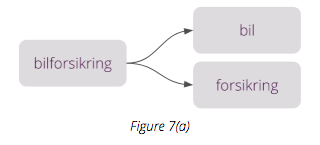
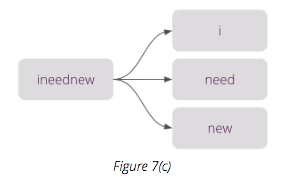
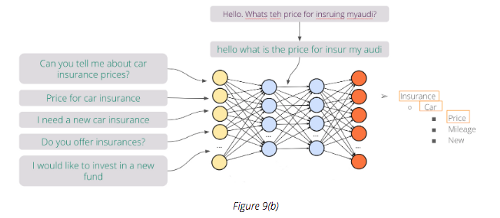
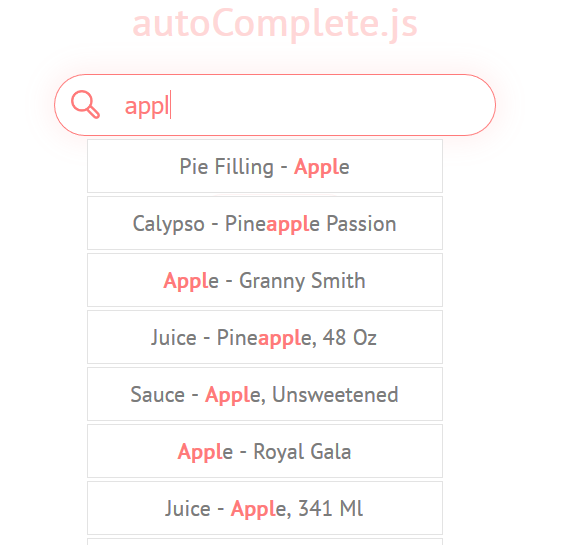
今日推荐开源项目:《自动补全系统已上线 autoComplete.js》
今日推荐英文原文:《Top 3 Best JavaScript Frameworks for 2019》

今日推荐开源项目:《自动补全系统已上线 autoComplete.js》传送门:GitHub链接
推荐理由:写搜索栏的时候兴许会用得上的 JS 库——它会根据你的输入给你提供一个包含可能选项的下拉菜单,这样就不需要再完全输入搜索结果就能够进行操作了。它现在还正在发展中,诸如在显示下拉菜单之后用键盘选择选项这样方便的功能暂时还没有实现,如果对它感兴趣的话可以关注一下它的发展。
今日推荐英文原文:《Top 3 Best JavaScript Frameworks for 2019》作者:Cuelogic Technologies
原文链接:https://medium.com/cuelogic-technologies/top-3-best-javascript-frameworks-for-2019-3e6d21eff3d0
推荐理由:2019 前三名应该使用的 JS 框架,说到这相信有些朋友应该猜到是哪三个了
Top 3 Best JavaScript Frameworks for 2019

Introducing javascript frameworks
Undoubtedly, JavaScript’s (JS) popularity in the developer community has grown exponentially over the years. The reason is its ability to allow developers to design and modify web pages in numerous ways and even add functionalities to real-time web apps. JavaScript is gathering attention not just for its simplicity and ease of use but also due to what it brings to the table — Efficiency, Security, and Low-cost results.
At the same time, advancing technologies are pushing techies to add new skills to their repository for JS. It goes without saying that the market of JavaScript libraries/frameworks is a bit messy today. There is a lot of noise with in terms of available options and developers often need to test the waters by learning multiple libraries/frameworks to determine the best one.
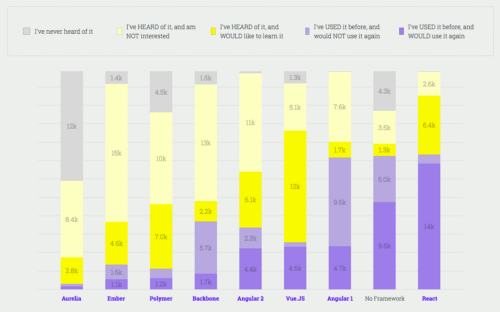
Consider the popular State of JS Survey of 2018 that gives an account of the number of libraries that developers are currently using:
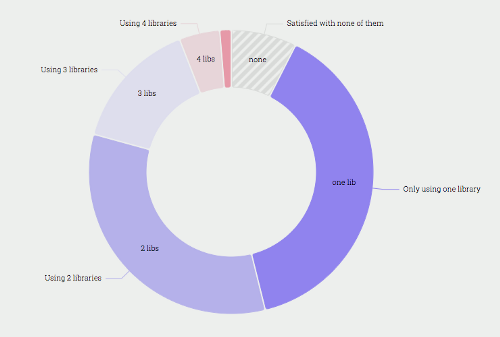
Although there are many libraries available today, survey results prove that Vue, React, and Angular continue to be the market leaders.
