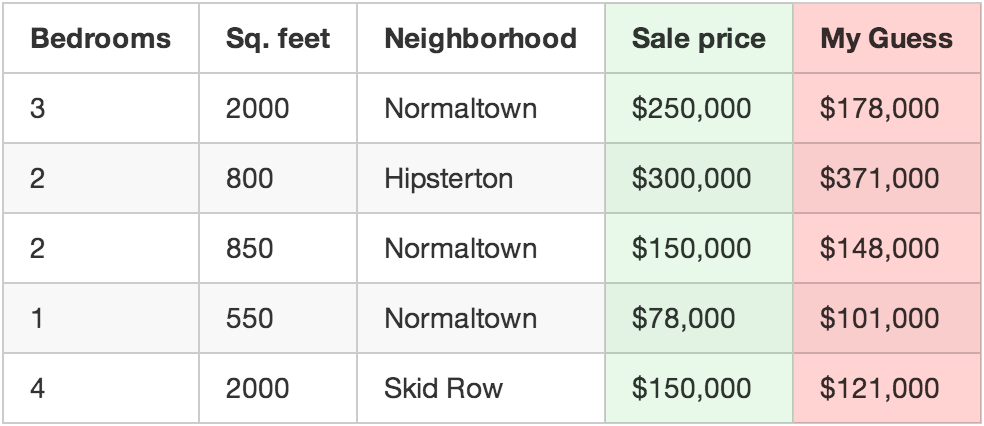
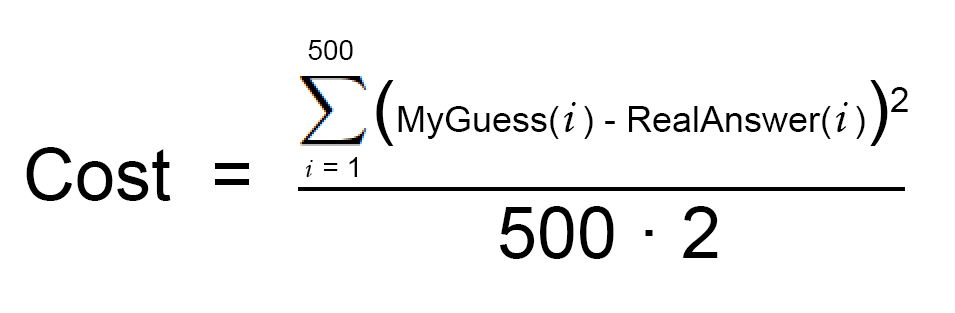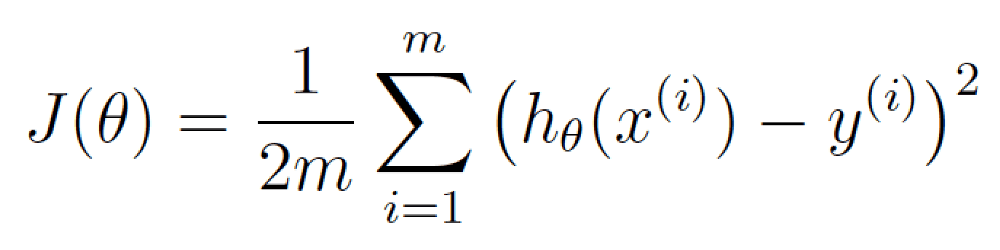每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;微博:https://weibo.com/openingsource;电报群 https://t.me/OpeningSourceOrg

今日推荐开源项目:《图片上传工具 PicGo》传送门:GitHub链接
推荐理由:顾名思义,这是一个图片上传工具……它真的就是一个图片上传工具而已,可以把图片上传到现在已经支持的图床,对于每一种图床的操作方法已经在手册里面写有了,如果还有问题的话兴许看看 FAQ 可以帮你解决,顺带一提,等它的2.0版本发布之后,将会支持第三方图床插件来上传到所需的图床上,兴许现在可以静观其变。

今日推荐英文原文:《Wanna be a developer? Here is what you need to take into account.》作者:Vinh Le
推荐理由:一些从作者的经验中得来的作为开发者需要知道的东西
Wanna be a developer? Here is what you need to take into account.
A common myth about software developers is that they’re boring and dry geeks, who were math geniuses at school, that spend hours in front of computer screens writing code.
Yes, developers may spend their life in front of computer screens writing code. However, there is much more to it than just coding like a machine the whole day. For me personally, being a developer means you have the chance to build cool stuff by yourself.
