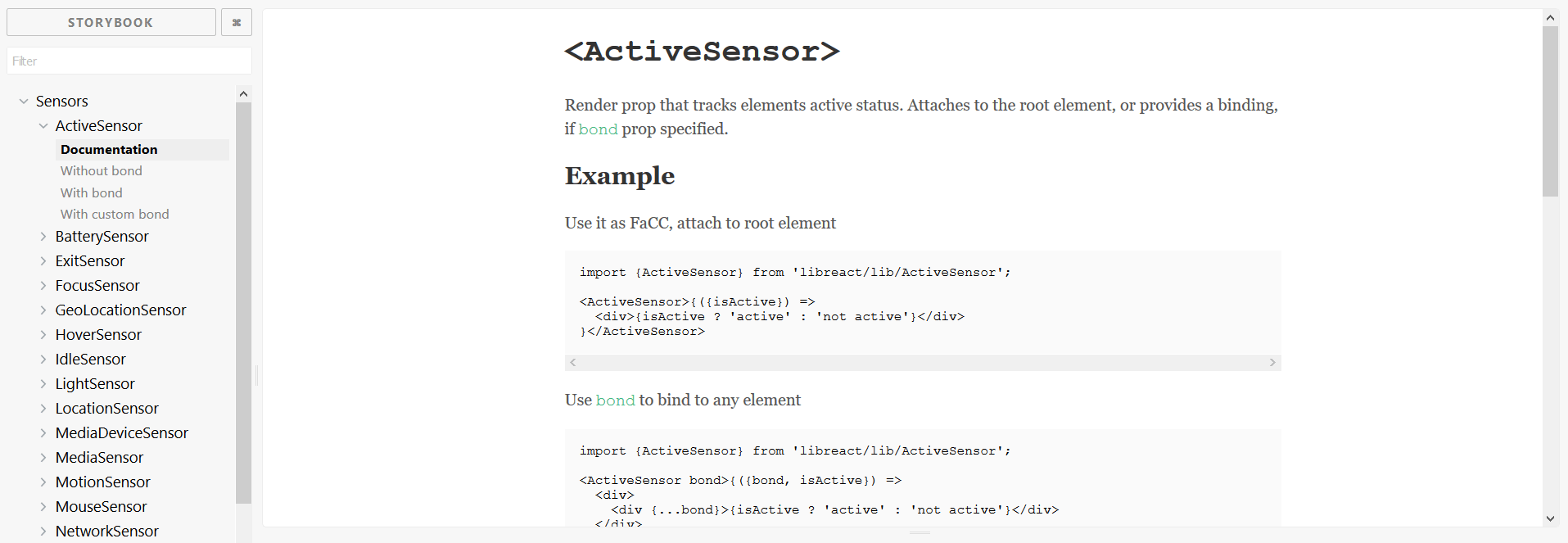
Once you’re done developing your applications, it’s time to deploy it. There are multiple cloud providers that offer all the necessary services to build and deploy your applications, the largest of them being Amazon Web Services, Microsoft Azure and Google Cloud Platform. There are also smaller players that provide more tailored services that can be easier to set up for beginners.
Why clouds?We believe, that deploying an application into a cloud-based service nowadays is the best way to go. Pricewise you might find better offers from local data centers available in your region, but joining a larger cloud provider will grant you access to a lot of modern services and different geographical regions. Unless you have compelling legal or financial reasons to host in a local datacenter, clouds seem like a better alternative.