1. Vue.js
Vue became the most popular front-end GitHub project in 2018, a feat that has followed the framework in 2018 with 117k stars and more than 29k forks (at the time of writing). Created by Evan You who worked on numerous Angular.js projects during his time at Google, Vue.js is a lightweight counterpart of Angular.js and is also proving to be an attractive alternative to it.
One of the main reasons why developers love Vue is because it is a progressive framework. This means that it elegantly adapts to the needs of the developer, starting from 3 lines to managing your entire view layer. VueJS can be quickly integrated within an app through the ‘script’ tag, where it gradually starts to explore the space.
But Vue particularly works because it picks up the best choices and possibilities that frameworks such as Angularjs, Reactjs, and Knockout provide. This makes it the best version of all frameworks put together in a neat and tidy package that delivers.
Let ‘take a look at the pros and cons of developing with Vue.js
Pros of Vue.js
- Size: This is one of the best highlights of Vue. The production ready build of Vue is surprisingly lightweight — just 18kb after zipping. This provides it with a much-needed speed and accuracy as compared to other major frameworks. At the same time, even the ecosystem around Vue is small and fast as it allows users to separate the template-to-virtual-DOM compiler as well as the run time.
- Integration Capability: Vue offers one of the best integration capabilities since it can be used to build both single-page applications and complex web applications. Small interactive parts of the framework can be easily integrated with other frameworks/libraries such as Django, Laravel, and WordPress.
- Scalability and Versatility: You can use Vue both as a library or as a fully-fledged framework. Vue can be easily used to develop large and reusable templates with minimal fuss, owing to its simple structure.
- Adaptability: Most of the developers who adapt Vue switch to it from other major frameworks. The switching period often comes about to be swift because of the similarity of Vue to React and Angular.
- Readability: Vue is quite easy to read and understand for developers since functions are highly accessible. Additionally, HTML blocks handling can be optimized with a usage of different components.
Cons of Vue.js
+ Lack of Resources: Due to the small market share at the moment, Vue still has a long way to go. The relative age has also added to the woes around common plugins, which makes working with external tools a bit difficult.
+ Quick Evolution: While a swift development phase is good for a framework is good in terms of capabilities, the learning curve keeps on changing. As a result, online resources can end up being outdated and the documentation can sometimes be the only resource for developers.
+ Reactivity Caveats: The documentation clearly states some reactivity caveats such as directly setting an item from an array. This can either be done by using items[key]=value or adding a new data property. So, this needs to be effectively handled in the development process.
2. React.JS
React is another popular JavaScript library which powers Facebook. Developed and open sourced by Facebook in 2013, it quickly rose to prominence for the development of huge web applications that involve dynamic handling of data.
In Jan 2019, Facebook extended its support to the library by moving the create-react-app (CLI tool to help create React app) from incubation to the official Facebook repository.
One of the main cases where React finds extensive usage is when developers need to break down complex codes and reuse them in an error-free environment that has the capability to handle real-time data. Elements related to lifecycle hooks such as decorators, help to enhance the user experience.
React makes use of virtual DOM that helps it to integrate with any application. It also adopts JSX to structure components and helps to develop more SEO friendly web pages as compared to other JS libraries/frameworks.
To help you pick the best library/framework for your needs, let’s take a look at the pros and cons of React.js Development:
Pros of React.js
+ Ease of Learning: React showcases simplicity in terms of its syntax that involves a lot of HTML writing skills. Unlike Angular that requires a steep learning curve of being proficient in TypeScript, React’s dependency on HTML makes it one of the easiest JavaScript libraries to pick up.
+ Library, not Framework: React is a JavaScript library instead of a framework. This means that it provides a declarative method of defining UI components. It can also be easily integrated with other libraries. For instance, the React-Redux library provides the necessary glue between React and Redux libraries.
+ Data and Presentation: React provides total separation of data and presentation layers. Though it does have the concept of ‘state’, it is best used for storage that lasts for a very short span of time.
+ DOM Binding: Developers do not have to go through the pain of binding DOM elements to functionality. React handles this by splitting the binding across multiple areas of the code with only the responsibilities.
+ Reusable Components: Facebook has developed React in a way that it provides the ability to reuse code components of any level anytime. This saves a lot of time during development. This ability mainly adds to design efficiency and makes it easy for developers to handle upgrade since any change made to one component has no effect on the other.
