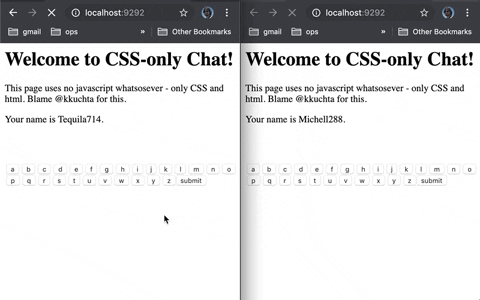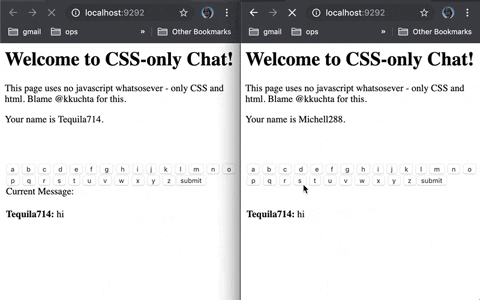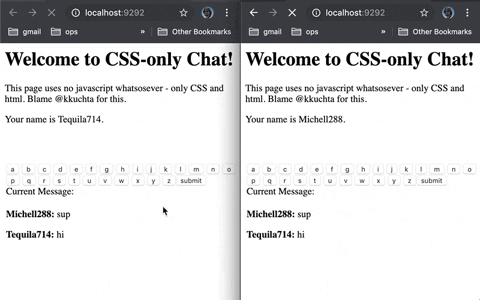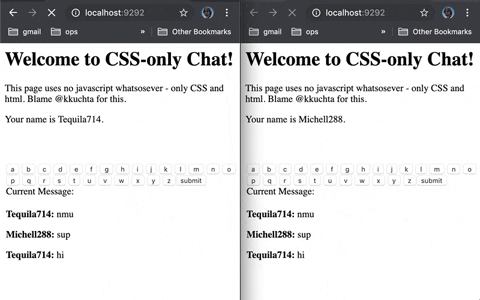
今日推荐开源项目:《提供各种语言 learnxinyminutes-docs》
今日推荐英文原文:《How Much Employee Surveillance Is Too Much?》

今日推荐开源项目:《提供各种语言 learnxinyminutes-docs》传送门:GitHub链接
推荐理由:一个各种编程语言学习资料的合集项目。这个项目最大的特点就在于它不限制于语言,教程提供了各种语言的版本,只要筛选一下就能轻松找到相应语言——不过有的时候比起看翻译版,看原版会更加准确,而且并不是什么时候都有中文翻译版本的,在大部分时候拿时间学个英文比等着中文翻译快得多。
今日推荐英文原文:《How Much Employee Surveillance Is Too Much?》作者:Brian McIndoe
原文链接:https://medium.com/future-vision/how-much-employee-surveillance-is-too-much-bec1d249a4b5
推荐理由:AI 如果用于对员工的监控,将可能引发新的道德问题
How Much Employee Surveillance Is Too Much?
On accepting an offer of employment, we expect that many of our privacy rights will be relinquished when using company systems. We are told that business email is company property and may be read by management. Web surfing is logged, and excessive non-business usage could be held against you. Company phone and voicemail are also subject to surveillance. This has been the case for decades and should not come as a surprise.What may be a surprise though is the scale and power of the data collection, analysis, and prediction capabilities that companies are now deploying, that go way beyond traditional workplace monitoring.
A new terrain littered with potential minefields
The conventional way to gauge employee satisfaction with workplace conditions, compensation, benefits, and management, has been a survey, administered periodically by the HR department. While survey data may be informative, it’s giving way to real-time, automated data collection with sensors embedded directly in employee workstations and conference rooms. Machine learning and other AI techniques are used to make inferences about employee behavior and predict future events.This new direction is known as people analytics and it’s become big business. Vendors are in a gold rush to supply organizations of all sizes with this technology, claiming it helps optimize workforce productivity, fosters collaboration, increases happiness and well-being while improving retention.
A bold new world has opened up for the HR department, but it’s a potential minefield for employers who fail to take ethical considerations into account and see it as a way to apply pressure to employees.
Implementation of people analytics is occurring far faster than regulations governing its use can be developed. To his credit, President Trump recently signed an executive order calling for government agencies to start work on an AI Initiative and highlighted civil liberties as an area that needs to be thought through. His directive, however, has received criticism for lack of funding and being light on details.
Several 2020 presidential candidates have stepped forward voicing concerns about the impact of workplace AI. At his announcement address, Senator Bernie Sanders said:
“I’m running for president because we need to understand that artificial intelligence and robotics must benefit the needs of workers, not just corporate America and those who own that technology.”Senator Kamala Harris, in letters to government agencies, has expressed concern about biased algorithms, particularly those behind facial recognition systems, stating:
“While some have expressed hope that facial analysis can help reduce human biases, a growing body of evidence indicates that it may actually amplify those biases.”Andrew Yang has an apocalyptic vision for the mass adoption of AI in the workplace. He sees it as part of the greatest economic transformation in world history:
“…the worst case scenario, unfortunately, is chaos, violence, and a disintegration of our way of life.”Many others are sounding the alarm on what they see as a Pandora’s box of potential employee abuse. The IEEE formed a Global Initiative which published guidelines and general principles on how autonomous and intelligent systems should be integrated into the workplace. The AI Now Institute, established to research the social implications of AI, recently published an article on diversity issues and discrimination in AI.