I started self-learning front-end development my sophomore year. My journey has been filled with self-doubt and hurdles, along with joy and extreme excitement. I never imagined I could experience all that while learning something.
Sometimes, even now, I still wonder whether I am following the right path. However, by telling myself that there is nothing more pleasurable than being able to do what I love, I keep putting my head down and I continue working.
It has been around two years since I started writing my first lines of code. After many hours of practicing, with sometimes feeling like giving up followed by temporary discontinuity, I would like to share with you a few things that I wish I knew from the beginning.
Don’t treat coding as a leisure interest
First and foremost, if you think that you need to be serious while coding, you’re 100 percent right. It is definitely true that you will probably not spend time doing something you don’t like.
However, doing it just on a hobby basis — that is, you only code when you feel like doing it without any specific commitment or schedule — will probably not lead you to the career that you have always wanted.
In addition, when you encounter obstacles and difficulties, are you sure that you will have enough patience to keep your little interest alive? Rather, you might end up giving up or potentially going through a long stagnation in the middle.
Therefore, you should be incredibly dedicated to your passion, my friends. Yes, I am sure that all of us developers have a great interest in coding and technology in general.
However, passion is nothing without the right execution. By committing to a specific goal along with an appropriate schedule, you are building milestones along your journey. Put in a huge commitment to your given timeframe. Specify which skills and technologies you want to learn over a certain period of time. Then you’ll be closer than ever to making learning how to code an imperative part of your life.
Figure out which technologies you need to focus on
Once you’ve started taking coding seriously, the next step is to be honest with yourself. What kind of developer do you want to be?
Start by asking yourself what interests you the most. Are you passionate about building user interfaces which control the way users interact with your product? If yes, then front-end technologies should be your main focus. Or maybe designing is not in your DNA and you’re interested in how the server side works — then back-end stuff should be your focus.
Giving yourself a clear idea of what you need to learn, based on your interests, is a key element. If you’re still not sure which side is for you, Google them to figure it out or try out a bit of each. Each of us have our own preferences and skills — the things we do best. So answering this question might be simpler than you’ve thought.
Start with the easy things
In the beginning, you might be confused by almost every single task, regardless of difficulty level. From choosing a proper text editor to setting up an environment for a project, it will surely cause you more troubles than you ever expected.
Therefore, if you are a complete beginner who is trying out their first language, I highly recommend starting with the easy things. Focus on platforms that provide interactive coding playgrounds, such as Codecademy.
That’s where I began, too. These platforms help you focus solely on being familiar with the programming languages without worrying about initialization. You will need to learn these things later on, of course. However, I believe that beginning with writing code will not only excite you, but also help you avoid being overwhelmed.
What learning resources are out there?
There are different paths that you can choose in order to be a software developer. You could either enroll for a computer science degree, participate in coding bootcamps, or even teach yourself. Either way, you’ll always need to constantly update your learning materials. As I belong to the last category, I would like to share how I filter out my learning resources.
Begin with coding playgrounds
At the very first step, starting with easy-to-understand-and-learn platforms such as Codecademy. It offers a place where you are able to read the instructions, and then practice the knowledge right away thanks to the built-in web-based text editor. The result is shown on the screen as well. Just sign in for free, pick up what technologies you are interested in, enter the designated learning track, then you’re good to go.
Another very useful resources especially for newbies is freeCodeCamp. Unlike Codecademy where you have to pay for more premium courses (which are, however, very useful), freeCodeCamp offers totally FREE courses and learning tracks. They even give you certificates when you complete each major section.
Their tutorials also include detailed instructions, a built-in text editor, and clear explanations too. Additionally, there are projects available where you can use the skills you’ve learned to solve various problems.
Choosing the right learning resources
This process is actually quite challenging. It’s not because there are too few reliable and well-documented sources. There are actually too many tutorials, which potentially overwhelm you at first. Deciding on which way to go can be tough, as you will probably spend a certain period of time following along each path you try. Therefore, a bad tutorial might not only cost you time but also demotivate you from moving forward.
Before asking anyone else or Googling where should you learn, please do me a favor, my friends: ask yourself first! Why? Because there are various types of tutorials out there — videos, e-books, textbooks, and online or in-person bootcamps. Only you’ll be able to tell what type of resources you can effectively learn the most from.
