每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;微博:https://weibo.com/openingsource;电报群 https://t.me/OpeningSourceOrg

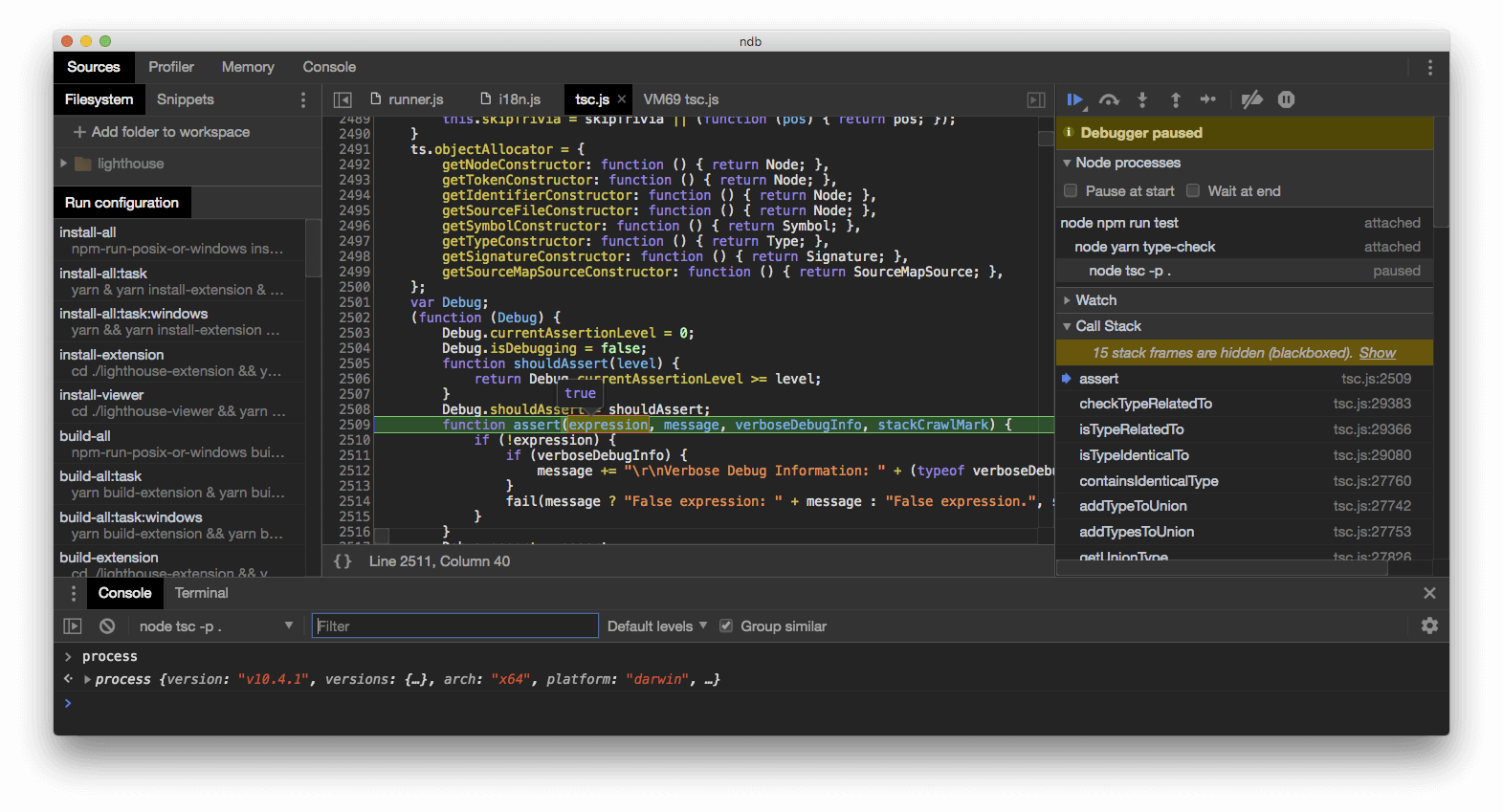
今日推荐开源项目:《强化 Node.js ndb》传送门:GitHub链接
推荐理由:ndb 是谷歌推出的一款 Node.js 的调试工具,毕竟是 Node.js,很多时候你都会看到它。这个 Node.js 的调试工具可以帮助你进行诸如增加断点这样的调试用操作,兴许使用 Node 的朋友什么时候就用的上这个。
今日推荐英文原文:《A Bit about Binary Tree》作者:Hitesh Kumar
原文链接:https://medium.com/smelly-code/a-bit-about-binary-tree-111e2d600974
推荐理由:二叉树,学数据结构的时候,迟早会碰上这个的,而且兴许还会一起碰上左旋转右旋转之类的,不过总而言之,二叉树是迟早都要学的
A Bit about Binary Tree
In the previous post, A Gentle Introduction to Trees ?, we acquainted ourselves with trees and their properties. We saw that the naturally hierarchical data are well represented using trees. We learned that the topmost element in the hierarchy/tree which does not have any parent is called the root of a tree. Today’s post talks about a special type of tree called Binary Tree.
