每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;微博:https://weibo.com/openingsource;电报群 https://t.me/OpeningSourceOrg

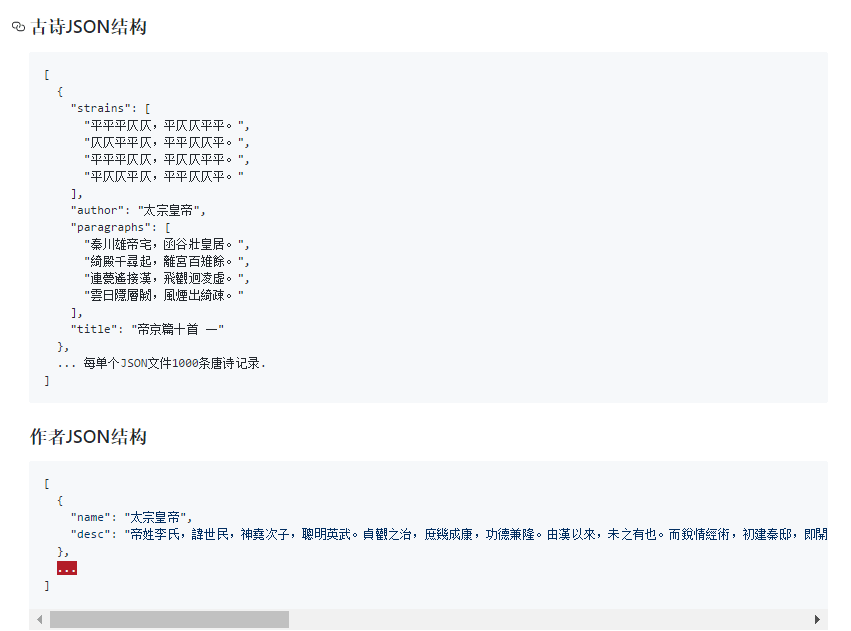
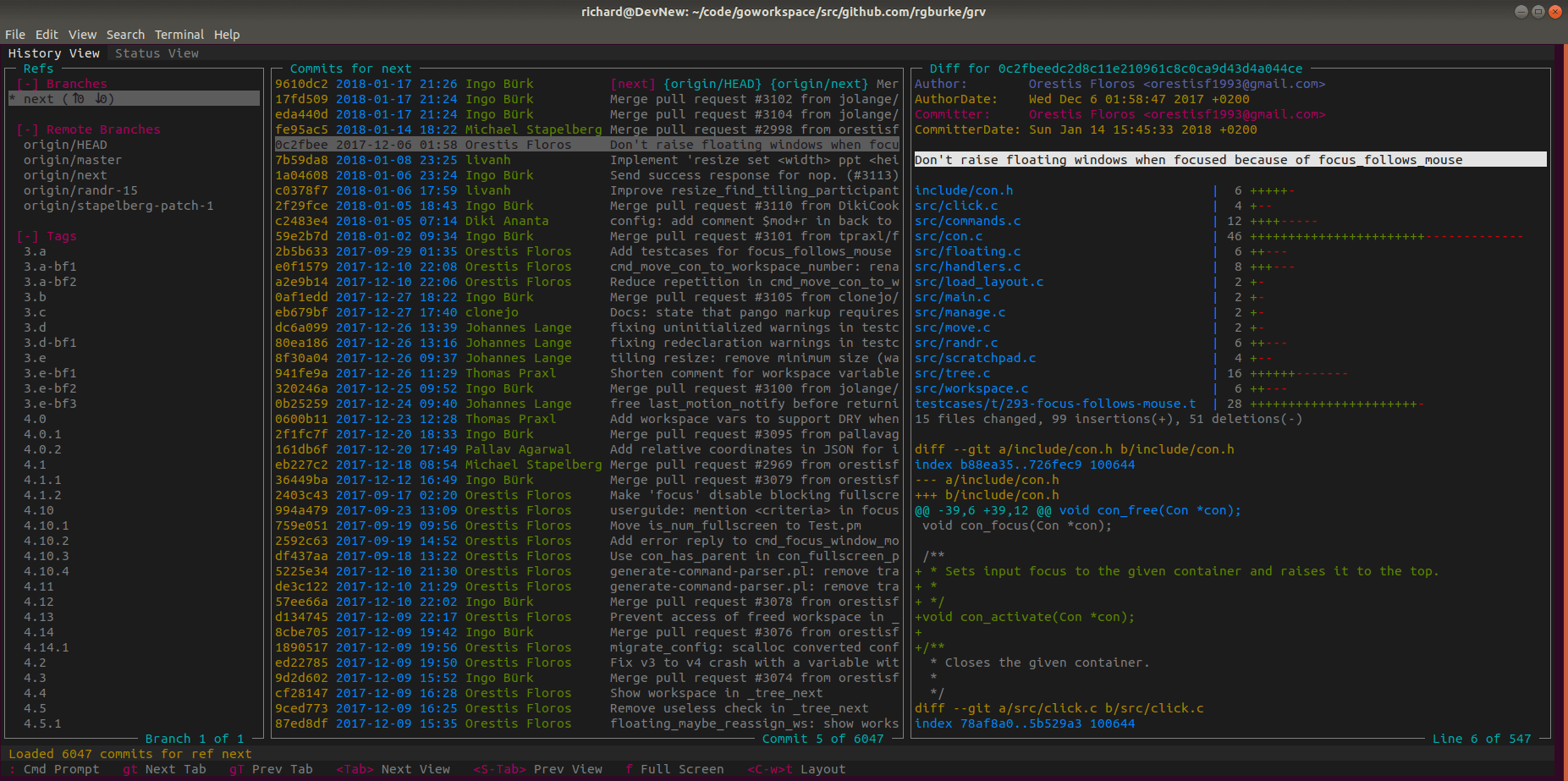
今日推荐开源项目:《图形界面开发库 LCUI》
推荐理由:LCUI 是一种自由和开放源代码的图形界面开发库,主要使用 C 语言编写,支持使用 CSS 和 XML 描述界面结构和样式,可用于构建简单的桌面应用程序。
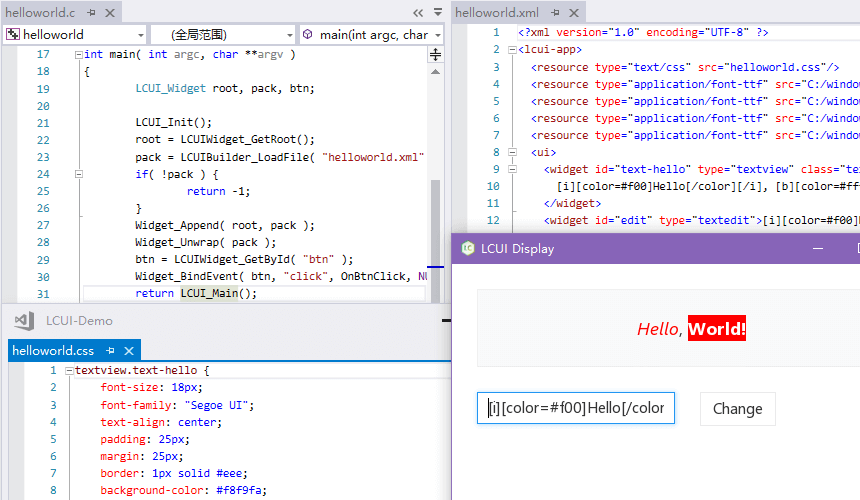
主要特性
- C 语言编写
- 跨平台
- XML 解析
- CSS 解析
- 类 HTML 布局
- 界面缩放
- 文本绘制
- 字体管理
- 图片处理
- 触控
luci.css
今日推荐英文原文:《Linux vs. Unix: What’s the difference?》作者:
原文链接:https://opensource.com/article/18/5/differences-between-linux-and-unix
推荐理由:Linux 和 Unix 有什么不同呢?
Linux vs. Unix: What’s the difference?
f you are a software developer in your 20s or 30s, you’ve grown up in a world dominated by Linux. It has been a significant player in the data center for decades, and while it’s hard to find definitive operating system market share reports, Linux’s share of data center operating systems could be as high as 70%, with Windows variants carrying nearly all the remaining percentage. Developers using any major public cloud can expect the target system will run Linux. Evidence that Linux is everywhere has grown in recent years when you add in Android and Linux-based embedded systems in smartphones, TVs, automobiles, and many other devices.
Even so, most software developers, even those who have grown up during this venerable “Linux revolution” have at least heard of Unix. It sounds similar to Linux, and you’ve probably heard people use these terms interchangeably. Or maybe you’ve heard Linux called a “Unix-like” operating system.
