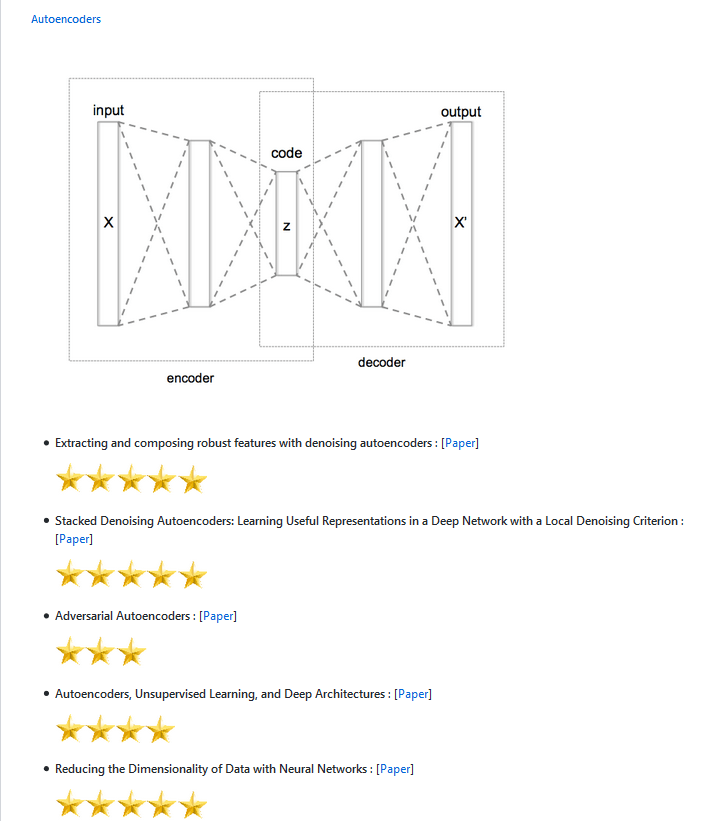
A professor in China builds a brain-machine interface that keeps humans fully in charge.
How do you teach robots to dance? Changle Zhou thinks he can do it by getting the machines to read our minds.
In an experiment that began last year, Zhou, a computer scientist at Xiamen University in China, invited six people to sit at a screen and watch videos of a humanoid robot moving its arms. All of the humans wore an electrode cap that recorded signals from their brains. That let the researchers analyze changes in the activity of “mirror neurons,” which fire when you’re performing certain actions and when you’re observing others perform the same actions.
For the next few years, Zhou and his graduate students will gather more and more of this data from human brains. Eventually, he says, just by thinking about what they want a robot to do, people will be able to instruct machines to make the movements necessary to boogie.
But Zhou’s real objective isn’t just to get robots to fit in on the dance floor. The long-term goal of this research is to figure out the optimal way for humans and machines to communicate at the speed of thought.
Zhou is one of many people trying to develop brain-machine interfaces. But while some projects aim to upgrade the way we interact with computers — letting people type and move a cursor on a computer screen through mind control, for example—Zhou is also trying to also upgrade the computer in the process. It’s a way to get machines to think more like we do and become much more useful.
However, he’s careful to note that his vision for human-computer connections stops short of the one held by people known as transhumanists, who think an upward trajectory of machine intelligence should bring about computers that are adept and perceptive enough to serve as the substrate of human minds. Transhumanists hope to fully merge with these machines, whether it’s to enhance their own biological brains or, better yet, to become immortal. “Why should we be restricted minds?” says Ben Goertzel, a Hong Kong-based AI researcher and chair of Humanity+, an organization that envisions liberating humanity from the constraints of biology using technology.
Zhou doesn’t buy it. Unless advanced quantum computers somehow change everything, he expects machines will remain inferior to human brains — even if they can plug in more directly to us.
Teamwork
Zhou has spent the past 30 years trying to build artificial intelligence that resembles human intelligence as closely as possible. He wanted machines that could understand metaphors, compose music and poems, and perhaps even express emotions. But even though he and others have designed algorithms that can make computers write, draw, and carry out other individual aspects of human creativity, he couldn’t get past the realization that machines can’t have what he considers the highest form of intelligence, something akin to Zen enlightenment. The algorithms that write songs and poems are not able to actually experience the beauty of these works.
Zhou believes that what distinguishes the human mind from other intelligent systems is consciousness of internal experiences, or mental self-reflection. He points to our own subjective experiences of sensory inputs, which are known as qualia. “Humans can feel a sense of happiness because of qualia, not because of high IQ,” says Zhou. “Machines do not have this ability.”
That’s why he started thinking about a hybrid system: a brain-machine interface that could draw on “the intelligence of both people and machines,” says Zhou. “This is the future path.”
In this approach, qualia would be still be left to the humans. In his dancing robot project, a biological brain experiences the charm of the dance, and the robot “brain” is responsible only for carrying out the task. He envisions a slew of applications in which people get enjoyment from seamlessly making a machine do things that they don’t have the physical capacity to perform. But it’s not a two-way street. The robot that reads minds is merely a surrogate for a person’s imaginary actions, and only the human brain gets to have internal experiences.
During a transhumanism conference held by Humanity+ in Beijing recently, Goertzel described ideas that might sound roughly similar. He envisions a machine whose intelligence would be as agile and nimble as a human’s. It’s beginning with a decentralized network of AI algorithms called SingularityNET, and independent developers from around the world can contribute to the network. Eventually, Goertzel imagines, it will evolve into a “self-growing and self-pruning” human-level AI. If we merge our minds with it, we would create a “superhuman AI mind,” says Goertzel.
In that vision, superhuman AI will be the culmination of some ingenious computer engineering, and then humans will want to link their physical bodies with it. But to Zhou, a human-machine collaboration comes first and stays primary. He sees it as the means of creating the best possible AI.
You complete me
There are a few different tools for measuring brain activity, and the invasive ones aren’t likely to attract many volunteer research subjects. So Zhou’s team uses the electroencephalogram, or EEG. The people controlling the robots attach electrodes to their scalps by wearing a cap, and these electrodes measure the strength of the electric fields coming from the brain. To make these signals sharp enough for a computer to pick up and analyze, a white gooey conductive gel is injected in the space between scalp and electrode.
The EEG doesn’t actually provide neuron-level resolution. Instead Zhou’s group uses it to detect very brief oscillations in brain waves as someone imagines and observes certain actions. These signals are good enough for telling a robot whether to move its left or right arm and how high. But they’re not clear enough for the more complex movements that make up the rich repository of dance styles. So these more complex movements still need to be programmed in advance. Nonetheless, training a robot this way can convey aesthetics that are very difficult to write into code, says Zhou.
There are many challenges along the way. Tianjian Luo, one of Zhou’s PhD students, is training an algorithm that can generate high-quality signals out of the noise in EEG readings. That could make it possible for a person controlling the robot to use lightweight equipment rather than being tethered to bulky wires and computers.