Binary tree is a tree where each node can have maximum two children. Since there are only two children so it’s quite intuitive to call them left and right child. Let’s get our hands dirty and code a BinaryTreeNode class in JavaScript as per the definition above.
/**
* Represent a BinaryTreeNode
*/
class BinaryTreeNode {
constructor(value) {
// Value which our beloved node represents.
this.value = value;
// Reference of the left child.
this.left = null;
// Reference of the right child.
this.right = null;
} }
Here’s our first binary tree created using the BinaryTreeNode class.
const root = new BinaryTreeNode(10); const left = new BinaryTreeNode(20); const right = new BinaryTreeNode(30); root.left = left; root.right = right; console.log(root);
// Our first binary tree. // // 10 // / \ // 20 30
This is a naive way to create a binary tree. There are many far better ways to create a binary tree. We will discuss some of them as we move on.
There are four basic operations Create, Read, Update and Delete(CRUD), which are performed on every data structure. Let’s perform them on Binary Tree as well. At first, we’ll start with the “Read” operation cause it’s relatively easy(a million thanks to recursion). Also, it will strengthen our bond with the binary tree.
Traversal
Reading data from a data structure is also known as traversal. As we know Binary Tree is a non-linear data structure. So its data can be traversed in many ways. In general, data traversal for trees is categorized as Breadth First Traversal(BFS) aka Level Order Traversal and Depth First Traversal(DFS).
Note. These traversal methods are not specific to binary trees. They can be used for any tree. But, for brevity, we’ll only discuss them for binary trees.
Depth First Traversal
In depth-first traversal, we start with the root node and go into the depth of it. We dive deep as much as possible until we reach the end. Once we reach the bottom i.e. the leaf node, we backtrack to traverse other nodes. It’s really important to notice that while diving or backtracking, how are we dealing with the root node or the node acting as root node? Are we traversing root node before diving? Are we traversing root node after backtracking? Answer of these questions leads to 3 new categories of depth-first traversal in-order, pre-order and post-order. I hope I my poor articulation is not confusing you.
Inorder Traversal
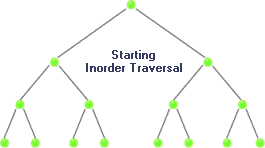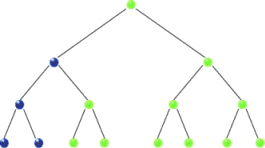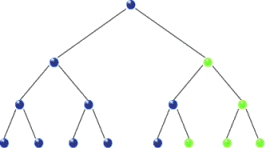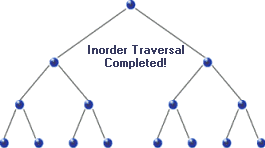
For in-order traversal, we start with the root node and go to the left of the tree as far as possible until we reach the end or leaf node. If there’s any leaf node, we read its data and backtrack to the immediate parent node or root node. Otherwise, we simply read data from the root node and move the right child, if there’s any, and repeat the same for the right node. The traversal sequence for in-order is left-root-right. Here are some sample binary trees which we will use for traversing.
Sample binary trees
====================
1) 2)
----- ------
a j
/ \ / \
b c f k
/ \ \
a h z
For tree 1) and 2), in-order traversals will be b-a-c and a-f-h-j-k-z. Let me explain how we got them. For tree 1), we start with its root node i.e. node a and move to the left that is node b. Then we again move to the left of node b. Since there’s no node to visit which means we have reached to the farthest left. We read/print its data and move back(backtrack) to the root node a. We read data from it and move to its right child that is node c. and repeat the same for it. Similarly, we can traverse tree 2).
Let’s see how does it look in the code.
/**
* Prints the values of binary tree in-order.
*
*/
const traverseInorder = (root) => {
if (root === null) {
return;
}
// Traverse the left node.
traverseInorder(root.left);
// Print root node's value.
console.log(root.value);
//Traverse the right node.
traverseInorder(root.right);
};
We learned from our previous post that trees are recursive in nature. So we leveraged their recursiveness and wrote a recursive function traverseInorder which traverses a binary tree in order. As we know that for every recursive solution there’s an equivalent iterative solution. And we can go with the iterative solution as well but to keep it simple we will continue with recursion and will discuss the iterative solution on some other day.
In-order traversal is commonly used for binary search tree cause for BST it retrieves data in sorted order.