So, what is this Unix? The caricatures speak of wizard-like “graybeards” sitting behind glowing green screens, writing C code and shell scripts, powered by old-fashioned, drip-brewed coffee. But Unix has a much richer history beyond those bearded C programmers from the 1970s. While articles detailing the history of Unix and “Unix vs. Linux” comparisons abound, this article will offer a high-level background and a list of major differences between these complementary worlds.
Unix’s beginnings
The history of Unix begins at AT&T Bell Labs in the late 1960s with a small team of programmers looking to write a multi-tasking, multi-user operating system for the PDP-7. Two of the most notable members of this team at the Bell Labs research facility were Ken Thompson and Dennis Ritchie. While many of Unix’s concepts were derivative of its predecessor (Multics), the Unix team’s decision early in the 1970s to rewrite this small operating system in the C language is what separated Unix from all others. At the time, operating systems were rarely, if ever, portable. Instead, by nature of their design and low-level source language, operating systems were tightly linked to the hardware platform for which they had been authored. By refactoring Unix on the C programming language, Unix could now be ported to many hardware architectures.
In addition to this new portability, which allowed Unix to quickly expand beyond Bell Labs to other research, academic, and even commercial uses, several key of the operating system’s design tenets were attractive to users and programmers. For one, Ken Thompson’s Unix philosophy became a powerful model of modular software design and computing. The Unix philosophy recommended utilizing small, purpose-built programs in combination to do complex overall tasks. Since Unix was designed around files and pipes, this model of “piping” inputs and outputs of programs together into a linear set of operations on the input is still in vogue today. In fact, the current cloud functions-as-a-service (FaaS)/serverless computing model owes much of its heritage to the Unix philosophy.
Rapid growth and competition
Through the late 1970s and 80s, Unix became the root of a family tree that expanded across research, academia, and a growing commercial Unix operating system business. Unix was not open source software, and the Unix source code was licensable via agreements with its owner, AT&T. The first known software license was sold to the University of Illinois in 1975.
Unix grew quickly in academia, with Berkeley becoming a significant center of activity, given Ken Thompson’s sabbatical there in the ’70s. With all the activity around Unix at Berkeley, a new delivery of Unix software was born: the Berkeley Software Distribution, or BSD. Initially, BSD was not an alternative to AT&T’s Unix, but an add-on with additional software and capabilities. By the time 2BSD (the Second Berkeley Software Distribution) arrived in 1979, Bill Joy, a Berkeley grad student, had added now-famous programs such as vi and the C shell (/bin/csh).
In addition to BSD, which became one of the most popular branches of the Unix family, Unix’s commercial offerings exploded through the 1980s and into the ’90s with names like HP-UX, IBM’s AIX, Sun’s Solaris, Sequent, and Xenix. As the branches grew from the original root, the “Unix wars” began, and standardization became a new focus for the community. The POSIX standard was born in 1988, as well as other standardization follow-ons via The Open Group into the 1990s.
Around this time AT&T and Sun released System V Release 4 (SVR4), which was adopted by many commercial vendors. Separately, the BSD family of operating systems had grown over the years, leading to some open source variations that were released under the now-familiar BSD license. This included FreeBSD, OpenBSD, and NetBSD, each with a slightly different target market in the Unix server industry. These Unix variants continue to have some usage today, although many have seen their server market share dwindle into the single digits (or lower). BSD may have the largest install base of any modern Unix system today. Also, every Apple Mac hardware unit shipped in recent history can be claimed by BSD, as its OS X (now macOS) operating system is a BSD-derivative.
While the full history of Unix and its academic and commercial variants could take many more pages, for the sake of our article focus, let’s move on to the rise of Linux.
Enter Linux
What we call the Linux operating system today is really the combination of two efforts from the early 1990s. Richard Stallman was looking to create a truly free and open source alternative to the proprietary Unix system. He was working on the utilities and programs under the name GNU, a recursive algorithm meaning “GNU’s not Unix!” Although there was a kernel project underway, it turned out to be difficult going, and without a kernel, the free and open source operating system dream could not be realized. It was Linus Torvald’s work—producing a working and viable kernel that he called Linux—that brought the complete operating system to life. Given that Linus was using several GNU tools (e.g., the GNU Compiler Collection, or GCC), the marriage of the GNU tools and the Linux kernel was a perfect match.
