每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;微博:https://weibo.com/openingsource;电报群 https://t.me/OpeningSourceOrg

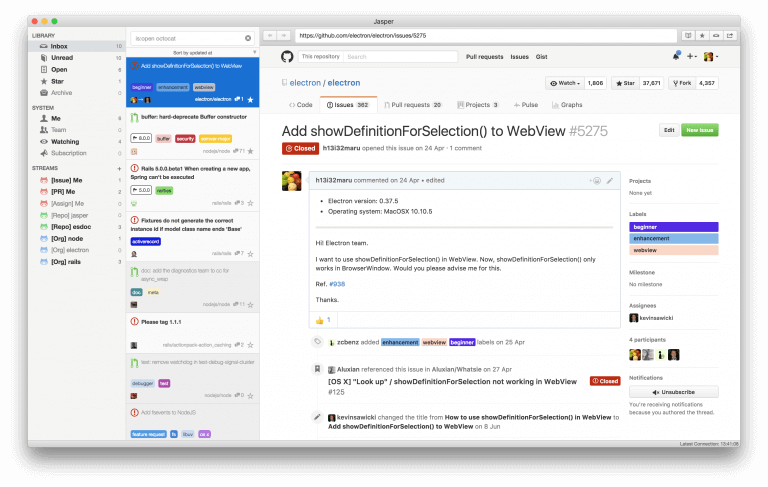
今日推荐开源项目:《GitHub issue 阅读器 Jasper》传送门:GitHub链接
推荐理由:顾名思义,这个 app 可以让你阅读 GitHub 上的 issue,如果你不想打开网页版的 GitHub 又想能够分门别类的看 issue 的话就可以考虑使用它,而且它还能把未读的 issue 整理起来,不用担心错过什么。
今日推荐英文原文:《You Give Code a Bad Name》作者:Chico Carvalho
原文链接:https://goiabada.blog/you-give-code-a-bad-name-f5e96f9793c8
推荐理由:给代码起名字的建议,最起码看了这个之后,你肯定不会想再拿着《婴儿起名指南》给你的代码命名了
You Give Code a Bad Name
As they start taking their early steps in the software development world, one of the first tasks a new programmer has to deal with is naming things. Folder hierarchy, files, classes, objects, functions, variables and even lower level stuff such as custom protocol messages, everything needs a name.
As far as compilers and interpreters are concerned, it doesn’t matter what name you give things, as long as you’re able to univocally and unambiguously identify them, but this couldn’t be further from the truth when it comes to us humans. Unlike a hard drive or RAM module, where the nature of the data being stored is largely irrelevant, the human memory works much more efficiently by syntactic and semantic association. Outside the programming world, we already agree upon stems, prefixes, suffixes and other basic lexical elements to toy around meanings and relationships, which we bootstrap into entire languages. It is only natural that we extend this behavior to programming languages as far as reasonably possible, leveraging semantics and mnemonic associations as much as we can.
In this article I’ll Be There For You: I’d like to raise awareness of the importance of naming, discussing a bit about the incentives every developer should have to stop overlooking this topic as frequently as we see out there.
What this article isn’t about
This article will not discuss any particular casing standard, language paradigm preferences, explicit documentation guidelines or partake in the endless text editor skirmish.
More than looking cool
When I first started programming back in 2003 I remember finding it pretty neat that I could have my own SomethingBrokers, WhateverAdapters, ThingyLaunchers and whatnot (yes, I was young). Fancy names brought them (and me) a sense of responsibility and convinced me my code did some pretty serious stuff, even though it was only a Programming 101 project. As you’d expect, giving things names isn’t (just :B) about looking flashy and l33t. But Keep The Faith: good naming practices usually lead to better readability, quicker comprehension of each snippet’s purpose, an easier time navigating through your project’s structure and often provide an implicit documentation of what’s being done by the program.
And this isn’t only about you and what you might subjectively think works best. Writing code is virtually Always a team experience and should always take the future reader into account, even if you’re flying solo for the time being. The “you” reading a piece of code you wrote several months before will probably have forgotten most of what’s going on, and might need to rebuild a precise understanding of its intricacies in order to make correct, cohesive, meaningful and elegant changes.