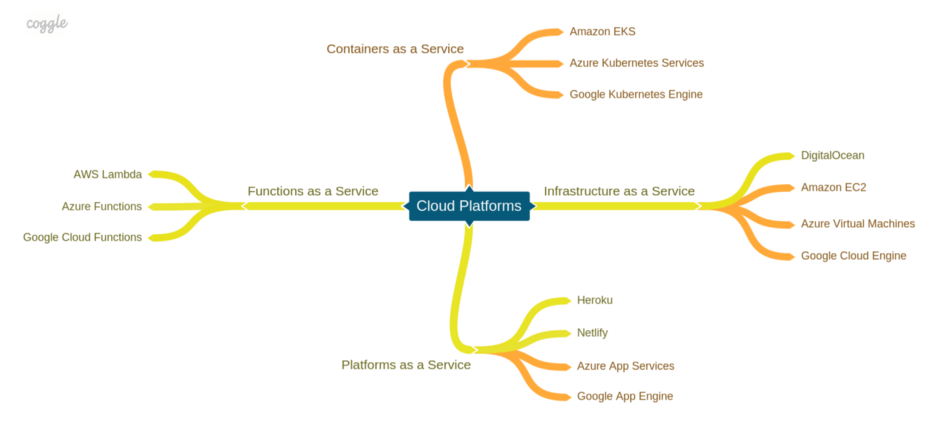
When we’re talking about application hosting, there are several layers of abstraction you can choose, from infrastructure as a service, meaning virtual machines, disks, and networks, to containers as a service, a high-level abstraction for running containers over a cluster of machines. Lower abstraction levels give you more control over the setup, but also require more work and technical skills to configure, while higher-level services make things easier, often reducing the level of control and transparency.
? Infrastructure as a Service
Infrastructure as a Service (IaaS) refers to services that allow you to run virtual machines, file systems, and virtual networks. To make onboarding easier, some platforms provide you with pre-configured images of machines built for different purposes, such as an Apache server on Ubuntu or a PostgreSQL server. You can create a VM based on one of those images and then tailor it to your needs, for example, install software, configure networking and setup security and firewalls. Although IaaS gives you the most control over your services, it’s also requires the most efforts to set up. It’s a good choice when you need to host something other than a plain web application.
Here are some of the popular IaaS services from different providers.
? DigitalOcean is a cloud platform that offers IaaS services in data centers worldwide. Setting up a VM in DigitalOcean is relatively simple, however, it only offers Linux virtual machines. DigitalOcean offers $100 worth of credits for 60 days to try their services.
? Amazon EC2 is the Amazon’s IaaS offering and a leader in the overall market share. EC2 offers different kinds of virtual machines with flexible configuration, however, the initial setup can be more challenging. It offers a free 12 month tier for some of the smaller VM types.
? Azure Virtual Machines is an IaaS offering from Microsoft with a large number of pre-configured images. Microsoft offers $200 worth of credits for one month and 750 hours of small VM’s for 12 months.
? Google Compute Engine is a service in the Google Cloud Platform that offers $300 credits for a 12 month trial period, an always-free micro VM instance.
? Platform as a Service
Platform as a Service (PaaS) is a type of service for running web applications designed for easier setup. Unlike IaaS, PaaS services provide a complete technology stack to run your application without the need to set up the environment on your own. Some of the other concerns that are usually handled by PaaSes are:
A user interface for managing, running or stopping your application;
Basic monitoring and logging capabilities;
Horizontal and vertical scaling to cope with increasing loads;
Environment configuration;
Health checks to make sure your application is running and accessible.
Some PaaSes have a limited set of languages they natively support, but nowadays most of them support running Docker containers, meaning you can run an application written in almost any technology. PaaSes are usually designed for running web applications, and might not be suitable to run daemons or other kinds of software.
Some of the popular PaaS offerings are:
? Heroku is one of the oldest PaaS services out there. It supports running applications written in Ruby, Java, PHP, Node.js, and others, as well as deploying applications in Docker containers. Heroku offers a free tier, however, your application will be put to sleep after 30 minutes of inactivity.
? Netlify is a service for hosting static websites. It offers a fully fledged free tier with support for automated deployment, HTTPS, redirects, A/B testing, form submission and backend logic using AWS Lambda functions.
? Azure App Service is an offering from Microsoft Azure. It allows hosting applications written in different languages on both Windows or Linux, as well as running Docker applications. There’s a free shared instance available for the Windows app service.
? Google App Engine is a service on Google Cloud that supports deploying applications written in Java, Python, Node.js, Go and PHP and Docker applications. There’s also a limited free tier available.