Linux distributions came to life with the components of GNU, the Linux kernel, MIT’s X-Windows GUI, and other BSD components that could be used under the open source BSD license. The early popularity of distributions like Slackware and then Red Hat gave the “common PC user” of the 1990s access to the Linux operating system and, with it, many of the proprietary Unix system capabilities and utilities they used in their work or academic lives.
Because of the free and open source standing of all the Linux components, anyone could create a Linux distribution with a bit of effort, and soon the total number of distros reached into the hundreds. Today, distrowatch.com lists 312 unique Linux distributions available in some form. Of course, many developers utilize Linux either via cloud providers or by using popular free distributions like Fedora, Canonical’s Ubuntu, Debian, Arch Linux, Gentoo, and many other variants. Commercial Linux offerings, which provide support on top of the free and open source components, became viable as many enterprises, including IBM, migrated from proprietary Unix to offering middleware and software solutions atop Linux. Red Hat built a model of commercial support around Red Hat Enterprise Linux, as did German provider SUSE with SUSE Linux Enterprise Server (SLES).
Comparing Unix and Linux
So far, we’ve looked at the history of Unix and the rise of Linux and the GNU/Free Software Foundation underpinnings of a free and open source alternative to Unix. Let’s examine the differences between these two operating systems that share much of the same heritage and many of the same goals.
From a user experience perspective, not very much is different! Much of the attraction of Linux was the operating system’s availability across many hardware architectures (including the modern PC) and ability to use tools familiar to Unix system administrators and users.
Because of POSIX standards and compliance, software written on Unix could be compiled for a Linux operating system with a usually limited amount of porting effort. Shell scripts could be used directly on Linux in many cases. While some tools had slightly different flag/command-line options between Unix and Linux, many operated the same on both.
One side note is that the popularity of the macOS hardware and operating system as a platform for development that mainly targets Linux may be attributed to the BSD-like macOS operating system. Many tools and scripts meant for a Linux system work easily within the macOS terminal. Many open source software components available on Linux are easily available through tools like Homebrew.
The remaining differences between Linux and Unix are mainly related to the licensing model: open source vs. proprietary, licensed software. Also, the lack of a common kernel within Unix distributions has implications for software and hardware vendors. For Linux, a vendor can create a device driver for a specific hardware device and expect that, within reason, it will operate across most distributions. Because of the commercial and academic branches of the Unix tree, a vendor might have to write different drivers for variants of Unix and have licensing and other concerns related to access to an SDK or a distribution model for the software as a binary device driver across many Unix variants.
As both communities have matured over the past decade, many of the advancements in Linux have been adopted in the Unix world. Many GNU utilities were made available as add-ons for Unix systems where developers wanted features from GNU programs that aren’t part of Unix. For example, IBM’s AIX offered an AIX Toolbox for Linux Applications with hundreds of GNU software packages (like Bash, GCC, OpenLDAP, and many others) that could be added to an AIX installation to ease the transition between Linux and Unix-based AIX systems.
Proprietary Unix is still alive and well and, with many major vendors promising support for their current releases well into the 2020s, it goes without saying that Unix will be around for the foreseeable future. Also, the BSD branch of the Unix tree is open source, and NetBSD, OpenBSD, and FreeBSD all have strong user bases and open source communities that may not be as visible or active as Linux, but are holding their own in recent server share reports, with well above the proprietary Unix numbers in areas like web serving.
Where Linux has shown a significant advantage over proprietary Unix is in its availability across a vast number of hardware platforms and devices. The Raspberry Pi, popular with hobbyists and enthusiasts, is Linux-driven and has opened the door for an entire spectrum of IoT devices running Linux. We’ve already mentioned Android devices, autos (with Automotive Grade Linux), and smart TVs, where Linux has large market share. Every cloud provider on the planet offers virtual servers running Linux, and many of today’s most popular cloud-native stacks are Linux-based, whether you’re talking about container runtimes or Kubernetes or many of the serverless platforms that are gaining popularity.
One of the most revealing representations of Linux’s ascendancy is Microsoft’s transformation in recent years. If you told software developers a decade ago that the Windows operating system would “run Linux” in 2016, most of them would have laughed hysterically. But the existence and popularity of the Windows Subsystem for Linux (WSL), as well as more recently announced capabilities like the Windows port of Docker, including LCOW (Linux containers on Windows) support, are evidence of the impact that Linux has had—and clearly will continue to have—across the software world.
每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;微博:https://weibo.com/openingsource;电报群 https://t.me/OpeningSourceOrg