Vendors have expressed a mix of excitement and trepidation about the potential of people analytics. Dr. Louis Rosenberg, CEO of Unanimous AI, in a recent interview, said,
“These tools will not just be documenting what we say and what we type, but will be observing our reactions, predicting our next steps and tracking the accuracy of their forecasts, even documenting our moods.”He followed up with,
“Unless regulations prevent it, AI-enabled virtual assistants will become the eyes and ears of HR departments, disseminating data on the work habits and enthusiasm of employees.”
A new form of Capitalism?
Since the industrial revolution, capitalism and technology have formed a symbiotic relationship, exploring new areas of profit maximization. The latest evolution has been given the designation “Surveillance Capitalism”, a term coined by Shoshana Zuboff in her book, The Age of Surveillance Capitalism. Zuboff, in an interview with The Harvard Gazette, defines surveillance capitalism as,“…the unilateral claiming of private human experience as free raw material for translation into behavioral data.”Vivid examples of this occur on the web. Who hasn’t had the experience of searching for a consumer item, then being peppered with ads for that item for days on end?
In a recent interview with the Guardian, Zuboff illustrated developments claiming,
“Once we searched Google, but now Google searches us. Once we thought of digital services as free, but now surveillance capitalists think of us as free.”This new strain of capitalism has made the jump from commercialism to the workplace in the form of people analytics, raising profound implications for how behavior can be manipulated for organizational ends. Zuboff relates a conversation she had with a data scientist who said,
“We can engineer the context around a particular behavior and force change that way… We are learning how to write the music, and then we let the music make them dance.”
New ways to collect, analyze and predict using employee data
A question we must all confront is how intrusive would technology have to be before we say — enough? This is the reality many now face in their work lives and is likely to become more so in our private lives, as we let more intelligent gadgets with embedded sensors into our homes and cars. Are we moving by stealth toward a future similar to China’s notorious social credit system?Known for pushing the edge of technology, Amazon is now marketing it’s Alexa voice-activated devices to business. The creative ways in which this technology could be used are stunning. Virtually every conversation in an organization can now be recorded, analyzed and inferences drawn about participants. Discussions can be scrutinized for tone and sentiment, dominant players can be sifted from the followers.
Vendors market these tools as a better way to identify key individuals and more efficiently distribute tasks to reduce stress and overwork. A UK based company, Status Today, sells a product called Isaak, with 820 companies as clients. Featured in a recent article, Isaak’s developers say it offers companies,
“real-time insights into each employee and their position within the organizational network.”Though the CEO admits that “there’s always a risk that it might be misused”, should employers decide to apply it only to boost productivity while ignoring wellbeing.
Companies implement security barriers to protect both property and employees, with access usually controlled by a security badge. Humanyze, the creation of two former MIT students, has morphed the common old security badge into a smart badge, equipped with powerful monitoring features.
Digital Trends describes the capabilities of these smart badges as including “radio frequency identification (RFID) and near field communications (NFC) sensors … Bluetooth, an infrared detector capable of tracking face-to-face interactions, an accelerometer, and two microphones.” The office space is equipped with beacons that detect an employee’s location. The company stresses that the data collected by this technology, up to 4GB per day per employee, is aggregated and anonymized before being sent to management.
Ben Weber, CEO of Humanyze, points to unexpected learnings that have come about from performing analysis of the data collected. As an example, one client,
“discovered that coders who sat at 12-person lunch tables tended to outperform those who regularly sat at four-person tables.”Larger lunch tables were “driving more than a 10% difference in performances”. A fact that would probably have gone undetected without such data analysis.
The unintended consequences of total employee surveillance
 Credit: Unsplash
Employee well-being and reduced stress are touted as a benefit of increased workplace surveillance. One can’t help wondering whether employee knowledge of the vast quantities of data vacuumed up and picked over by proprietary algorithms, will lead to outcomes opposite of those intended. No one likes to be micromanaged, and these developments appear to take it to a whole new level. This thought is articulated by Ursula Huws, a professor at the University of Hertfordshire in the UK, who said,
Credit: Unsplash
Employee well-being and reduced stress are touted as a benefit of increased workplace surveillance. One can’t help wondering whether employee knowledge of the vast quantities of data vacuumed up and picked over by proprietary algorithms, will lead to outcomes opposite of those intended. No one likes to be micromanaged, and these developments appear to take it to a whole new level. This thought is articulated by Ursula Huws, a professor at the University of Hertfordshire in the UK, who said,
“If performance targets are being fine-tuned by AI and your progress towards them being measured by AI, that will only multiply the pressure.”Meetings, often the bane of corporate life, are likely to become even more vexing as participants, aware that their words and gestures are being dissected, rated and ranked, jostle for dominance. At least some of them will, others are likely to tune out the noise and plot their escape. The software development business, where Asperger’s and personality quirks are legion, may have a difficult time adapting to the level of monitoring and assessment afforded by these technologies. It remains to be seen whether companies that offer a surveillance-free environment, end up having an edge in recruiting and keeping top technical talent.
Ethical issues will dominate as the power and scale of this technology grow. Much needed clarification on the inherent privacy issues and development of regulations to set limits, will no doubt be fodder for many future court cases.
下载开源日报APP:https://opensourcedaily.org/2579/
加入我们:https://opensourcedaily.org/about/join/
关注我们:https://opensourcedaily.org/about/love/