? Function as a Service
Function as a service (FaaS), sometimes also referred to as serverlesscomputing, is a relatively new concept in cloud computing. It’s designed to deploy simple atomic functions into a runtime without the need to worry about the infrastructure and a lot of operational concerns, such as logging and monitoring. Such functions can be invoked as regular services via HTTP requests, but a lot of platforms also provide the ability to react to various events such file uploads, a message in a queue or a modification in a database. The pricing model of FaaSes is also different. Instead of uptime, you pay for execution counts and consumed resources. This makes it a financially attractive solution for parts of your application that don’t need to be up all the time or need to scale dynamically.
Functions have their downsides though. The tooling for most platforms is still in its infancy and local development may be not as smooth as with regular applications. The situation, however, can improve as the serverless movement is gaining momentum.
Popular cases for using functions include simple backend services that can be implemented with a minimal amount of code or post-processing to different events in your applications.
Most large cloud providers also has a function offering:
? AWS Lambdaoffers integrations with other Amazon services such as S3, DynamoDB, Kinesis, SNS, and CloudWatch as well as the ability to orchestrate function-based workflows using Step Functions. The AWS SAM tools allows testing your functions locally before deployment. The free tier offers 1M requests and 400,000 Gb seconds computing power per month.
? Azure Functions is a similar offering from Microsoft that allows integrating with Azure services, such as Blob Storages, Storage Queues, CosmosDB and etc. Azure Functions can be integrated into Logic Apps to form complex workflows. It currently supports C#, F#, JavaScript, and Python as well as Java but in preview. It also offers 1M requests and 400,000 Gb seconds computing power per month.
? Google Cloud Functions provides similar integrations to Google Cloud services, however, only JavaScript and Python functions are supported at the moment. Local development is supported only for JavaScript functions.
? Containers as a Service
With the rise of containers and Kubernetes as the dominant orchestration platform new “Kubernetes as a service” solutions are rolled out by all the major cloud platforms. Such services are commonly referred to as Containers as a Service (CaaS). Since hosting your own Kubernetes cluster is not a trivial task, deploying to a managed cloud cluster is a better alternative for most cases. Such services offer maintained control planes, upgrades, guaranteed cluster uptime and middleware so you can focus on developing your application.
? Amazon EKS provides a managed Kubernetes cluster with control nodes deployed to multiple availability zones to ensure uptime, built-in security features, and the ability to integrate with other AWS services. However, the process of setting up a new cluster is not as straightforward as it could be. There is no free tier available, and you need to pay both for the worker nodes, and a fixed fee per cluster.
? Azure Kubernetes Services (AKS) offers a relatively easy initial setup process and a competitive pricing model, that doesn’t charge anything for managing the cluster, but only for node VMs.
? Google Kubernetes Engine has received a lot of positive reviews from the community, which is to be expected from the company that created Kubernetes. It’s praised for its simple setup and operations. It does, however, offer less integrated services than other platforms.
The cloud landscape is actively developing and providers are racing to offer new innovative services and competitive pricing. Keep an eye out for new offerings from major cloud platforms but also follow smaller platforms that offer more tailored solutions.
This completes the four-chapter “Beginner’s Web Development Guide” for now. Hope it helped you find your way around the industry and gave you an idea on which direction to follow next. As a next step, I plan to compose it into a single presentable guide and publish it on devtrails.io so keep posted!
If you have any questions or comments, feel free to leave them here or reach out on twitter @devtrails.io.
推荐理由:不需要看到任何一个<div>,通过鼠标就能够构建一个 HTML 模版。它的示例网站上提供了各种你用的上的组件,如果你们需要一个方便管用的页面模版来发文章或者其他什么,而没有时间写个新的布局的话,这个项目就是你最好的选择,它们甚至还支持三种显示模式:PC 和两种不同尺寸的手机,应对各种情况都没问题。
今日推荐英文原文:《How to Build Amazing Development Teams》作者:Dan Jackson
What constitutes an amazing development team? There are tons of different ideas out there. What works for one team doesn’t necessarily work for another and building teams can be made easier or harder, depending on management’s vision. So, this article explores the baseline needs that will prepare any team to be amazing.
