software from smaller well-defined units, avoid monoliths. Carefully consider APIs and interfaces so that they can be used by others.
Make code easy to copy and delete, not easy to change — prefer composition over inheritance and mixins. Encapsulate behaviour. Do one thing and do it well.
Write code for humans first — make it possible to understand your work. Write code that expresses intent, not methodology. Name, document and catalogue your code so that everyone else can use it.
Stay close to the language — React is able to take advantage of new JavaScript language features and ecosystem tooling because it’s “just JavaScript” (with a little JSX). Avoid string-based DSLs and non-idiomatic interfaces that make it difficult to adopt new innovation.
Don’t break things if you don’t have to — Stability is a value unto itself, because change causes work and waste, or in the worst case, an AngularJS-level extinction event. Deprecate before breaking, use code mods or similar tools to make adapting to change easy. In your own code, don’t adopt new libraries just for the sake of it — measure cost vs. benefit before you do.
Keep an open mind — The final rule is a corollary to the previous. Sometimes new ideas can be scary and change can be inconvenient, but occasionally a revolution is necessary for change to take place. Don’t become a best practices police — keep an open mind and listen to what people are saying.
React is the winning ticket (for now)
I believe React is the obvious choice for building ambitious user interfaces that will be able to stand the vagaries of progress.
While I’ve underplayed the importance of Virtual DOM, it has proved to be one of the most future-friendly features of React. Because of the separation of the virtual representation and the implementation of your UI, React is well-suited for server side rendering and universal web applications. Native mobile platforms are an undeniable part of user interface development; React Native can help us there, and recoil gives us an exciting glimpse of what React could look like in native Kotlin and Swift. ReasonML and ReasonReact can help us move the React paradigm to platforms further than JavaScript can reach. With augmented and virtual reality technologies looming large in the future, there’s a threat of storm in the air, and I hope React VR and other similar experiments can help us weather it.
Eventually, React will be replaced by something else. We don’t yet know what the forcing function will be — WebAssembly, perhaps — and we don’t know what comes next. Whatever it is, I look forward to it with a mix of trepidation and excitement.
For now, thanks to React’s resilience, I’m confident we will get to enjoy our period of peace, prosperity and productivity for a while longer.
推荐理由:今天的文章可以说涉及到开源社区里非常非常早就讨论和应该讨论的问题,大家有注意到 Debian 的全名不是 Debian Linux 而是 Debian GNU/Linux 吗?一些 LUG 的全称也是 GNU/Linux User Group,也许你会困惑,但是其实背后代表着一种价值观。今天的文章作者也提到这个问题,大家一起看看他是怎么说的。
Is It Linux or GNU/Linux?
After putting this question to the experts, the conclusion is that no matter what you call it, it’s still Linux at its core.
Should the Linux operating system be called “Linux” or “GNU/Linux”? These days, asking that question might get as many blank stares returned as asking, “Is it live or is it Memorex?”
Some may remember that the Linux naming convention was a controversy that raged from the late 1990s until about the end of the first decade of the 21st century. Back then, if you called it “Linux”, the GNU/Linux crowd was sure to start a flame war with accusations that the GNU Project wasn’t being given due credit for its contribution to the OS. And if you called it “GNU/Linux”, accusations were made about political correctness, although operating systems are pretty much apolitical by nature as far as I can tell.
The brouhaha got started in the mid-1990s when Richard Stallman, among other things the founder of the Free Software Movement who penned the General Public License, began insisting on using the term “GNU/Linux” in recognition of the importance of the GNU Project to the OS. GNU was started by Stallman as an effort to build a free-in-every-way operating system based on the still-not-ready-for-prime-time Hurd microkernel.
According to this take, Linux was merely the kernel, and GNU software was the sauce that made Linux work.
Noting that the issue seems to have died down in recent years, and mindful of Shakespeare’s observation on roses, names and smells, I wondered if anyone really cares anymore what Linux is called. So, I put the issue to a number of movers and shakers in Linux and open-source circles by asking the simple question, “Is it GNU/Linux or just plain Linux?”
“This has been one of the more ridiculous debates in the FOSS realm, far outdistancing the Emacs-vi rift”, said Larry Cafiero, a longtime Linux advocate and FOSS writer who pulls publicity duties at the Southern California Linux Expo. “It’s akin to the Chevrolet-Chevy moniker. Technically the car produced by GM is a Chevrolet, but rarely does anyone trot out all three syllables. It’s a Chevy. Same with the shorthand for GNU/Linux being Linux. The shorthand version—the Chevy version—is Linux. If you insist in calling it a Chevrolet, it’s GNU/Linux.”