Sitting in his cubicle in the lab at Xiamen University, Luo rattles off a number of ways these interfaces could improve people’s lives. Rehabilitation for stroke patients. Controlling prosthetic limbs for amputees. Safer long-distance control of equipment stationed in dangerous areas.
Transhumanists see something even bigger from work like this, though: a new type of consciousness. Not only will people be linked to computers, they’ll be linked to the minds of other people. “We would share experience,” says Natasha Vita-More, the executive director of Humanity+. “It would be very empathetic. Once we are connected more electronically, we will get each other.”
Freedom
If the transhumanist ideal or even something simpler comes to pass, it’s not clear that how much it would expand human possibility in China or any other country that extensively uses computers to conduct mass surveillance and maintain social control. A Chinese project dubbed “Dazzling Snow” aims to build an omnipresent video surveillance network by 2020, covering all corners of China’s public spaces, because security is always more important than individual liberty in the country. To combat toilet paper theft in public restrooms, the Beijing city council has deployed dispensers equipped with face-recognition technology that supplies a limited amount to each person. Given that the Internet has been tamed by the Chinese government into a tool for meeting its social and economic goals, could human-machine mind melds strengthen that power?
Zhou says it’s counterproductive to brood over the potentially dystopian uses of brain-machine interfaces. For one thing, he says, no one is close to extracting a person’s complex, private thoughts by analyzing brain signals. But more broadly, he shrugs off such fears by using a knife as an analogy. Nobody says we shouldn’t make knives because they could be used to kill people. “You’ve got to educate people to use these technologies in the right way,” he says in his office overlooking his idyllic campus, dotted by phoenix palms. “And soothe the human heart.”
It is quite challenging to talk about AI without sounding like a buzzword-spewing technocrat these days. Amidst all the hemming and hawing that companies do to convince themselves that they’re still relevant (wink, wink), we forget that AI has needs too — and soon enough feelings. Let’s not forget that, since how AI learns is a direct reflection of how we treat it. But that aside, let’s look at why taking a holistic, scientifically rigorous approach to data that also accounts for human irrationalities is needed before AI can grow up.
In order to dig into what AI needs, we first need to define what we mean by AI. What businesses call AI often refers to narrow (or weak) AI: playing chess, speech and image recognition, self-driving cars, computer vision, as well as natural language processing and any other tasks that leverage machine or deep learning. When your grandma hears something about AI on the news and thinks that what you’re talking about is general artificial intelligence, you can tell her that a team of AI experts at Stanford issued a press release stating that despite all the amazing strides AI has made in the past years, “computers still can’t exhibit the common sense or the general intelligence of even a five-year-old.”
However, if AI gets all of its needs fulfilled, then it can move — much as humans did — from a very narrow and weak state towards a much stronger and more general intelligence, where each stage of the process requires a new set of needs. The very foundation of these needs begins with high quality data, AI’s basic building blocks of life.
Basic needs: high quality data
At the very basis of AI is data and even more important, quality data. If you don’t get this step right, all the algorithms in the world can’t help you: It will just be garbage in, garbage out. The first step is to figure out what data you actually need to accomplish what you want to achieve: what’s the minimum precision, reliability, and accuracy (validity) that you need as a baseline? What are the tools of measurement that you need to procure this data in an accurate, real-time manner? If you’re using data to optimize your user-facing product, go back to basics.
Human beings are first and foremost emotional decision makers which, according to behavioral economics, makes us seem a bit irrational. We have biases that cause us to use data to prove our own ideas even if we have a scientific education, and regularly make emotional decisions rather than rational ones. Added to that, the context in which we perceive things often changes the actual things themselves. Oh, and finally, our decisions are heavily influenced by our social groups.
The bottom line: Logging behaviors at face value is not enough. In today’s world, almost every form of narrow AI has a human dependency, and you must test and retest using a scientifically rigorous methodology. In the case of consumer facing products, according to neuropsychologists, human observation and data testing alone isn’t enough to accurately measure human beings. You need to get as many valid perspectives as possible on the individuals you’re researching. Think collection methods: sensors, instruments, logging, and a nice constant flow of real-time data with a great filtration (cleaning) system. After all, if learning is the generalization of past experiences combined with the results of new actions, it’s important that the data we ingest helps us be better (more efficient, etc.); that such data is measured and perceived correctly, ensuring any misperceptions are cleaned; and that there is a well-built pipeline to an abundant source that can provide as much real time data inflow as possible.
Test for error: If your instruments are not sensitive enough or if error rates are too high, you can not move forward. Our eagerness to start building algorithms on a poor foundation is the main reason that AI isn’t moving forward.
Keeping safe: it’s about storage.
Clean data with high validity? Check. Reliable intake and pipeline? Check. The next thing you need to consider, once you’ve got the goods, is . . . is it secret, is it safe, are people safe? Your data is highly valuable and in the wrong hands, it could be misused and taken out of context. Anyone using your data should know the risks of what they are working with and what it is for. Max Tegmark has said that “AI safety is the most important conversation of our time.” So seriously. Once you have some great reliable and accurate data,you need to understand what impact it has and whether this data can be used for good or bad.
If you’re an open source kind of person or sharing company kind of organization, great: make sure your documentation around your data, data collection methods, intended usage, and so on is clearly laid out and easily consumable. The bottom line is that before you go on a deep learning dive, you need to understand what the impacts of your intended experiments could yield. People have died because the basic needs of data were not met. The guy speaking out against AI is the same guy who owns a company that killed a guy as a result of AI. Let’s hope that his outspokenness was the result of his genuine concern for humanity and that this stage of AI was given an extra focus after that incident.
The reality is that if AI is not safe, or if it begins to act in ways that are dangerous to humans, it will get shut down just like Microsoft’s chatbot that learned how to be racist from users on Twitter. If AI isn’t safe for humans, it won’t make it to the next stage of its needs. Once the data is procured in a valid way, it needs to be stored safely in a system that can scale in an unlimited way and is highly durable. IBM outlines the five key attributes of data storage for AI.
Social needs: Who are we talking to, calling, and spawning
The social needs of AI can be thought of in the context of which systems are talking together and how. What APIs are you calling? What is the data in vs. data out? How reliable are your data, storage, and learning neighbors? If you don’t thoroughly understand who your future algorithms are about to rub elbows with, you run a risk of compromising what you have built. As Ellen Ullman, a renowned programmer, stated, “when algorithms start to create new algorithms, it gets farther and farther away from human agency.”
Many managers, investors, and the like will push you to call as much data as you can from what is available and build whatever you can as long as it works. Just remember that what is out there might not be as accurate as you’d like to believe, and just because it works does not mean it is ideal. Think of Google Flu: Google Flu failed to predict flu incidence even remotely accurately for 100 out of 108 weeks, despite the wealth of search data and behavioral data that Google collects. Just because a company might say they have flu data, doesn’t mean it’s good flu data. Even if it’s Google.
