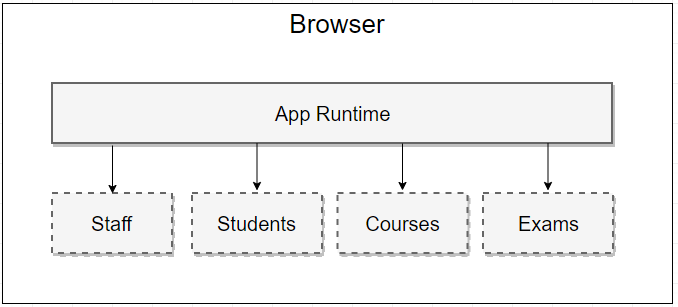
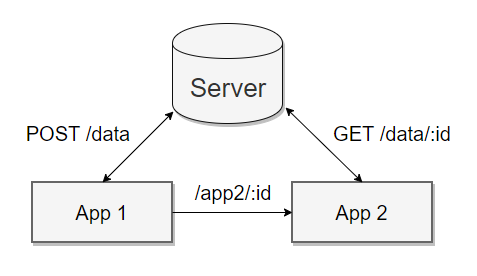
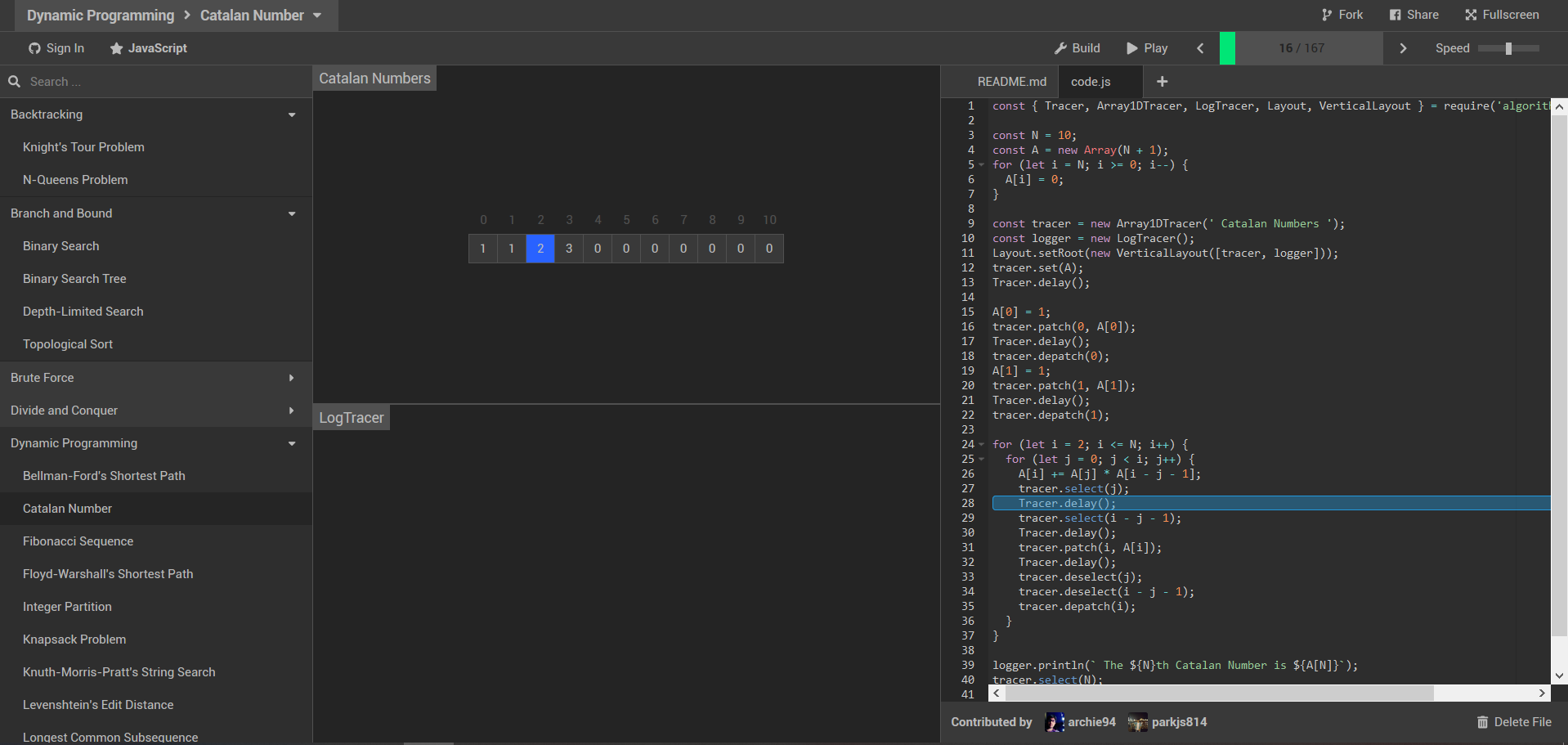
今日推荐开源项目:《百闻不如一见 algorithm-visualizer》
今日推荐英文原文:《Pair Programming: The Good, The Bad, and The Ugly》

今日推荐开源项目:《百闻不如一见 algorithm-visualizer》传送门:GitHub链接
推荐理由:对于简单的算法,我们可以在头脑里画图;复杂点的,在纸上一步步记下来对着看;再复杂点的……而这个项目提供了一些算法的可视化——不是一次运行到底而是一步步的走下去,每一步的变化都会在图中呈现出来,对于理解算法相当有帮助。
今日推荐英文原文:《Pair Programming: The Good, The Bad, and The Ugly》作者:Justin Travis Waith-Mair
原文链接:https://medium.com/the-non-traditional-developer/pair-programming-the-good-the-bad-and-the-ugly-5fc3f9c3663c
推荐理由:配对编程的优缺点,兴许你可以看看我们之前介绍配对编程的文章(传送门)(传送门)。
Pair Programming: The Good, The Bad, and The Ugly
When I started at my first dev job, there was only one way to program: Put your head down and write code. Every so often, I would collaborate with a team member for short bursts, but coding typically happened on my own using my own machine.Then I found out about a company that boasted that it did 100% “Pair Programming.” What is pair programming? Pair programming is when two people sit at one machine and code together on the same problem. It’s like the collaborations that I was talking about earlier, but instead of being the exception, it was the norm. It was a concept that intrigued me.
I later found out that that statement wasn’t accurate, but why it wasn’t was because this company didn’t just practice pair programming, it also practiced what is called mobbing. Mobbing is just like pairing, except for instead of just two individuals, you would have 3+ people all working together on the problem. Code review, typically in the form of a pull request, did exist as well but they are typically a small minority.