Next up was Steven J. Vaughan Nichols, who’s “been covering Unix since before Linux was a grad student”. He didn’t mince any words.
“Enough already”, he said. “RMS tried, and failed, to create an operating system: Hurd. He and the Free Software Foundation’s endless attempts to plaster his GNU name to the work of Linus Torvalds and the other Linux kernel developers is disingenuous and an insult to their work. RMS gets credit for EMACS, GPL, and GCC. Linux? No.”
To be fair, the use of GNU-related monikers didn’t start with Stallman. An early distribution, Yggdrasil, used the term “Linux/GNU/X” in 1992, and shortly thereafter the terms “GNU/Linux” and “GNU+Linux” began showing up in Usenet and mailing-list discussions. Debian, which early on was sponsored by the Free Software Foundation, starting using the term “GNU/Linux” in 1994, which it continues to use to this day. Stallman began publicly advocating its use in 1996.
But Stallman’s advocacy always put a bad taste in some people’s mouths.
“For me it’s always, always, always, always Linux,” said Alan Zeichick, an analyst at Camden Associates who frequently speaks, consults and writes about open-source projects for the enterprise. “One hundred percent. Never GNU/Linux. I follow industry norms.”
Well, somebody has to defend orthodoxy.
Gaël Duval, founder of the once uber-popular Mandrake/Mandriva distro who’s now developing eelo, a privacy-respecting Android clone, pointed out that insisting on GNU/Linux might open the door wider than originally intended. “I understand people who support the idea to call it GNU/Linux”, he said. “On the other hand, I do not see why in this case we wouldn’t use “GNU/X11/KDE/Gnome/Whatever/Linux” for desktop systems, because graphical environments and apps are very significant in such systems.
“Personally, I’m comfortable with both Linux and GNU/Linux”, he added, “but I use simply Linux, because adding complexity in communication and marketing is generally not efficient.”
Richi Jennings, an independent industry analyst who pens a weekly security column on TechBeacon, expressed a similar sentiment. “Look, it’s totally fair to give the GNU project its due”, he said. “On the other hand, if that fairness needs to be expressed in a naming convention, why stop at GNU? Why not also recognize BSD, XINU, PBM, OpenSSL, Samba and countless other FLOSS projects that need to be included to form a workable distro?
“The bottom line is that ‘Linux’ is what the vast majority of people call it. So that’s what it should be called, because that’s how language works.”
Self-professed “ace Linux guru” and Linux writer Carla Schroder said, “I’ve never called it GNU/Linux. GNU coreutils, tar, make, gcc, wget, bash and so on are still fundamental tools for a lot of Linux users. Certain people can’t let any Linux discussion pass without insisting that ‘Linux’ is only the kernel. Linux distros include a majority of non-GNU software, and I’m fine with ‘Linux’ as an umbrella term for the whole works. It’s simple and it’s widely recognized.”
Tallying the votes, it looks as if the “ayes” have it, and you can call Linux what you want. If anybody gives you any grief, tell them what Schroder told me: “Arguing is fun, but I suggest that contributing financially or in other ways to GNU/Linux/FOSS projects is more helpful.”
Or, we could argue about whether it’s FOSS or FLOSS.
The 3 Skills That Helped Me Become a Better Software Engineer
When asked “How to become a good software engineer?”, I recommend the following three skills:
Divide and Simplify
Develop Good Mental Models
Learn Your Tools
Don’t get me wrong, there are no shortcuts here — it takes many years of deliberate practice to become a decent engineer. The three skills above are something most good engineers practice. Almost without exception, when I interview a person who is good at the three skills, I know she is going to be a remarkable engineer.
Divide and Simplify
Divide
Since we are unable to keep more than 5–7 objects in working memory, any non-trivial problem is too large to think about in detail. We can either think about the problem abstractly, or think about a small part of the problem in detail. Both are important. It’s also important to be aware of the level of abstraction you are currently operating at. Either think abstractly, using metaphors and bulk approximations, or think precisely. Try not to mix the two.
This is the process I follow when dividing a problem into subproblems:
Step 1. Make sure you understand the problem.
State the problem on paper.
Write down all the constraints you know of.
Write down the things you don’t know that could have been helpful. Find them out.