Preorder Traversal
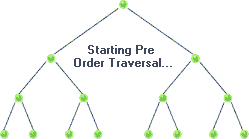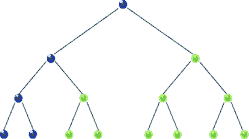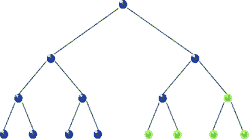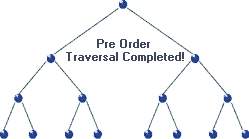
Pre-order traversal is similar to in-order. The only difference is we traverse the root node first then, we move to the left and the right child. The traversal sequence is root-left-right. For tree 1) and 2) in our boring example pre-order traversals are a-b-c and j-f-a-h-k-z. Here’s the Js code.
/**
* Print the values of binary tree in pre-order.
*
*/
const traversePreOrder = (root) => {
if (root === null) {
return;
}
// Print root node's value. console.log(root.value);
// Traverse the left node. traversePreOrder(root.left);
//Traverse the right node. traversePreOrder(root.right); };
If you look at the code, you’ll realize that we have only changed the order of statement compared to in-order traversal. And that’s all is required.
Postorder Traversal
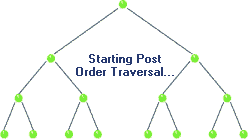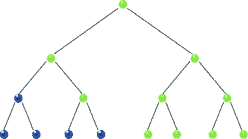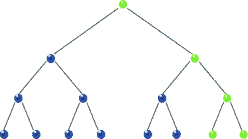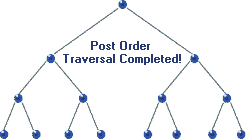
In post-order traversal, we traverse the root node in the end. The traversal sequence is left-right-root. For tree 1) and 2) post-order traversal will be b-c-a and a-h-f-z-k-j. Js code:
/**
* Print the values of binary tree in post-order.
*
*/
const traversePostOrder = (root) => {
if (root === null) {
return;
}
// Traverse the left node. traversePostOrder(root.left);
//Traverse the right node. traversePostOrder(root.right);
// Print root node's value. console.log(root.value); };
Breadth First Traversal
In the breadth-first traversal, we traverse tree horizontally i.e. we traverse tree by levels. We start with the root node (or first level), explore it and move to the next level. Then traverse all the nodes present on that level and move to the next level. We do the same for all remaining levels. Since nodes are traversed by levels, so breadth-first-traversal is also referred as Level Order Traversal. Here’s an illustration.

We accomplish level order traversal with the help of a queue. We create an empty queue and enqueue the root node. Then we do the followings, while the queue is not empty.
1. Dequeue a node.
2. Explore the node.
3. If the node has a left child, enqueue it.
4. If the node has a right child, enqueue it.
/**
* Traverses binary tree in level order.
*
*/
const levelOrder = (root) => {
if (root === null) {
return;
}
const queue = [root];
while (queue.length) {
const node = queue.shift();
// pirnt/explore node.
console.log(node.value);
// enqueue left
if (node.left !== null) {
queue.push(node.left);
}
// enqueue right.
if (node.right !== null) {
queue.push(node.right);
}
}
};
Create
There’s no restriction on the data stored in a binary tree which gives us the flexibility to create it. We will discuss following two popular methods to create a binary tree:
1. From array representation.
2. Level Order Insertion.
From array representation
A binary tree can also be represented using an array. For child i, in the array representation, the left child will be at 2*i + 1 and the right child will be at 2*i + 2. The index of the root node is 0. Here’s the JS code to create binary tree from array representation.
/** * Creates a binary tree from it's array representation. * * @param {any[]} array */ const createTree = (array) => { if (!array.length) { return null; } const nodes = array.map( (value) => (value !== null ? new BinaryTreeNode(value) : null) ); nodes.forEach((node, index) => { if (node === null) { return; } const doubleOfIndex = 2 * index; // Left node -> (2 * i) + 1. const lIndex = doubleOfIndex + 1; if (lIndex < array.length) { node.left = nodes[lIndex]; } // Right node -> (2 * i) + 2. const rIndex = doubleOfIndex + 2; if (rIndex < array.length) { node.right = nodes[rIndex]; } }); return nodes[0]; }
Let’s consider an array and use above function to create a binary tree.
const array = [1, 2, 3, 4, 5, 6]; const tree = createTree(array); console.log(tree);
// Tree represented by array. // 1 // / \ // 2 3 // / \ / // 4 5 6
Level Order Insertion
In this approach, we insert an item at the first available position in the level order.