Why would a company advocate to work this way? What are the advantages it gives? As I researched it more I found articles and studies that boasted of the benefits of paired programming, but they all pretty much came down to one major reason: It results in fewer bugs that make it to production. The theory is that my worst day would at least partially be drowned out by your good and vice versa.
The concept was intriguing and when I decided to start looking for new opportunities, I decided to apply to this company and was eventually offered a position there. I was on a team that paired almost exclusively and I loved working with my team there. After a year I was ready for a new opportunity and accepted a new role at a new company.
Having now worked in the two environments, I thought it would be helpful to share my thoughts on what paired programming was like as a developer and if I would ever advocate for it again.
The Good
Even though paired programming sounds, “slow”, I felt I got a lot done when I was pairing. When pairing you tend to stay on task and even if someone needs to take a quick break here and there, the other can forge on ahead, know that the partner won’t be gone very long to check on their work. Given all that, I feel that pairing more than compensates for the being “slower” in the actual coding.I never felt lost in the code base when I was pairing. I had a friend that, when he was hired on in his first Senior role, felt extremely lost. He was given a very high-level rundown of the code base and then given tasks to complete on his own. When he would try to ask for help, he was told he was taking to much of their time and that as a “senior” he should be able to figure this out. Now, this might be an extreme example of what not to do, pairing would have helped my friend out as he was learning how the codebase worked.