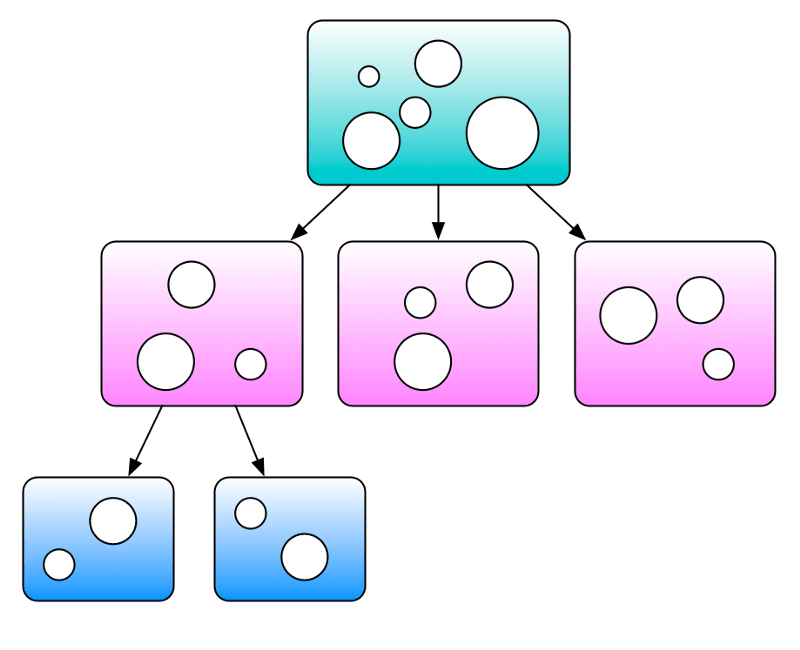
Step 2. Draw a diagram of the problem domain.
A few boxes and arrows, nothing fancy.
This diagram should give you an idea on how to divide the problem into subproblems.
Find a way to draw a diagram that divides the problem domain differently. If you cannot do it, you probably don’t understand the problem domain well enough.
Pick one way of dividing the problem.
Step 3. Pick a subproblem and use the same process to subdivide it further.
Stop when problems (problem subdomain) are small and clear.
Solve them individually and combine the results.
Simplify
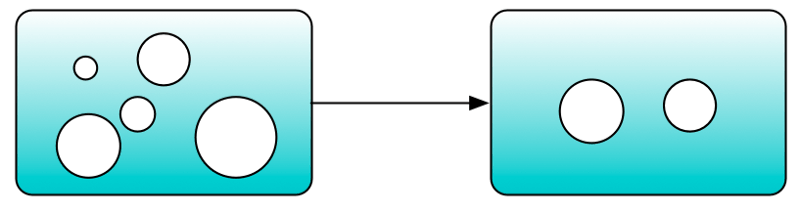
Subdividing works well when dealing with deep problems because every division removes one layer. Real-world systems aren’t just deep, they are also broad.
This means that even though you might be at the right level of abstraction, there is still too much detail for you to solve the problem. In this case, take the problem and come up with a simple reproduction illustrating it. Solve it in this simplified context, and then apply the fix to the real-world problem.
Imagine you are investigating a performance issue. Say by dividing the problem over and over again, you figured out that the issue is with a grid component. Unfortunately, you have dozens and dozens of rows of components rendered by the grid that obscure your investigation. After spending an hour trying to solve it as is, step back to figure out a way to simplify it. Create a new application using this grid reproducing the issue. Make it as simple as possible (e.g., maybe one column showing text). Use it to fix the problem and then apply the fix to the real world situation.
Use Scientific Method
Use the scientific method to improve your understanding of the problem. It works as follows:
Write down the question you are trying to answer.
Write down a hypothesis.
Write down a prediction that is the result of the hypothesis.
Test the prediction and write down the result.
Repeat until the question is answered.
Imagine we created a simplified application using the grid component. Now we can use the scientific method to figure out why it is slow.
Write down the question: Why does it take 5 seconds to render the grid?.
After thinking about it for a while, we can get this idea: Maybe the change detection runs too many times?. This is our first hypothesis, so let’s write it down.
A prediction we can use to check the hypothesis is that appRef.tick will appear multiple in the dev tools profiler.
We run the experiment and the result confirms our hypothesis. Let’s write it down.
Now, to the next question: Why does the change detection run hundreds of times?.
Steps 1, 3, an 4 of this process are well defined. They can almost feel mechanical. Step 2 — coming up with a hypothesis — is where the creative work happens. And that’s where good mental models and intuitions are of great help.