Learn and grow: giving your AI some esteem
So you’ve made it this far with your pursuits. Great! It’s time to dig into those metrics, segments, aggregates, and get this party started. Machine learning (ML) should never go from 0 to 60. You need to test your hypotheses first. Think of this phase as training, or the first steps of ML with your business or project. You also need to consider your company’s readiness. If you’re expecting to go from hiring your first machine-learning engineer to the terminator, be advised that it’s just not going to happen. Scaling AI efforts within your organization is just as important as culture change efforts: it takes time.
The first stages of ML involve human expertise alongside experimentation: Creating hypotheses based on the data and testing it by having an experimentation framework allows you to deploy incrementally and experiment. This will allow developers to tweak labels, double check data, and get a good idea of how the data works. It also helps the business to see the potential impact. This is a great place to establish baselines to measure future results against. Think logistic regressions or division based algorithms. Start simple. You need to think of cost to the business: what is the cheapest way to validate your hypotheses? I’m pretty sure you’re super excited to get to that next level, but not quite yet. Nail this stage and you’re going to be so much happier when you hit the next level.
Once you have a good understanding of your data, you can start to think about leveraging more complex algorithms, engaging in deep learning if your data set is big enough, or even adaptive learning. Always focus on the business objective at hand. AI is a tool and as Pei Wang has said, AI can be defined by structure, behavior, capability, function, and principle, and all of these different types of AI “will end up at different summits.” Understanding the summit your business is trying to reach, and optimizing your A/B testing, data, and algorithms around it, will help you achieve the business goals you’ve set and allow your AI to grow and thrive.
This is where traditional machine learning versus deep learning approaches become entirely dependent on your approach and business needs. As Sid Reddy mentions, “a key issue for machine learning algorithms is selection bias.” Meaning, someone with domain expertise is necessary for any ML process: Both the training data and algorithm selection ought to be selected by an individual with domain expertise. Domain expertise is still necessary for either a deep learning or machine learning pursuit.
AI actualization
AI actualization is a lot like human self actualization at the peak of Maslow’s hierarchy of needs. We like to think that we occupy that space in fleeting moments, but as a species we’re just not quite advanced enough yet to live there. The ultimate state of AI is, of course, a point where it could start at the base of Maslow’s hierarchy of needs and progress along with humans. This would mean that AI had achieved broad intelligence. For this to happen, think of every category of human intelligence: sound, sight, hearing, taste, touch, smell, proprioception, memory, recall, divergent thinking, and so on. Think of the parameters and data sets needed to make these up, inform them, and the biological as well as social mechanisms needed to be able to act them out in real time.
For AI to become more general its needs for real-time learning, the understanding of context with memory, the ability to plan and reason, metacognition, and so on, all must be met. As more valid environmental and psychological data sets become available, AI will have larger social sets to connect and learn from. Because AI broadly learns from we humans, and our understanding of our own mind, greater scientific understanding in the fields of neurological, behavioral, and social psychology are needed. And this brings us all the way back to the importance of AI’s lifeblood: healthy data.
In conclusion
You can understand where your company’s AI efforts currently are based on the conversations people are having. If they’re focused on safety needs, it means they probably have a pretty reliable data set. If they’re talking about social needs, it means that they’ve had multiple ethical conversations. If they’ve jumped straight to algorithms that they think they can just dump data into, make sure to ask what they’ve done so far.
The reality is that most of us aren’t having these conversations. We’re focused on plugging in whatever data we can find and expecting algorithms to just handle it. We’re jumping to conclusions. The mass reality is that most companies never moved past the whole “big data” hype era and are still figuring out how to properly understand what is good clean data and what is garbage. This is perhaps why KPMG found that CEOs don’t trust their data. Reports like this tell us that right now, beyond any other need, the majority of companies using AI are still at square one of AI’s needs: sound data. You can help the evolution of AI by turning to your organization and questioning the validity of your data and better understanding the business need behind the AI solution. In the coming years, as more and more companies began to care about the importance of data durability, integrity, and validity it will be time to create the next step for mankind in its pursuit of AI: the great discourse on AI safety.
Joe Schaeppi is the cofounder of 12traits and a 2018 House of Beautiful Business Resident.
A definitive guide to conditional logic in JavaScript
I am a front-end engineer and mathematician. I rely on my mathematical training daily in writing code. It’s not statistics or calculus that I use but, rather, my thorough understanding of Boolean logic. Often I have turned a complex combination of ampersands, pipes, exclamation marks, and equals signs into something simpler and much more readable. I’d like to share this knowledge, so I wrote this article. It’s long but I hope it is as beneficial to you as it has been to me. Enjoy!
Truthy & Falsy values in JavaScript
Before studying logical expressions, let’s understand what’s “truthy” in JavaScript. Since JavaScript is loosely typed, it coerces values into booleans in logical expressions. if statements, &&, ||, and ternary conditions all coerce values into booleans. Note that this doesn’t mean that they always return a boolean from the operation.
There are only six falsy values in JavaScript — false, null, undefined, NaN, 0, and "" — and everything else is truthy. This means that [] and {} are both truthy, which tend to trip people up.
The logical operators
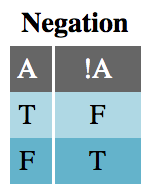
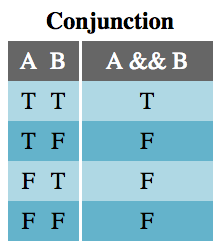
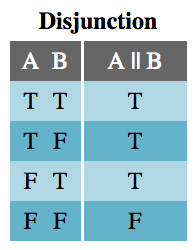
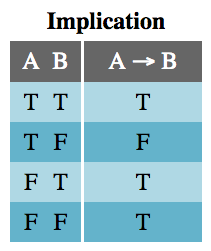
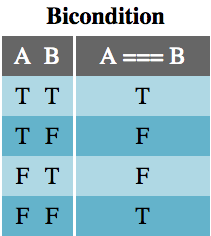
In formal logic, only a few operators exist: negation, conjunction, disjunction, implication, and bicondition. Each of these has a JavaScript equivalent: !, &&, ||, if (/* condition */) { /* then consequence */}, and ===, respectively. These operators create all other logical statements.