Pairing helped facilitates knowledge transfer. Domain knowledge, coding tricks, and so on. When two or more people are working on it then there is more knowledge about what is happening spread across the team and you don’t have to worry about people leaving and taking important information with them.
I got to know the people on my team very well. It forced me to be social and not isolate myself. People who know me well are sometimes surprised that I have battled with shyness all my life. It’s not debilitating, but I can easily close myself off from a group. Pairing didn’t let me do this and I felt a part of the team quickly. This isn’t something that happened exclusively because of pairing, but I feel it definitely helped.
The Bad
Pairing isn’t all roses. There were downsides to pairing, from a developer’s point of view. One of those was the lack of “home base”. In a team, you are often changing partners and therefore you or your pair will need to trade desks to facilitate that. In this game of musical desks, you tend to pack minimal and light. This keeps you from feeling like you have a “home base” that is all your own.As I stated earlier, pairing tends to push you to be on task. This means you don’t often feel like you can take small detours and “play.” I never wrote code just for fun. I didn’t feel like I could go do some personal exploration around a subject just to see if it would work, even if I had no intention of doing that in production. Experimentation is a very important part of a developer’s continued education and when one feels like they can’t do it, then you feel like you are a “code monkey” coding up whatever someone tells you to do.
Another bad thing is that socializing can be draining. Some people thrive off of social interaction, while others avoid it at all cost. All of us fit in that spectrum and can find it exhausting to always be pairing. Our team tried to “scratch that itch” by setting aside every Monday as a solo work day. This did help, but there were times I just wanted to go out on my own and felt trapped when I didn’t feel I could.
The Ugly
Besides the good and bad, there is also an ugly part of pairing. The first is that dominant personality, intentionally or not, push non-dominate personalities around. There is a saying, that we should have “strong opinions, loosely held.” Some personalities will end up holding their opinions “looser” than others. Yes, this can happen in any team settings, but when all your interactions are this way, it becomes draining fast.To illustrate this, there is a “pairing best practice” where one person is on the keyboard writing code while the other person “navigates.” The person on the keyboard is supposed to be a “smart keyboard” who codes details, while the navigator tells the smart keyboard what to do, but not how. In practice, I often felt that the person on the keyboard wasn’t a “smart” keyboard. Instead, they ended up being an inefficient keyboard, just doing whatever the other person told them to do.
Another ugly aspect is when you are more invested in pairing than the other. It is draining enough to always be “on” when you are both invested, but when your partner obviously has checked out and is doing their own thing, it wears on you even more.
The Verdict
Now that you know the good, the bad, and the ugly of paired programming, what would I recommend? Yes, I would recommend it and no I wouldn’t. Pairing has its benefits, but it also has its negatives. By choosing to do it exclusively, you are embracing those negatives. It’s just like the old hammer analogy when all you have is a hammer everything looks like a nail. When all you do is pair programming, everything looks like a “pair programming nail.” Instead, I would advise a more “selective pairing process.”First, I would recommend that individuals have their own desk that they can make their home base. When pairing, someone comes to one person’s desk or the other and then everyone goes back to their home base.
Also implied with that last recommendation is that pairing is not something you do all day. Maybe you pair all day one day, none the next, and then pair part of the day, the day after that. One should only pair if and when it makes sense. Maybe you should pair in the morning, separate, and then meet up at the end of the day.
Ultimately, pairing is a good thing and it should be encouraged. Just like anything, when done in excess, the negatives can start to overshadow positives. By using it as a tool only when it makes sense, you can enjoy the benefits while mitigating the negatives.
下载开源日报APP:https://opensourcedaily.org/2579/
加入我们:https://opensourcedaily.org/about/join/
关注我们:https://opensourcedaily.org/about/love/