I’m defining an amazing development team as follows:
A team of developers who are competent enough to solve the problems and challenges that your business faces (technically) — whether as individuals or as a team — by whatever means necessary and within the development guidelines of your organization. An amazing development team does not require constant supervision and can operate fairly autonomously, can work methodically and within whatever manner the business requires (waterfall, scrum, kanban, etc.) while following processes and knowing when to ask for help. The team should work as a team and will adopt methods that are necessary to complete the task at hand, within a reasonable time frame.
This is the essence of what managers, VPs, and CTOs strive to achieve.
Most of these kinds of executives tend to say they are looking for “the best developers in the industry.” Is this the right way to build teams? For some, sure. But for everyone else… no.
Why should a manager not strive for the best developers? If a team can attract the best and secure them, then great. But there is a very big problem with this: There are thousands of development teams around the world and not all of them can have the “best developers in the industry.” Developers are a finite resource, and the best are a rarer breed, still.
Instead, managers can make the best team possible with the developers that are already there or can be hired. If a manager’s interview skills are up to scratch, then the team will already have good developers. And unless a team’s working on low-level, sub-millisecond, transactional software, the best developers may not even be necessary.
Hire the developers that you can get that are good enough for your business, have a willingness to learn, a desire to improve, and are ambitious.
Ultimately, building an amazing team is a two-way street: the manager must give the team every opportunity to learn and progress their skills; the team should try their best to resolve problems, raise issues, get training, and be a team player.
Putting the developers of natural genius aside, all of the other best developers are so because they have been afforded opportunity, nurturing, and leadership from the beginning of their careers, allowing them to flourish where others haven’t. It is more complex than this, but this is the essence.
Bottom line: Hire the developers that you can get that are good enough for your business, have a willingness to learn, a desire to improve, and are ambitious. That will create an amazing team.
Let’s break this down further.
Training
It is the responsibility of every development manager to offer training, where possible. This can be paying for courses or online training, or allowing your team members to spend some time learning by themselves using online tutorials, YouTube, or downloading sample code.
If training is required, it is the duty of the company to ensure their developers are able to keep pace with current advances in technology. Smaller companies will have restrictions on how much they can afford, but should offer opportunities to learn. Even if means a task takes longer because the developer is learning as they go, give time for the developer to do their job properly, rather than just getting a task working, and they will learn more along the way.
Affording the time to figure out new and better ways of solving problems can bring huge benefits; the product could be better, more effective, or resilient. And the developer will have learned how to apply those new skills to other areas of the product.
Motivation
Do developers enjoy their job? Do they enjoy working with the team? Do they actively participate in meetings, in the general office environment, in social situations? These are questions managers should be asking.
Because when a developer does not participate, this can be a warning sign. Maybe they are not motivated, they could be unhappy, or it could simply be that they do not understand an issue and are staying quiet rather than speaking up. Either way, this has to be tackled and managers need to find out the source of the problem.
Some of this could be about a dearth of training. A lack of understanding could mean your developers lose confidence, become withdrawn, and eventually, lose motivation.
Managers will, of course, lose developers. This is inevitable. Even the biggest and best companies cannot and do not retain every single developer. However, when a developer does leave, it is important to understand the reason why. If it is due to a lack of something — especially motivation — then managers do not want to let all of the talent feel this way and leave. Ultimately, it’s the manager’s responsibility to stay on top of workers’ motivation.
Motivating a team can be quite simple. One core element is creating an enjoyable office environment. For example, managers can extend invites for Friday night beverages. Or offer a team lunch down at a local bistro. Keep in mind: not all employees are keen on evening social events as they may have family commitments, long commutes, or just don’t want to stay out. This shouldn’t be frowned upon, but switched to lunchtime team get-togethers instead. There are developers who do not participate much in social events but they love being part of the team because they get on well with everyone and enjoy working alongside them.
Mutual respect is one of the greatest bonds of a team. Respect for each team member, regardless of differing outlooks, political views or ways of life will go a long way to making a happy and motivated developer.