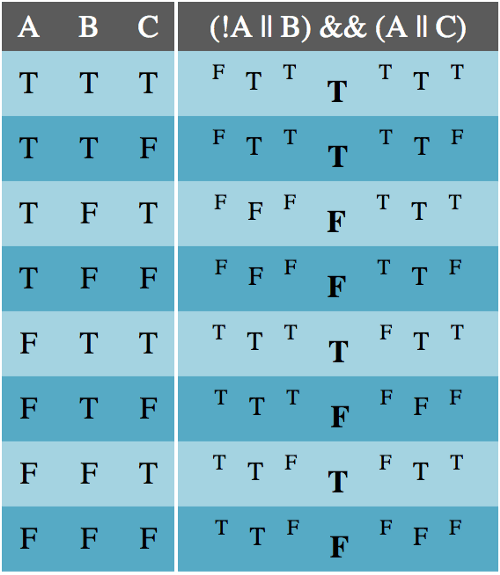
Truth Tables
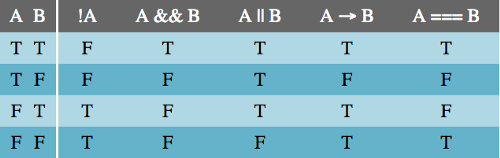
First, let’s look at the truth tables for each of our basic operators. A truth table tells us what the truthiness of an expression is based on the truthiness of its parts. Truth tables are important. If two expressions generate the same truth table, then those expressions are equivalent and can replace one another.
The Negation table is very straightforward. Negation is the only unary logical operator, acting only on a single input. This means that !A || B is not the same as !(A || B). Parentheses act like the grouping notation you’d find in mathematics.
For instance, the first row in the Negation truth table (below) should be read like this: “if statement A is True, then the expression !A is False.”
Negating a simple statement is not difficult. The negation of “it is raining” is “it is not raining,” and the negation of JavaScript’s primitive true is, of course, false. However, negating complex statements or expressions is not so simple. What is the negation of “it is always raining” or isFoo && isBar?
The Conjunction table shows that the expression A && B is true only if both A and B are true. This should be very familiar from writing JavaScript.
The Disjunction table should also be very familiar. A disjunction (logical OR statement) is true if either or both of A and B are true.
The Implication table is not as familiar. Since A implies B, A being true implies B is true. However, B can be true for reasons other than A, which is why the last two lines of the table are true. The only time implication is false is when A is true and B is false because then A doesn’t imply B.
While if statements are used for implications in JavaScript, not all ifstatements work this way. Usually, we use if as a flow control, not as a truthiness check where the consequence also matters in the check. Here is the archetypical implicationif statement:
function implication(A, B) {
if (A) {
return B;
} else {
/* if A is false, the implication is true */
return true;
}
}
Don’t worry that this is somewhat awkward. There are easier ways to code implications. Because of this awkwardness, though, I will continue to use →as the symbol for implications throughout this article.
The Bicondition operator, sometimes called if-and-only-if (IFF), evaluates to true only if the two operands, A and B, share the same truthiness value. Because of how JavaScript handles comparisons, the use of === for logical purposes should only be used on operands cast to booleans. That is, instead of A === B, we should use !!A === !!B.
The Complete Truth Table
Caveats
There are two big caveats to treating JavaScript code like propositional logic: short circuiting and order of operations.
Short circuiting is something that JavaScript engines do to save time. Something that will not change the output of the whole expression is not evaluated. The function doSomething() in the following examples is never called because, no matter what it returned, the outcome of the logical expression wouldn’t change:
// doSomething() is never called
false && doSomething();
true || doSomething();
Recall that conjunctions (&&) are true only ifboth statements are true, and disjunctions (||) are false only if both statements are false. In each of these cases, after reading the first value, no more calculations need to be done to evaluate the logical outcome of the expressions.
Because of this feature, JavaScript sometimes breaks logical commutativity. Logically A && B is equivalent to B && A, but you would break your program if you commuted window && window.mightNotExist into window.mightNotExist && window. That’s not to say that the truthiness of a commuted expression is any different, just that JavaScript may throw an error trying to parse it.
The order of operations in JavaScript caught me by surprise because I was not taught that formal logic had an order of operations, other than by grouping and left-to-right. It turns out that many programming languages consider &&to have a higher precedence than ||. This means that && is grouped (not evaluated) first, left-to-right, and then || is grouped left-to-right. This means that A || B && C is not evaluated the same way as (A || B) && C, but rather as A || (B && C).
true || false && false; // evaluates to true
(true || false) && false; // evaluates to false
Fortunately, grouping, (), holds the topmost precedence in JavaScript. We can avoid surprises and ambiguity by manually associating the statements we want evaluated together into discrete expressions. This is why many code linters prohibit having both && and || within the same group.
Calculating compound truth tables
Now that the truthiness of simple statements is known, the truthiness of more complex expressions can be calculated.
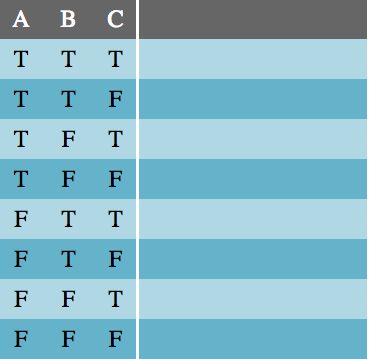
To begin, count the number of variables in the expression and write a truth table that has 2ⁿ rows.
Next, create a column for each of the variables and fill them with every possible combination of true/false values. I recommend filling the first half of the first column with T and the second half with F, then quartering the next column and so on until it looks like this:
Then write the expression down and solve it in layers, from the innermost groups outward for each combination of truth values:
As stated above, expressions which produce the same truth table can be substituted for each other.
Rules of replacements
Now I’ll cover several examples of rules of replacements that I often use. No truth tables are included below, but you can construct them yourself to prove that these rules are correct.
Double negation
Logically, A and !!A are equivalent. You can always remove a double negation or add a double negation to an expression without changing its truthiness. Adding a double-negation comes in handy when you want to negate part of a complex expression. The one caveat here is that in JavaScript !! also acts to coerce a value into a boolean, which may be an unwanted side-effect.
A === !!A
Commutation
Any disjunction (||), conjunction (&&), or bicondition (===) can swap the order of its parts. The following pairs are logically equivalent, but may change the program’s computation because of short-circuiting.
(A || B) === (B || A)
(A && B) === (B && A)
(A === B) === (B === A)
Association
Disjunctions and conjunctions are binary operations, meaning they only operate on two inputs. While they can be coded in longer chains — A || B || C || D — they are implicitly associated from left to right — ((A || B) || C) || D. The rule of association states that the order in which these groupings occur make no difference to the logical outcome.
((A || B) || C) === (A || (B || C))
((A && B) && C) === (A && (B && C))
Distribution
Association does not work across both conjunctions and disjunctions. That is, (A && (B || C)) !== ((A && B) || C). In order to disassociate B and C in the previous example, you must distribute the conjunction — (A && B) || (A && C). This process also works in reverse. If you find a compound expression with a repeated disjunction or conjunction, you can un-distribute it, akin to factoring out a common factor in an algebraic expression.