OO Basics — no harm in remembering
As it gained momentum, Object Orientation has provided us with enough incentives to properly separate what describes a structure and its capabilities (classes and attributes) and what actually does something to change the state of a program (methods). This has led to a very basic naming guideline by which we baptize classes and attributes/properties with nouns (descriptions) and methods with verbs (actions).
This has been the norm since programming languages supporting OO techniques became widely available in the early 1990s. However, the shift of focus to web development sprung to life new design patterns which started to defy this standard, as we’ll see later on.
Syntactic Parallelism
The human brain likes some degree of repetition and standardization. We see this thrive, for example, in music, poetry, architecture and… programming. Writing and naming groups of related entities should take this into account, as it more explicitly tightens that relationship in the eyes of the reader. One of the techniques employed to accomplish this is to make them follow the same syntactic pattern. Check out these two lists:

Both try to enumerate house chores and convey the same meaning, but the one on the right does it in a neater, more elegant and predictable way. In that particular example, all entries are composed of a verb in the infinitive form and a noun or expression acting as the object of that action. You don’t need to think about it at all, but after reading a couple of them, your brain actually expects the next list item to be built using the same structure. Aesthetics aside, pretty much like a hard drive that relies on the principle of locality to read data ahead of time, knowing something about what comes next usually makes for faster skimming and quicker understanding of the message being read. This is called syntactic parallelism and is one of the key concepts you should take away from this article. Make a Memory out of it.
Objects and Collections
Developers face a very common naming tradeoff when they have to deal with both single objects and their collections in the same coding context:
- On the one hand, you can opt for briefer, more concise names, using the classic singular/plural forms, such as
accountandaccounts. This will shorten lines of code and minimize line-breaking, improving block readability and reducing overall code verbosity. - Alternatively, you may choose longer, more explicit differentiations, like
accountObjectandaccountCollection, which in turn will favor clarity and individual pointer readability. - Last but not least, it might be tempting to go for the best of both worlds and write
accountfor the single object andaccountCollectionfor the list.
I usually Runaway from that last one because it breaks syntactic parallelism and might give the reader the impression that there’s more difference to what they do semantically than a singular/plural thing. And after a while thinking about this, I’d say it’s a tight fight between forms 1 and 2: on the one hand, I’ve had several minor productivity setbacks overlooking the trailing s over the years and, as such, tend to prefer the latter. But on the other hand, I can certainly see that if a team builds a strong and horizontal culture that singular and plural are the way to go, double-checking that kind of stuff could become second nature to everyone and tip the scales towards the first option.
Iterators
Walking through a collection of items and doing something with them is one of the bread-and-butters of programming life. Regardless of what you’re writing, there are going to be iterators all over your code. And even though the more high level programming languages may abstract that for you, there are still a few that don’t, and for them there’s a very simple naming trick: instead of writing i, j, k and the like for iterator variables, try using ii, jj, kk and so forth. This one effortless change improves searchability** tenfold while maintaining the standard expectation on these variable names.
**I know that this is arguable and that there are a lot of code editors out there with advanced search features that could help with this without using the trick, but its so effortless, portable and editor-agnostic that I still think its a decent idea.
Service Objects
Service Objects (SOs) are a great concept and have a lot of space in today’s web apps, but usually bring up a few naming mishaps. Look at this service object folder, for example:

This is a pretty good (and real-life) illustration of the controversy surrounding service object naming. First, note that even though some people tend to call these classes SOs, the SOs themselves are actually the instances of SO-describing classes. Then remember that, for the classes, the natural way is to name them after nouns, and therein lies the issue. We see paginator, deal_notifier and a few ending in metric, cool. But we also see clone_investment, upsert_investment and cancel_<something_complicated>(God Bless This Mess).
Wait, verbs ??? ???
So, yeah. What happens is that SOs as a design pattern have the purpose of implementing a single operation that makes sense in your business logic, the actual service they’re providing you with, their very raison d’être. Their public interface is usually made up of a sole method, possibly static, and usually named call. And since they can’t do anything else, developers started thinking it’d be reasonable to name them after the action they will perform once call-ed, thus releasing themselves from the clutches of one of academic OO’s most iconic naming standards.