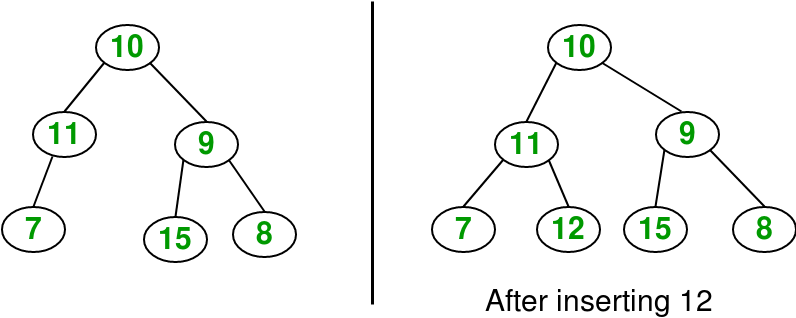
Since we are inserting values in level order, so we can use iterative level order traversal. If we find a node whose left child is null then we assign a new node to its left child. Else if we find a node whose right child is null then we assign a new node to its right child. We keep traversing until we find a left or a right null/empty child. Here’s the JS code for level order insertion.
/**
* Insert the value into the binary tree at
* first position available in level order.
*
*/
const insertInLevelOrder = (root, value) => {
const node = new BinaryTreeNode(value);
if (root === null) {
return node;
}
const queue = [root];
while (queue.length){
const _node = queue.shift();
if (_node.left === null) {
_node.left = node;
break;
}
queue.push(_node.left);
if (_node.right === null) {
_node.right = node;
break;
}
queue.push(_node.right);
}
return root;
}
Update
Updating a value of a node in a binary tree is relatively easy, cause values stored in a binary tree doesn’t have to maintain any specific tree property. To update the value, we simply find the node, whose value is being updated, using one of the traversals discussed above and replace its value.
Delete
Deleting a node form a binary tree is not as easy as it seems. It’s because there are so many scenarios which we need to deal with while deleting. Scenarios like:
1. Is targeted node a leaf node?
2. Does targeted node only have a left child?
3. Does targeted node only have a right child?
4. Does targeted node have both the left and the right child?
5. Are we only deleting the node and not its subtree?
6. Are we deleting both the node and its subtree?
To avoid intricacies, we’ll only consider case 6 here i.e. we delete both the node and its subtrees. We’ll discuss other scenarios someday with Binary Search Tree.
To delete/remove a node from its subtree we need the reference of its parent. If the target is on the left of parent then we set left of the parent to null else we set right of the parent to null. We let the garbage collector take care of the reset i.e. removing subtrees and freeing the memory. We are simply setting the reference to null, so it doesn’t matter which traversal we use. We’ll end up with the same result, but time and space complexities may vary. Let’s use Breadth-First Traversal for now.
/** * Removes a node and it's subtrees from a * binary tree. * @param root * @value * * @return updated root. */ const remove = (root, value) => { if (root === null) { return null; } if (root.value === value) { return null; } const queue = [root]; while (queue.length) { const node = queue.shift(); // If target is on left of parent. if (node.left && node.left.value === value) { node.left = null; return root; } queue.push(node.left); // If target is on right of parent. if (node.right && node.right.value === value) { node.right = null; return root; } queue.push(node.right); } return root; };
let tree = fromArrayRepresentation([1, 2, 3, 4]); tree = remove(tree, 2); // Remove 2 and 4(its child of 2). console.log(tree);
Note: If a language(like C or C++) doesn’t have the garbage collector, then we may need to traverse the tree in post-order remove the children first before deleting the targeted node. For more detail please refer here.
Summary
Binary Tree is a special tree in which each node can at most contain two children called left and right. To read/traverse data from a binary tree we have two major approaches Depth-First Traversal and Breadth-First Traversal. Depth-First traversal is further classified in pre-order, in-order, post-order traversal. In depth-first traversal, we visit the node and its children first, then we visit siblings of the node. In breadth-first traversal, we visit the node and its siblings(nodes which are at the same level) first, then we move to the next level. Depth-First traversal is also referred as Level Order Traversal. There are many ways to create a binary tree. One can create a binary tree from its array representation. In array representation value at ith, index will have children at 2*i + 1 and 2*i + 2. A binary tree can also be created using level order insertion where any new value is inserted at first available position in the level order. Updating a value in a binary tree is relatively easy because values in a binary tree don’t maintain any specific property with respect to each other. Among all operations, deleting a node is a bit complicated cause a node may carry children. So we have to take care of its children as well.
I have created a repository on Github which contains the implementation of the binary tree along with many other data structures in JavaScript. Please feel free to fork/clone it. If you have any suggestion or correction, please post them in the comment section. Thank you for reading.
每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;微博:https://weibo.com/openingsource;电报群 https://t.me/OpeningSourceOrg