(A && (B || C)) === ((A && B) || (A && C))
(A || (B && C)) === ((A || B) && (A || C))
Another common occurrence of distribution is double-distribution (similar to FOIL in algebra):
1. ((A || B) && (C || D)) === ((A || B) && C) || ((A || B) && D)
2. ((A || B) && C) || ((A || B) && D) ===
((A && C) || B && C)) || ((A && D) || (B && D))
(A || B) && (C || D) === (A && C) || (B && C) || (A && D) || (B && D)
(A && B) ||(C && D) === (A || C) && (B || C) && (A || D) && (B || D)
Material Implication
Implication expressions (A → B) typically get translated into code as if (A) { B } but that is not very useful if a compound expression has several implications in it. You would end up with nested if statements — a code smell. Instead, I often use the material implication rule of replacement, which says that A → B means either A is false or B is true.
(A → B) === (!A || B)
Tautology & Contradiction
Sometimes during the course of manipulating compound logical expressions, you’ll end up with a simple conjunction or disjunction that only involves one variable and its negation or a boolean literal. In those cases, the expression is either always true (a tautology) or always false (a contradiction) and can be replaced with the boolean literal in code.
(A || !A) === true
(A || true) === true
(A && !A) === false
(A && false) === false
Related to these equivalencies are the disjunction and conjunction with the other boolean literal. These can be simplified to just the truthiness of the variable.
(A || false) === A
(A && true) === A
Transposition
When manipulating an implication (A → B), a common mistake people make is to assume that negating the first part, A, implies the second part, B, is also negated — !A → !B. This is called the converse of the implication and it is not necessarily true. That is, having the original implication does not tell us if the converse is true because A is not a necessary condition of B. (If the converse is also true — for independent reasons — then A and B are biconditional.)
What we can know from the original implication, though, is that the contrapositive is true. Since Bis a necessary condition for A (recall from the truth table for implication that if B is true, A must also be true), we can claim that !B → !A.
(A → B) === (!B → !A)
Material Equivalence
The name biconditional comes from the fact that it represents two conditional (implication) statements: A === B means that A → BandB → A. The truth values of A and B are locked into each other. This gives us the first material equivalence rule:
(A === B) === ((A → B) && (B → A))
Using material implication, double-distribution, contradiction, and commutation, we can manipulate this new expression into something easier to code:
1. ((A → B) && (B → A)) === ((!A || B) && (!B || A))
2. ((!A || B) && (!B || A)) ===
((!A && !B) || (B && !B)) || ((!A && A) || (B && A))
3. ((!A && !B) || (B && !B)) || ((!A && A) || (B && A)) ===
((!A && !B) || (B && A))
4. ((!A && !B) || (B && A)) === ((A && B) || (!A && !B))
(A === B) === ((A && B) || (!A && !B))
Exportation
Nested if statements, especially if there are no else parts, are a code smell. A simple nested if statement can be reduced into a single statement where the conditional is a conjunction of the two previous conditions:
if (A) {
if (B) {
C
}
}
// is equivalent to
if (A && B) {
C
}
(A → (B → C)) === ((A && B) → C)
DeMorgan’s Laws
DeMorgan’s Laws are essential to working with logical statements. They tell how to distribute a negation across a conjunction or disjunction. Consider the expression !(A || B). DeMorgan’s Laws say that when negating a disjunction or conjunction, negate each statement and change the && to ||or vice versa. Thus !(A || B) is the same as !A && !B. Similarly, !(A && B)is equivalent to !A || !B.
!(A || B) === !A && !B
!(A && B) === !A || !B
Ternary (If-Then-Else)
Ternary statements (A ? B : C) occur regularly in programming, but they’re not quite implications. The translation from a ternary to formal logic is actually a conjunction of two implications, A → B and !A → C, which we can write as: (!A || B) && (A || C), using material implication.
(A ? B : C) === (!A || B) && (A || C)
XOR (Exclusive Or)
Exclusive Or, often abbreviated xor, means, “one or the other, but not both.” This differs from the normal or operator only in that both values cannot be true. This is often what we mean when we use “or” in plain English. JavaScript doesn’t have a native xor operator, so how would we represent this?
1. “A or B, but not both A and B”
2. (A || B) && !(A && B)direct translation
3. (A || B) && (!A || !B)DeMorgan’s Laws
4. (!A || !B) && (A || B)commutativity
5. A ? !B : Bif-then-else definition
A ? !B : B is exclusive or (xor) in JavaScript
Alternatively,
1. “A or B, but not both A and B”
2. (A || B) && !(A && B)direct translation
3. (A || B) && (!A || !B)DeMorgan’s Laws
4. (A && !A) || (A && !B) || (B && !A) || (B && !B)double-distribution
5. (A && !B) || (B && !A)contradiction replacement 6. A === !B or A !== Bmaterial equivalence
A === !B or A !== B is xor in JavaScript
Set Logic
So far we have been looking at statements about expressions involving two (or a few) values, but now we will turn our attention to sets of values. Much like how logical operators in compound expressions preserve truthiness in predictable ways, predicate functions on sets preserve truthiness in predictable ways.
A predicate function is a function whose input is a value from a set and whose output is a boolean. For the following code examples, I will use an array of numbers for a set and two predicate functions:isOdd = n => n % 2 !== 0; and isEven = n => n % 2 === 0;.
Universal Statements
A universal statement is one that applies to all elements in a set, meaning its predicate function returns true for every element. If the predicate returns false for any one (or more) element, then the universal statement is false. Array.prototype.every takes a predicate function and returns true only if every element of the array returns true for the predicate. It also terminates early (with false) if the predicate returns false, not running the predicate over any more elements of the array, so in practice avoid side-effects in predicates.
As an example, consider the array [2, 4, 6, 8], and the universal statement, “every element of the array is even.” Using isEven and JavaScript’s built-in universal function, we can run [2, 4, 6, 8].every(isEven) and find that this is true.
Array.prototype.every is JavaScript’s Universal Statement
Existential Statements
An existential statement makes a specific claim about a set: at least one element in the set returns true for the predicate function. If the predicate returns false for every element in the set, then the existential statement is false.
JavaScript also supplies a built-in existential statement: Array.prototype.some. Similar to every, some will return early (with true) if an element satisfies its predicate. As an example, [1, 3, 5].some(isOdd) will only run one iteration of the predicate isOdd (consuming 1 and returning true) and return true. [1, 3, 5].some(isEven) will return false.
Array.prototype.some is JavaScript’s Existential Statement
Universal Implication
Once you have checked a universal statement against a set, say nums.every(isOdd), it is tempting to think that you can grab an element from the set that satisfies the predicate. However, there is one catch: in Boolean logic, a true universal statement does not imply that the set is non-empty. Universal statements about empty sets are always true, so if you wish to grab an element from a set satisfying some condition, use an existential check instead. To prove this, run [].every(() => false). It will be true.
Universal statements about empty sets are always true.