One key motivation-killer is how a managers deal with failure. All teams will experience failure from time to time, some more than others. How a manager approaches this fact will have an impact on motivation. This is possibly one of the biggest factors that can break a teams’ motivation.
Responsibilities
Developers are great when they are given responsibilities. Yes, some can fall short but some can also excel. When a developer has ownership and responsibility for a particular area of a product, maybe a specific feature, they will make it their mission to ensure it is running smoothly, works as well as it can, and will actively look for improvements.
For example, a developer doesn’t simply need to write code. If a developer has interests in development and operations (DevOps) or Amazon Web Services (AWS) — for example — then have them work with the DevOps team, get involved with the architecture of AWS; be responsible to liaising between the dev team and the DevOps team for future changes. Let developers have some ownership in what they are developing and this can keep your team engaged and it also helps for team building and motivation.
If you can attract “the best” and secure them, then great, but there is a very big problem with this: There are thousands of development teams around the world and not all of them can have the “best developers in the industry.”
People
When building a new development team, there’s the luxury of hiring new developers. Do this well and the team is halfway to greatness. If, however, the team already exists then there may be a little more work to do; with an existing team, things have usually settled in and it can be difficult to get people to change their ways. But they can and they just need a little bit of convincing.
Implementing Change
What to do with a team that doesn’t want to change?
Give them a reason to.
Book a meeting room, throw some snacks on the table, and make it a relaxed atmosphere. Remember, this is about making changes to how the team operates, not having a deep discussion on system architecture. Explain, even demonstrate, the changes to be implemented and allow the team to ask questions, even challenge these new ideas.
Developers are intelligent people, so allow them to be part of the discussion rather than just imposing change upon them.
Team Management
Regardless of the size of any team, members should understand and respect the hierarchy; for example, junior > mid > senior > lead > manager. That doesn’t mean that a lead can or should look down on those at a lower rank, nor does it mean that the junior developer should feel any less in the team than a senior or lead. Everyone should be equal. However, it is important to maintain the escalation paths.
Additionally, management of a team should not be overbearing. Don’t constantly ask for updates, nor actively monitor each developer to ensure that they are working hard. Allow your team to know when they have done a good job, not just when they have gone wrong. Too many managers scold when things don’t go right but rarely offer praise when things go really well.
On the praise front: be genuine and be specific.
The Amazing Team
Remember that a team is a team, not just a bunch of bodies there to complete tasks. A team can also extend beyond the developers to include technical project managers, business analysts, scrum masters, and anyone else who is involved on a regular basis in the project, from the technical side. Without these critical roles, a team may lack direction and focus and no matter how well the team gels together a team cannot be amazing if they’re not delivering what the business needs.
Applying these general principles to your teams can mean that they produce some great work, have great progress, and form a really close bond of people who enjoy working together.
Remember: search for the right mix of responsibilities, training, and structure and be confident that your team can succeed.
These are some things to keep in mind when building a team of developers.
Scala is a programming language released in 2004 by Martin Odersky. It provides support for functional programming and is designed to be concise and compiled to Java bytecode so that a Scala application can be executed on a Java Virtual Machine (JVM).
Let’s check at the core features of the language.
Hello World
First, let’s see how to implement a hello world in Scala:
We defined a HelloWorld object containing a main method. This method takes an array of String as an input.
In the main, we called the method println which takes an object as an input to print something in the console.
Meanwhile, HelloWorld is also part of the io.teivah.helloworld package.
Values
We can name the result of an expression using the val keyword. In the following example, both expressions are a valid way to define a value:
val v1: String = "foo"
val v2 = "bar"
The type is optional. In the example, v1 and v2 are both typed as a String.
The Scala compiler can infer the type of a value without having to explicitly declare it. This is known as type inference.
A value in Scala is immutable. This means, the following code is not going to compile:
val i = 0
i = 1 // Compilation error
Last but not least, a value can be evaluated lazily using the lazy keyword:
lazy val context = initContext()
In this case, context will not be evaluated during its declaration but during its first invocation.
Variables
A variable is a mutable value. It is declared with the var keyword.
var counter = 0
counter = counter + 5
Just like with values, the type is optional. Yet, a variable cannot be evaluated lazily.