For me personally, I enjoy watching video tutorials and coding along while watching them. That’s why I treat it as my primary learning method. But you might like reading instead so you can entirely control the pace of learning. In that case, you’d be better off going go for well-known books.
Ultimately, you may realize that it is necessary to combine different learning methods. However, in each case you’ll perhaps spend a lot of your time on Medium, where you’ll find many useful resources that you’re most comfortable with.
And so, just like the way you’ll figure out what technologies you decide to learn, take a step back, give your mind some space, and determine what type of learning resources you’d like to consume. When you’ve found something that it is right for you, then go for it!
Here are a few great categorized tutorials that I found super useful:
Video
- LearnCode.academy Tutorials
- Traversy Media Tutorials
- Academind Tutorials
- The New Boston Tutorials
- LearnWebCode Tutorials
- Rally Coding Tutorials
- LevalUpTuts Tutorials
- DevTips Tutorials
- Coding Tech Tutorials
- freeCodeCamp Tutorials
- Coding Tech Tech conference
MOOCs (Paid online courses)
Books
In-depth knowledge
- The Eloquent JavaScript
- You Don’t Know JavaScript
Tech & Design
- The Phoenix Project
- Don’t Make Me Think
- The Design of Everyday Things
Surround yourself with tech
As mention above, whatever resource you chose to start with, you’ll probably need to rely on different mediums. And that’s the interesting part of being a developer. By surrounding yourself with tech stuff, you will be “learning while relaxing”.
Imagining that…
You wake up early and start the day by continuing your online tutorial. After almost an hour or so concentrating, you decide to take a break. A Netflix episode? No. You realize that there’s no way you would spend an hour watching TV, and instead open YouTube. You decide to spend time on a 30 minute talk on Coding Tech.
The video you viewed received over a hundred thousand views. The guy was talking about the future of CSS thanks to Grid. Interesting! “The time for remembering or checking documentation for Bootstrap grid classes is over”, you murmur. Let’s see how it works!
You Google CSS Grid, then go for a blog post published in the freeCodeCamp Medium publication. Thanks to this blog, you grasp some key points and can’t wait to open VSCode to try it out. It is amazing! Oops, something goes wrong. You probably go through a few more questions by folks in StackOverFlow or some more tutorials on CSSTricks. You go around and then finally get it to work.
During lunch, you open a podcast and listen to the latest freeCodeCamp episode, which is about how a self-taught developer landed his first tech job. After lunch, you decide to continue with the React tutorial on Udemy. You suddenly find a problem that you’re not clear about, and the Q&A section doesn’t help.
Tired of being stuck for half an hour, you decide to temporarily give up and hope to resolve it later. Then you go to surf through the Dev community on Codeburst to see tips and trends from fellow tech enthusiasts. This is truly a place where people join to share their knowledge and discuss with others.
You then think: “May be I should start writing something, whatever it is that I have observed and learned throughout my journey…then I can share it with everyone”. Opening a Google doc page, you excitedly type: “Do you want to be a developer….”?
Does this story somehow motivate you? If yes then what are you waiting for? Let’s jump into the world where all of us are developing technological applications to make the world a better place.
Practice, practice and practice
Okay so now that you have some idea of where to start, it is probably a good idea to start right now. However, being good at something really requires time. To be great, you need to put in tons of work. It is impossible to fill the gap between being a developer that is just starting out and being an experienced developer without sweat and tears.
In other words, to be proficient in a programming language, you’d need to put in hours — years — of practice. How, you ask?
- Follow along with tutorials and actively Google or StackOverFlow bugs that you might meet along the way.
- Dedicate a certain period of time per day only to coding.
If you’re tired, take a break and go surf around, visit forums and platforms where tech leaders and seasoned developers share what is happening in the tech world. Basically surround yourself by tech stuff.
Remember, you’re moving to the next important steps of the success ladder. The more work you put in, the more confident and enthusiastic you’ll probably feel. Just take into account that there is absolutely no shortcut. There is no language or libraries or extension that can help you achieve an overnight success. Keep hustling, learning from failures, being responsible and committed to your schedule and believe in yourself. The day your dream comes true might just be around the corner!
That’s the end of this blog! Thanks for reading! If you like it, please hit ???
Say hello on SM: Facebook, Twitter, LinkedIn, or my personal site.
Stay tuned for upcoming tech blogs???
See you soon!
每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;微博:https://weibo.com/openingsource;电报群 https://t.me/OpeningSourceOrg