Negating Universal and Existential Statements
Negating these statements can be surprising. The negation of a universal statement, say nums.every(isOdd), is not nums.every(isEven), but rather nums.some(isEven). This is an existential statement with the predicate negated. Similarly, the negation of an existential statement is a universal statement with the predicate negated.
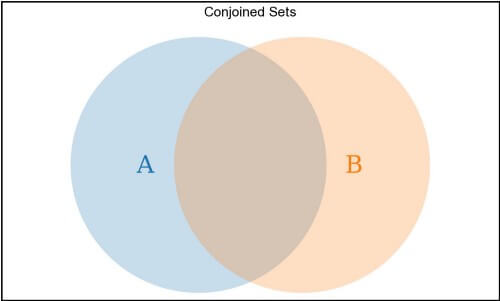
Two sets can only be related to each other in a few ways, with regards to their elements. These relationships are easily diagrammed with Venn Diagrams, and can (mostly) be determined in code using combinations of universal and existential statements.
Two sets can each share some but not all of their elements, like a typical conjoined Venn Diagram:
A.some(el => B.includes(el)) && A.some(el => !B.includes(el)) && B.some(el => !A.includes(el)) describes a conjoined pair of sets
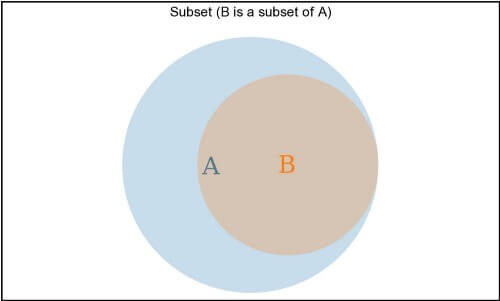
One set can contain all of the other set’s elements, but have elements not shared by the second set. This is a subset relationship, denoted as Subset ⊆ Superset.
B.every(el => A.includes(el)) describes the subset relationship B ⊆ A
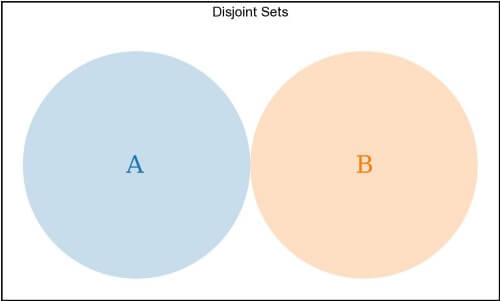
The two sets can share no elements. These are disjoint sets.
A.every(el => !B.includes(el)) describes a disjoint pair of sets
Lastly, the two sets can share every element. That is, they are subsets of each other. These sets are equal. In formal logic, we would write A ⊆ B && B ⊆ A ⟷ A === B, but in JavaScript, there are some complications with this. In JavaScript, an Array is an ordered set and may contain duplicate values, so we cannot assume that the bidirectional subset code B.every(el => A.includes(el)) && A.every(el => B.includes(el)) implies the arrays A and B are equal. If A and B are Sets (meaning they were created with new Set()), then their values are unique and we can do the bidirectional subset check to see if A === B.
(A
=== B) === (Array.from(A).every(el => Array.from(B).includes(el))
&& Array.from(B).every(el => Array.from(A).includes(el)), given that A and Bare constructed using new Set()
Translating Logic to English
This section is probably the most useful in the article. Here, now that you know the logical operators, their truth tables, and rules of replacement, you can learn how to translate an English phrase into code and simplify it. In learning this translation skill, you will also be able to read code better, storing complex logic in simple phrases in your mind.
Below is a table of logical code (left) and their English equivalents (right) that was heavily borrowed from the excellent book, Essentials of Logic.
View a screen-readable version of this code-to-English translation chart here.
Below, I will go through some real-world examples from my own work where I interpret from English to code, and vice-versa, and simplify code with the rules of replacement.
Example 1
Recently, to satisfy the EU’s GDPR requirements, I had to create a modal that showed my company’s cookie policy and allowed the user to set their preferences. To make this as unobtrusive as possible, we had the following requirements (in order of precedence):
If the user wasn’t in the EU, never show the GDPR preferences modal.
2. If the app programmatically needs to show the modal (if a user action requires more permission than currently allowed), show the modal.
If the user is allowed to have the less-obtrusive GDPR banner, do not show the modal.
If the user has not already set their preferences (ironically saved in a cookie), show the modal.
I started off with a series of if statements modeled directly after these requirements:
const isGdprPreferencesModalOpen = ({
shouldModalBeOpen,
hasCookie,
hasGdprBanner,
needsPermissions
}) => {
if (!needsPermissions) {
return false;
}
if (shouldModalBeOpen) {
return true;
}
if (hasGdprBanner) {
return false;
}
if (!hasCookie) {
return true;
}
return false;
}
/* change to a single return, if-else-if structure */
let result;
if (!needsPermissions) {
result = false;
} else if (shouldBeOpen) {
result = true;
} else if (hasBanner) {
result = false;
} else if (!hasCookie) {
result = true
} else {
result = false;
}
return result;
/* use the definition of ternary to convert to a single return */
return !needsPermissions ? false : (shouldBeOpen ? true : (hasBanner ? false : (!hasCookie ? true : false)))
/* convert from ternaries to conjunctions of disjunctions */
return (!!needsPermissions || false) && (!needsPermissions || ((!shouldBeOpen || true) && (shouldBeOpen || ((!hasBanner || false) && (hasBanner || !hasCookie))))
I found the following code (written by a coworker) while updating a component. Again, I felt the urge to eliminate the boolean literal returns, so I refactored it.
Sometimes I do the following steps in my head or on scratch paper, but most often, I write each next step in the code and then delete the previous step.
// convert to if-else-if structure
let result;
if (isRequestInFlight) {
result = true;
} else if (enabledStates.includes(state)) {
result = false;
} else {
result = true;
}
return result;
In this example, I didn’t start with English phrases and I never bothered to interpret the code to English while doing the manipulations, but now, at the end, I can easily translate this: “the button is disabled if either the request is in flight or the state is not in the set of enabled states.” That makes sense. If you ever translate your work back to English and it doesn’t make sense, re-check your work. This happens to me often.
Example 3
While writing an A/B testing framework for my company, we had two master lists of Enabled and Disabled experiments and we wanted to check that every experiment (each a separate file in a folder) was recorded in one or the other list but not both. This means the enabled and disabled sets are disjointed and the set of all experiments is a subset of the conjunction of the two sets of experiments. The reason the set of all experiments must be a subset of the combination of the two lists is that there should not be a single experiment that exists outside the two lists.
Hopefully this has all been helpful. Not only are the skills of translating between English and code useful, but having the terminology to discuss different relationships (like conjunctions and implications) and the tools to evaluate them (truth tables) is handy.
One of the games that I occasionally play to relax is Minesweeper.