+ Unidirectional Data Flow: React utilizes downward data binding. This helps to make sure that any changes made to child structure do not end up affecting their parents. This makes the code more stable and all the developer needs to do to change an object is modify its state and apply updates.
Cons of React
+ High Development Pace: The environment of React is very dynamic and keeps on changing constantly. This puts an added responsibility on developers to keep brushing up and learning new skills. This might be a headache for developers who are just starting out.
+ JSX as a Barrier: React actively makes use of JSX, which is a syntax extension that allows mixing of HTML with JavaScript. Although JSX can protect the code from injections (among other benefits), it does involve a high level of complexity and a steep learning curve.
+ SEO Issues: Users have reported issues regarding SEO since search engines poorly index dynamic web-pages with client-side rendering. Although opinions are mostly speculative, experts recommend that developers learn how the crawlers of Google and other search engines experience them.
3. Angular.JS
Angular is considered to be one of the most powerful open source frameworks. It is an “all-in-one” solution that aims to provide developers with every possible option out of the box. From Routing to HTTP requests handling and the adoption of TypeScript, everything has been set up.
Although the learning curve of Angular was quite steep in earlier versions, it has smoothened out in the latest version of Angular 5 and 6. This has been made possible through a robust CLI, which has taken away the need to know the low-level details for simple apps.
Developed and maintained by Google, Angular has followed the schedule of releasing new versions every 6 months. The latest releases have mainly focused on the addition of new features and improvement of performance.
Here is a look at the pros and cons of Angular.JS Development:
Pros of Angular 5
+ Documentation: Angular 5 comes with a detailed documentation. This makes it easier for new developers to pick up the framework and also understand the code of other projects as compared to earlier versions of Angular.
+ Simpler PWA: Progressive Web Applications have risen in popularity and the Angular team has been swift to integrate the capability within the framework. It is also possible with Angular 5 to get the features of native mobile applications.
+ Build Optimizer: The Build Optimizer in Angular 5 removes all the unnecessary runtime code. This makes the application lighter and faster since the size of the JavaScript in the application reduces.
+ Universal State Transfer API and DOM: Angular 5 has been introduced with Universal State Transfer API and DOM support. This helps to share the code between the server and client-side versions of the applications. This helps to improve the perceived performance of the application.
+ Router Hooks: Router cycles can now be tracked from the start of running guards till the activation has been completed.
+ Data Binding and MVVM: Angular 5 allows two-way data binding. This minimizes the risk of possible errors and enables a singular behavior of the app. On the other hand, the Model View View Model capability allows developers to work separately on the same app section with the same set of data.
Cons of Angular 5
+ Complex Syntax: Just like the first version of Angular, Angular 5 also involves a complicated set of syntax errors. Although the silver lining is that it makes use of TypeScript 2.4, which is less difficult to learn as compared to other Angular versions.
+ Migration: Migrating the app from old versions of Angular can be an issue, especially for large-scale applications.
+ High Churn: Although Angular is quite popular in terms of usage, it is also known to clock the most level of churn. This might be due to the steeper learning curve as compared to other popular alternatives available today.
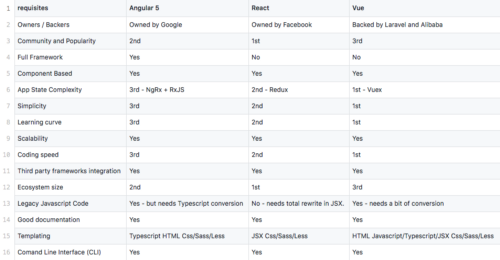
Comparison Table — Angular 5 Vs React Vs Vue
Here is a consolidated look at the comparison of the 3 most popular JavaScript Frameworks/Libraries of 2019 to give you a bird’s eye view of how things stand:
Conclusion
All 3 frameworks/libraries are quite popular today and are backed by a healthy ecosystem and team of developers. There is no right answer and it all comes down to your personal choice and programming style as each framework involves a different development philosophy. Whatever the case, React, Vue, and Angular continue to dominate the world of JavaScript.
下载开源日报APP:https://opensourcedaily.org/2579/
加入我们:https://opensourcedaily.org/about/join/
关注我们:https://opensourcedaily.org/about/love/










 Chatbots, virtual assistants and digital advisors — or whatever you choose to call them — are built to serve the same purpose, but they have to be built with the proper components to successfully deliver lasting business value.
Chatbots, virtual assistants and digital advisors — or whatever you choose to call them — are built to serve the same purpose, but they have to be built with the proper components to successfully deliver lasting business value.