Develop Good Mental Models
“Point of view is worth 80 IQ points” Alan Kay
A high school student who knows basic algebra, geometry and calculus can solve more math problems than talented mathematicians of ancient Rome. That’s not because the student is “smarter”. Her IQ isn’t higher. She can do it because she has good mental models.
Developing good mental models is one of the most important investments we can make as engineers. For instance, look at this list:
Having a good mental model about X, does not mean you have to be an expert in X. It means that you can draw a diagram showing how X works, and, if given enough time, can build a simple version of X.
The mental models above are generic. These are some frontend-oriented mental models:
Bundling
Treeshaking
Change detection
Observable objects
Virtual DOM
CQRS/event sourcing/Redux
…
Develop Mental Models
How do you develop good mental models?
Read
First, you read a lot. Read books, read papers.
Use “Narrow” Technologies
Second, find a piece of technology that does just that thing you are trying to learn and does only that. If you are trying to learn functional programming, pick up Elm, and spend a week trying to solve problems with it. Since Elm is pure, it won’t let you take shortcuts — you will have to do it by the book. You also won’t be distracted by the complexity of a more generic tool, such as Scala.
Build It Yourself
Finally, build a simplified version of what you are trying to learn from scratch. Learning about a compiler? Build your own compiler. Learning about logical programming? Build your own prolog interpreter. Learning about distributed systems? Build a tiny program illustrating message passing between different nodes in the system. Use it to learn about CAP.
It takes a year to build a compiler for a mainstream programming language. That’s because you want it to be fast, always correct, and handle all the weird corner cases of that language. Take a simpler language (e.g., some variation for lisp), ignore performance issues, you can do it in a day.
Note, this is play, so you cannot fail at this. You don’t have to ship anything. The only purpose of this is your learning. So even if you haven’t finished your compiler, but you learned a lot — you succeeded.
Learn Your Tools
Software engineers are professionals that rely on tools. These are some of the tools I use every day:
Keyboard
OS
Shell
Editors and IDEs
Package managers (brew, npm, yarn, …)
Languages (typescript, css, …)
Dev tools (Chrome Dev tools, node debugger, source maps, …)
Frameworks and tools (angular, rxjs, webpack, rollup, …)
…
Whereas mental models are abstract, tools are concrete. You can be good at VSCode, but know nothing about VIM, even though both are text editors. It takes months or even years to learn a new keyboard layout or master an IDE. That’s why this list is a lot narrower.
There are two reasons to learn your tools well:
You are more effective at executing tasks if you know the right tools. If you know Angular well, you can build a simple app in an hour, without having to Google stuff. Similarly, you will be able to troubleshoot an issue with a debugger much faster comparing to debugging with console.log.
An even more important reason to learn your tools well is so you can use them without thinking. Take editor shortcuts. Using editor shortcuts is better not because it is faster (even though it is), but because you can use them automatically, without having to go through menus, without thinking about it at all. So your conscious mind is free to think about the real problem.
Being good at your tools doesn’t mean everything you use has to be custom. I use an ergonomic programmable keyboard because I spent a lot of time thinking about how my fingers move while typing. You don’t have to go that far. Just get good at whatever you use.
I find the following to be true:
Every engineer who knows their tools well is a good engineer. A person that doesn’t know their tools well is very unlikely to be a good engineer.
You Need to Be More Than a Good Engineer to Make an Impact
Mastering the three skills doesn’t mean you will be effective at your job or will make a substantial impact. Being able to troubleshoot a bug or write a new library is not enough to make an impact. These are some other skills that matter just as much, if not more:
Your social skills. Most interesting projects are built by teams. So they are built by people with different skills, backgrounds, and personalities. You need to have strong social skills to work in such environments.
Your writing skills. You have to communicate your ideas to your team, your clients, and the community. Writing is the most scalable way to do it. Practice writing.
Your work ethic.
…
Summary
These are the foundational skills of a good software engineer:
The “Divide and Simplify” skill helps us tackle complexity. This is how you think, and it is the most fundamental skill upon which everything is built. We use it when learning technologies, writing software, and debugging issues.
The “Learn Good Mental Models” skill helps us formulate hypotheses while debugging and helps us create novel solutions. This is the foundation that enables creativity.
The “Learn Your Tools” skill help us execute ideas: run experiments, write software. It also helps us unload all the trivial aspects of our work, so we can focus our conscious mind on non-trivial problems.