I have extensive experience with JavaScript front-end technologies starting from jQuery and nowadays Angular. Being open to new technologies I have tried React in few hello world projects. Implementing Minesweeper in TypeScript and React seemed like an interesting challenge and opportunity to learn more.
In this post I will try to explain how I did it and maybe encourage or learn you how to implement your clone of this or maybe some other game.
If you’re just interested in seeing the final solution visit or clone the GitHub repository or if you just want to play it click here.
Before we start
You will need to have installed (or install) on your machine:
We will bootstrap the React project with using the option --script-version=react-script-ts that would instruct create-react-app to use Create React App (with TypeScript) configuration.
In my previous experience with Angular I find TypeScript a real joy to work. And having daily experience with statically typed languages (Java, Kotlin) I was not interested in using pure ES6. On the other side, learning and investing time in Flow was not worth it having a previous (great) experience with TypeScript. Read this great article to find out more about using TypeScript + React.
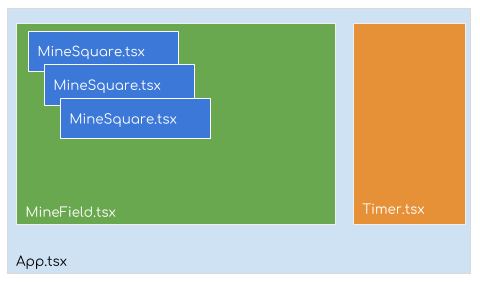
One of the important steps in implementing any React application is how to brake down the UI in components and how to compose them. On the following image is the structure of the React components that we will need to implement for Minesweeper.
React components structure
The final design was to brake down the game in three separate components:
MineSquare – will host a single square that is a possible mine, number indicating of neighbour bombs or just empty square if no bombs around
MineField – will host the game container as a grid (rows x columns) of mines
Timer – will be an external component that will show the elapsed time since the game started.
Next create a directory components in your src directory and create a separate file for each of the listed components.
This is how an empty component should look like:
import * as React from "react";
export const MineField = (props: PropType) => (
<div className="game-board">
{'MineField'}
</div>
);
In React you can create components as class that extends the React.Componentclass or as functions (possibly arrow) for functional (stateless) components.
Minesweeper game domain
The game domain are the classes and data structures used to represent the state of the game.
export interface Point {
x: number;
y: number;
}
/**
* bombs = -1 - it is a bomb
* bombs >= 0 - count of bombs around
*/
export class Mine {
constructor(public position: Point,
public isOpened = false,
public bombs = 0,
public isFlagged = false,
) {
}
}
export class Game {
constructor(public state: Array<Array<Mine>>,
public totalBombs = 0,
public exploded = false
) {
}
}
The game Minesweeper is represented as two-dimensional array (matrix) of mines Array<Array<Mine>> or Mine[][]. Each Mine has:
position (x,y coordinates) in the matrix of mines
isOpened a boolean field which is true when a mine field is opened
bombs a number which encodes if there is a bomb (-1) or positive number representing the count of bombs around that mine.
isFlagged which represents if the mine is marked (flagged) by the user as potential bomb.
It was really hard to get the naming right for the game domain, having to deal with mines/bombs, mine field as single field with mine or field of mines :).
The Game class represents the state of the Minesweeper game which is the two dimensional array of mines. Also it contains auxiliary fields for the count of total bombs and state if there is exploded bomb (game is finished).
MineSquare component
The MineSquare is a functional (stateless) component. That means that it should render the property field: Mine and just propagate an event when interaction happens. It can not keep or mutate any state.
The Mine will be rendered as HTML button element since the click is the natural interaction for this HTML element. Depending on the state of the field: Mine we will render the different content inside the button element. The function renderField(field: Mine) does exactly that. So when the field is opened (user explored that field) it can be:
bombs == -1 so we render a bomb (using FontAwesome bomb icon for this)
bombs == 0 the field is just empty
bombs > 0 we render the number of bombs in that field.
When the field is opened and flagged we render a flag icon.
The component propagates the mouse onClick event to indicate user interaction with this field.
In minesweeper there are two types of interaction user can have with a field, to explore it or to flag it as potential mine. Maybe better choice is to represent these with different events such as mouse left and right click. But because of a buggy behaviour of the right click, my final choice was to encode these two different events with only left click and a pressed state of a certain keyboard key (ctrl in my case).
MineField component
The MineField component is also functional and is responsible of rendering the full state of the game (the two-dimensional array of mines). Each field is rendered as a separate MineSquare component. It will also propagate the click event from each MineSquare component.
This component is very simple, it should just render the two-dimensional array of mines as grid. Each row is grouped in a separate HTML container divelement and with CSS it is all aligned. To uniquely identify each row we can use the row index i as a React key property, and for each MineSquare component the key would be the combination of indices i and j (the current row and column).
Timer component
The Timer is another stateless component responsible for rendering the elapsed seconds since the game started. To render the seconds in appropriate format 00:00 it uses a custom function secondsToString from our utility module named time.
Here is the implementation of the secondsToString function.
function leadZero(num: number) {
return num < 10 ? `0${num}` : `${num}`;
}
export const time = {
secondsToString: function (seconds: number) {
const min = Math.floor(seconds / 60);
const sec = seconds % 60;
return `${leadZero(min)}:${leadZero(sec)}`;
}
};
One of the known drawbacks of TypeScript and JavaScript language in general is the lack of powerful standard library. But instead of relying on myriad of external modules for simple functions such as leadZero or secondsToString I think it’s better to just implement them.
Game state
So far we have implemented the simple (stateless) components of the game. To make the game alive we need to implement initialization of new game state (new game action) and all possible modifications.
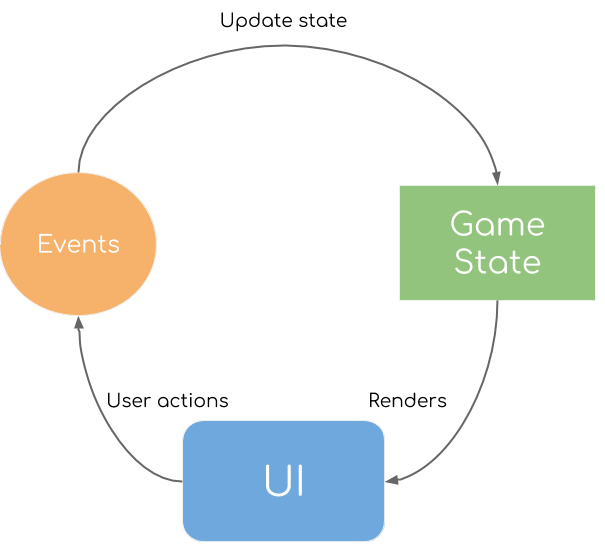
Simplified game loop
Most of the simple games are following some kind of game loop as shown in the image above. The users through the UI are having interactions with the game and are generating actions. Sometimes actions are generated automatically as the time passing, but in Minesweeper that is not the case. On each action, the state of the game is modified and then rendered back on the UI.