I resisted that myself for a while, thinking it could be Bad Medicine. “Why can’t we just name them with nouns and use them the exact same way? InvestmentCloner.call() doesn’t look so bad”. The thing is their instances differ from most because they have a very well-defined lifecycle: they’ll be created, called upon to do their thing and (hopefully) die gracefully*. So developers (especially the ruby community, who are known for favoring readability) started thinking that naming them after the actions they perform, such as NotifyCustomer or AbortMission, could make for quicker code apprehension without any semantic loss.
*Using singletons to implement service objects is kind of an anti-pattern. The global visibility, long life and likely statefulness of a singleton is too hard to test and too side effect-prone. More in-depth discussion on this theme can be found here and in the linked questions.
Minimizing abstraction leaks
The awesome and timeless 2002 Joel Spolsky article ‘The Law of Leaky Abstractions’ brings to light an essential flaw in programming understood as the craft of implementing incremental, layered abstractions. In a nutshell, he theorizes that “all non-trivial abstractions, to some degree, are leaky”, in which they fail to do what they’re supposed to while completely shielding the user from their inner workings. This is particularly important for us because bad naming is a huge source of abstraction leaks, which in turn means we can minimize or even completely avoid them by taking proper care with what we’re saying they do.
So, we’re looking for names that on the one hand empower the entity, implying their general “area of expertise”, but that on the other hand are careful enough to restrict these expectations as to avoid suggesting too much power. It comes as no surprise that the overall architecture usually profits from this, since the developer is obligated to pay closer attention to the relationship between entities and the bounds of their roles.
Ok, cool, but let’s see some code
So, let’s move away from bullet point-guidelines for a bit and build something up step by step while trying to avoid other aspects of poor naming.
Say we want to write a service to connect to Instagram and do instagrammy stuff like fetch somebody’s posts, crawl comments to a certain post, get likes to said comments and the sort. We could start off thinking of a name for it:
class Instagram # ... end
This doesn’t say much about the class, except that it has something to do with Instagram, duh. As far as we know, it could as well have methods to remotely implode the Instagram HQ. Let’s try something clearer:
class InstagramCrawler # ... end
Ok, this isn’t perfect but says a lot more about the stuff I want to represent. I already expect a class whose objects will crawl Instagram for stuff. Still, it strikes me as too powerful and monolithic an abstraction, which can have too many lines of code, be more confusing than it needs to be, require too much studying to figure out, easily cause abstraction leaks or all of the above. Maybe we could break it down a bit:
class InstagramCrawler
def initialize
@client = InstagramClient.new
end
# ... methods that possibly call @client.something()
end
class InstagramClient
# ...
end
Alright! Now we can further restrict our expectations of the crawler abstraction and believe it won’t care about talking to the instagram API itself, relaying this stuff to InstagramClient*. At the same time, we created a perfectly reasonable character for abstracting the service that worries about interfacing with the Instagram API, with the added benefit that InstagramCrawler doesn’t even know or care if this communication is gonna be via REST, GraphQL or some other weird protocol.
We’re gonna stop here for the sake of this example, but if you feel your ‘crawler’ does far too much stuff to be in a single class or that your ‘client’ could also be further broken down, this isn’t necessarily the right point to stop refining the abstractions.
*Real-world applications probably would allow for injecting the client for testing and decoupling purposes.
Now let’s get One Step Closer and think a little bit about error treatment, and begin by creating a custom InstagramError that extends Ruby’s StandardError:
class InstagramCrawler
def initialize(client: client)
