今日推荐开源项目:《什么都有一点 water.css》
今日推荐英文原文:《9 Ways to Improve Your Google Search Results》

今日推荐开源项目:《什么都有一点 water.css》传送门:项目链接
推荐理由:这个项目是一个简单的 css 库,对于那些简单的 HTML 页面来说,这个库可以从各方面都对其显示的效果进行一点简单的改造,最后达到一个简单的好看的效果——不管是各种表单控件还是斜体黑体各种样式的文字,连表格都提供了美化样式,而这些都只需要简单的引入这个库即可实现。
今日推荐英文原文:《9 Ways to Improve Your Google Search Results》作者:Ali Haider
原文链接:https://medium.com/better-programming/9-ways-to-improve-your-google-search-results-9b1a03bad645
推荐理由:求人先求己的第一步就是学会查谷歌
9 Ways to Improve Your Google Search Results
Knowing how to Google for answers is a key part of any dev’s job
Google is a powerful tool, but you’re missing out on a lot of that power if you simply type words into it. Today, we will remove the training wheels and unleash Google’s true potential that you have not seen before. We all type phrases into Google, then it shows results, and we search through them. This is the incorrect way — or rather inefficient use of mighty Google. But why is just typing words into Google not that great? On average, over 3.8 million searches are being made every minute. Google has the difficult task of catering to all these people from different parts of the world, of different ages, and with different needs. Google somehow has to keep them all happy. So it averages out the results or, in other words, shows a wide range of results. You will get search results by the method mentioned above, but they won’t be tailored to your needs. As a result, you will keep searching forever or miss out on the best results. The algorithms behind Google’s searches can lead to a lot of irrelevant results. But this is what we will uncover today: how to use appropriate operators to get the results we truly need and weed out the rest.1. Outdated Results
If you are searching for something related to technology or computer science, you need to have the latest results in front of you. Surprisingly, Google will sometimes return results that are a decade old. Here is a simple and quick solution:- Go to “Tools.”
- Click on “Any time.”
- Click on the past year or whatever you prefer.
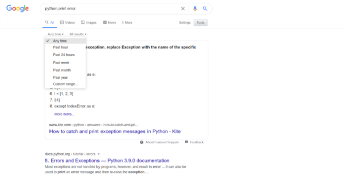
2. Exact Phrase
This is a powerful technique in which you narrow down the results, thus obtaining the best ones. To search for exact phrases, wrap your words in double quotes (e.g. “Python”). This way, Google will precisely search for that word only. The main difference between just typing straight away and using an operator is that you will get a wide variety of results when you type directly. The results might be irrelevant. When you are confident that you know what you are looking for, wrap your phrases in double quotes and see the difference.3. Search for Specific File Type
Sometimes, you need a PDF, JPEG, or flash file. You can use the filetype: operator. For example, if you were searching for a PPT file: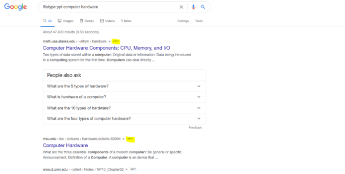
4. Search From a Specific Site
This is something I use very often and absolutely love. Suppose you love a website and want the result from that website only. Or you trust a website, it has authority, and you know you will get the best information regarding your query from that specific website. Then you can use the site: operator. Whenever I have any doubt regarding any computer science concept, I usually refer to medium.com to get accurate and top-notch content in seconds: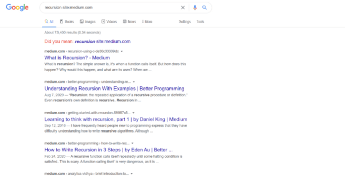
5. The * Operator
Often, we don’t remember the information completely — be it a name or lyrics. By using the * operator, we can let Google know that the information is missing in between. Google then takes appropriate action.6. Exclude Words With a —
If you don’t want specific words to appear in the search results, use this operator by starting with a dash.7. The or Operator
This operator is used to search for more than one phrase. This gives additional words for Google to look for. To use it, write your phrases on either side of “or.”8. Compulsory Word
This is a convenient and powerful operator that I use quite often. While performing a Google search, you can tell Google to place great importance on specific words and include them as a requirement.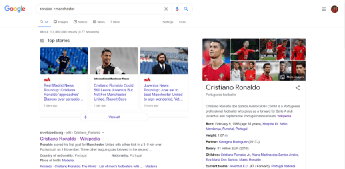
9. Search for a Definition
Looking for a definition of something is common on Google. To return results with a definition, use the define: operator: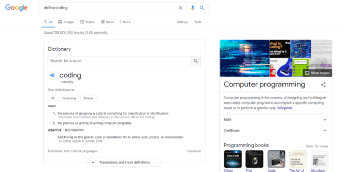 Thanks for reading!
Thanks for reading!
下载开源日报APP:https://opensourcedaily.org/2579/
加入我们:https://opensourcedaily.org/about/join/
关注我们:https://opensourcedaily.org/about/love/