In the case of Minesweeper, the user can make three possible actions on not opened field (mine square):
mark it as potential bomb
open it
and if the field is already opened the user can explore neighbours.
Generating new game state
Generating new game state means initializing the two-dimensional array of Mine objects. Some of these mines need to be bombs and we make this decision by using pseudo-random number generator to implement sort of uniform distribution of a mine being a bomb. The BOMBS_PROBABILITY (by default 0.15 or 15%) is the probability of a mine having a bomb. While we create mines we generate a pseudo-random number using Math.random() which has generates a double with uniform distribution in the range of 0-0.99.
After we have initialized the game state with Array<Array<Mine>> we need to update the bombs count of all mines that are neighbouring a bomb. The function fillBombsCount does just that, by traversing all the neighbours of a mine and incrementing the bombs count for each neighbour that is a bomb.
The traverseNeighbours is the utility function that iterates all eight (top left, top, top right, left, right, bottom left, bottom, bottom right) of the neighbours of a given mine.
The function update is a generic function for updating the game state without modifying it. It iterates all of the game state mines and applies a function f that should apply the actual transformation for a mine. This function is used in all functions that need to update the game state in any way.
The function markMine is used for two user actions. The first action is when user wants to mark a mine field as a potential bomb. We do that, only when the current state of the field is not opened by updating the game state where we set that field as flagged and not opened. The second possible action for a user is to explore already opened field that has a count of bombs.
function markMine(game: Game, opened: Mine): Game {
if (opened.isOpened && !opened.isFlagged) return exploreOpenedField(game, opened);
return update(game, (field: Mine) => {
if (field == opened) {
return new Mine(field.position, false, field.bombs, !field.isFlagged);
} else {
return new Mine(field.position, field.isOpened, field.bombs, field.isFlagged);
}
});
}
Exploring opened field
To explore open field is a potentially game ending action that needs to explore all neighbour fields of that field. The opened field that a user explores must have all its neighbour bombs flagged right. If a neighbour field that is a bomb is not flagged, the game ends.
function exploreOpenedField(game: Game, opened: Mine): Game {
const updated = update(game, (field: Mine) => field);
let hitMine = false;
traverseNeighbours(updated.state, opened, field => {
if (!field.isOpened && !field.isFlagged) {
if (isMine(field)) {
hitMine = true;
} else {
field.isOpened = true;
if (field.bombs == 0) {
updateZeros(updated.state, field);
}
}
}
return field;
});
if (hitMine) {
return endGame(game);
}
return updated;
}
To implement this function we use the generic traverseNeighbours and for each neighbour field that is not opened and not flagged:
if it’s a mine we should end the game
if it’s not we should set as opened and if we open a zero-bomb field we should open all other connected zero-bomb fields.
Open mine
function endGame(game: Game): Game {
return update(game, (field) => {
if (isMine(field)) {
return new Mine(field.position, true, field.bombs, field.isFlagged);
} else {
return new Mine(field.position, field.isOpened, field.bombs, field.isFlagged);
}
}, true);
}
function openMine(game: Game, field: Mine): Game {
if (field.isFlagged) return game;
else if (isMine(field)) {
return endGame(game);
} else {
const openField = (openedField: Mine) => (field: Mine) => {
if (field === openedField) {
return new Mine(field.position, true, field.bombs, false);
} else {
return new Mine(field.position, field.isOpened, field.bombs, field.isFlagged);
}
};
let result = update(game, openField(field));
if (field.bombs == 0) {
updateZeros(result.state, field);
}
return result;
}
}
Traversing connected zero-bomb fields
The function updateZeros traverses using a recursive DFS (Depth-First Search) algorithm all connected zero-bomb fields.
On each state modifying action we need to check if the state of game has reached an end state. For the game Minesweeper that state is when all the fields are explored correctly. That means that a mine field that contains a bomb is flagged and otherwise it’s opened.
function checkCompleted(game: Game): boolean {
const and = (a: boolean, b: boolean) => a && b;
return game.state.map(row => {
return row.map(field => {
return isMineCovered(field);
}).reduce(and);
}).reduce(and);
}
function isMineCovered(field: Mine) {
if (isMine(field)) {
return field.isFlagged;
} else {
return field.isOpened;
}
}
The function checkCompleted checks for the end state by iterating all fields and mapping them in to a boolean value. The true value means field is explored correctly and false means not explored correctly. Combining all these values using logical AND would yield final true only if all fields are explored correctly, which would mean the end state is reached.
Count flagged fields
The function countFlagged is used to count all the flagged fields in the game state to show the current progress of flagged/total bombs.
function countFlagged(game: Game): number {
const plus = (a: number, b: number) => a + b;
return game.state.map(row => {
return row.map(field => {
return field.isFlagged ? 1 : 0;
}).reduce(plus, 0);
}).reduce(plus, 0);
}
Putting all together in App component
Once we have implemented all the game state modifications and checks we can put it all together. The actual game state is initialized and modified in the component App.
The final piece of the puzzle, the App component is the only stateful component that keeps and modifies the game state. The state of the component contains:
the number of rows and columns of the Minesweeper grid
the game state
the elapsed seconds since the game started
the number of flagged fields (computed from the game state)
and a boolean flag indicated if the game is completed (also computed from the game state).
The state is initialized at the beginning of the component on a new game state. We use the React lifecycle method componentDidMount to bind two keyboard events onkeydown and onkeyup to track the state of ctrl key. We also start a timer using JavaScript setTimeout function that we use to modify the elapsed seconds state.
The function updateState is used to update the state of the React component using this.setState. This is a HOF (higher-order function) that accepts the actual game state modification function as updateFn as argument. Once the game state is modified, the final state of the component is updated and the UI should be rendered. This function is called on the user generated event onSquareLeftClick. When the ctrl button is down a mine is opened and otherwise mine is marked (or explored).
The actual rendering of the UI is pretty simple. We render a simple menu of three links that allow to start new game with the chosen difficulty. Then we render the MineField component with the current game state and the Timercomponent showing the elapsed seconds. Finally, we render a information on the current status of the game, such as is it completed and number of flagged fields vs total bombs.
Conclusion
Implementing any simple game is an interesting programming challenge. Many times a challenging part is to implement the game state and functions (algorithms) that mutate the state. Favouring functional programming I tried to implement most of these functions as mostly pure functions by using functional constructs such as map and reduce. Also, three out of four React components are functional (stateless or pure functions).
Hopefully sharing my solution and explaining it in this post was interesting and learning experience. If you feel inspired to start learning these technologies by implementing your own Minesweeper or other game, that would be great. And finally, it would be perfect if you also share your code and experience.