@client = client
end
# ... methods that possibly call @client.something()
class InstagramCrawlerError < StandardError; end
end
class InstagramClient
# ...
end
So, while this could potentially represent every error our crawler could spit out and quickly solve our problem, it’s missing out on a perfectly good opportunity to make the developers’ life far easier. By putting in a little more effort at this point and restricting exception abstractions a bit more, we could save hours of slow debugging time by better describing what kind of errors took place:
class InstagramCrawler
def initialize(client: client)
@client = client
end
# ... methods that possibly call @client.something()
class InstagramCrawlerError < StandardError; end
class UserUnavailableError < InstagramCrawlerError; end
class InexistentLocationError < InstagramCrawlerError; end
class ExpiredMediumError < InstagramCrawlerError; end
class InvalidAccessTokenError < InstagramCrawlerError; end
class MalformedRequestError < InstagramCrawlerError; end
class ServiceUnavailableError < InstagramCrawlerError; end
class TimeoutError < InstagramCrawlerError; end
end
class InstagramClient
# ...
end
(Of course, in order to raise these errors correctly we’d need some additional error treatment code im deliberately skipping for the purposes of this analysis.)
What About Now? This already looks like a giant timesaver during debugging time in which the devs will much more quickly be able to discern what problem took place without having to go through logs or huge response message outputs.
However, it exposes a gaping abstraction leak by having the Crawler know about and have to deal with communication and protocol issues such as MalformedRequestError and InvalidAccessTokenError. But we have just the place to fit these in, don’t we?
class InstagramCrawler
def initialize(client: client)
@client = client
end
# ... methods that possibly call @client.something()
class InstagramCrawlerError < StandardError; end
class UserUnavailableError < InstagramCrawlerError; end
class InexistentLocationError < InstagramCrawlerError; end
class ExpiredMediumError < InstagramCrawlerError; end
end
class InstagramClient
# ...
class InstagramClientError < StandardError; end
class InvalidAccessTokenError < InstagramClientError; end
class MalformedRequestError < InstagramClientError; end
class ServiceUnavailableError < InstagramClientError; end
class TimeoutError < InstagramClientError; end
end
This is the final form of our little example case study, which is an adapted subset of real-life code which has been in production for several years. Proper care with naming aided our team in avoiding abstraction leaks, semantically dividing responsibilities among entities, simplifying the debugging process and made us write overall clearer, more self-explaining, understandable code.
The meaningless abstraction
Before we wrap up, I’d like to show an unstructured example of something that not rarely pops up in code reviews, making me feel Shot Through The Heart:
import React from "react"
class Auth extends React.Component {
render() {
return <div>{this.props.children}</div>
}
}
export default Auth
This is an extremely simple React component that doesn’t do much except for wrapping its children elements in a div tag. And in spite of its simplicity, at first I had no idea why someone thought it would be a good idea to name it Auth. “Maybe it was a bad name for an authentication component ?”. Just it isn’t, since it doesn’t implement any authentication behavior or appearance. It’s also not some weird standard React boilerplate, so we’re left with a meaningless/misleading abstraction, a pair of name and entity that doesn’t help us at all to discern or put boundaries to the latter. If we go deep enough down the rabbit hole, we may even find it to serve some twisted purpose (a master component to group up authentication sub-components? a testing selector?), but the name doesn’t point us towards its architectural relevance and the implementation raises a yellow flag right off the bat.
Closing words
Two main things motivated me to write this blog post. Firstly, It’s My Life: whenever I’m assigned to a project that is already underway, I see that my biggest onboarding roadblocks hinge on unclear project architecture/folder structure and bad naming. It usually feels like trying to internalize a rational, working model of an Escher drawing: even though it somehow works, it makes little sense and seems impossible to tie all ends without creating new loose ones. Secondly, there seems to be a noticeable lack of reading material discussing the subject outside the context of specific languages or particular/recurring naming conundrums.
So, all in all, These Days seemed like a good moment to give others Something For The Pain and write down a few ideas along with established practices. Hopefully some new devs will pop in here and come out knowing that good, proper naming isn’t one of those things you learn and then forget as soon as you finish school. Plus, I fully expect these ideas to foster discussion and spark up at least some controversy among the more experienced, so readers are more than welcome to bring old and new thoughts to the table.
Now let’s put on some loud Bon Jovi and go back to coding. Have a Nice Day!???
P.S. Just so I’m not Misunderstood, let me give y’all Something To Believe In: the random capitalized words throughout the text are not random at all. Raise Your Hands in the comments or clap if you found them all! 😉
每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;微博:https://weibo.com/openingsource;电报群 https://t.me/OpeningSourceOrg