Furthermore, Scala is a statically typed language. The following code, for example, is invalid as we try to map an Int into a variable already defined as a String:
var color = "red"
color = 5 // Invalid
Blocks
In Scala, we can combine expressions by surrounding them with {}. Let’s consider the println() function which takes an object as an input. The two following expressions are similar:
println(7) // Prints 7
println {
val i = 5
i + 2
} // Prints 7
Note that for the second println the last expression (i + 2) is the result of the overall block.
When we call a function with a single argument just like println, we can also omit the parenthesis:
println 7
Basic Types
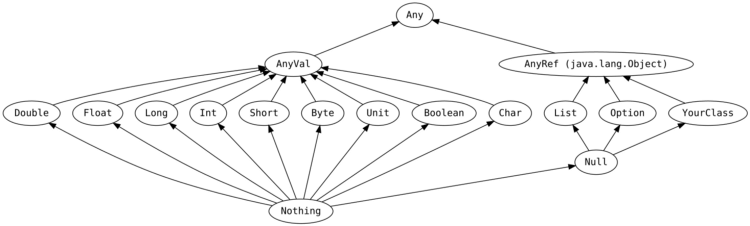
Scala is considered a pure object-oriented language because every value is an object. Hence, there is no primitive in Scala (like Java int for example).
There are 8 basic types in Scala:
Byte
Short
Int
Long
Float
Double
Char
Boolean
Scala type hierarchy
Every basic Scala type inherits from AnyVal. On the other side, AnyRef is an alias for java.lang.Object. Lastly, both AnyVal and AnyRef inherits from Any.
String Interpolation
Scala provides an elegant way to embed variable/value references directly in processed string literals. As a concrete example:
val name = "Bob"
println(s"Hello $name!") // Hello Bob!
This is made possible by the sinterpolator before the quotation mark. Otherwise, it would print Hello $name!.
There are few interpolators provided by Scala but it is a customizable mechanism. We can create for example our own interpolator to handle JSON conversions like this: println(json"{name: $name}").
Array and List
An array is also handled in Scala as an object:
val a = new Array[Int](2)
a(0) = 5
a(1) = 2
Two things to highlight here.
Firstly, the way to set elements. Instead of using a[0] like in many languages, we use the syntax a(0). This is a syntactic sugar to let us call an object just as if it was a function. Under the hood, the compiler is calling a default method called apply() taking a single input (an Int in our case) to make it possible.
Secondly, despite being declared as a val in this example, the Array object is mutable so we can change the value of indexes 0 and 1. val just enforces to not mutate the reference, not the corresponding object.
An array can also be initialized this way:
val a = Array(5, 2)
This expression is similar than above. Moreover, because it is initialized with 5 and 2, the compiler infers a as an Array[Int].
To manage multi-dimensional arrays:
val m = Array.ofDim[Int](3, 3)
m(0)(0) = 5
This code creates a two-dimensional array and initializes the very first element to 5.
There are many different data structures composing the Scala standard library. One of them is the immutableList:
val list = List(5, 2)
list(0) = 5 // Compilation error
Compared to Array, modifying an index after having initialized a List will lead to a compilation error.
Note the -> operator to associate a color key to its corresponding hexadecimal value.
Map is an immutable data structure. Adding an element means creating another Map:
val colors1 = Map("red" -> "#FF0000", "azure" -> "#F0FFFF", "peru" -> "#CD853F")
val colors2 = colors1 + ("blue" -> "#0033FF")
Meanwhile, the elements cannot be modified. In the case we need a mutable structure, we can use scala.collection.mutable.Map:
val states = scala.collection.mutable.Map("AL" -> "Alabama", "AK" -> "tobedefined")
states("AK") = "Alaska"
In this example, we mutated the AK key.
Methods/Functions: Basics
We have to make the distinction between methods and functions. A method is a function that is a member of a class, trait or object (we are going those notions).
Let’s see a basic method example:
def add(x: Int, y: Int): Int = {
x + y
}
Here we defined an add method with the def keyword. It took two Int as an input and returned an Int. Both inputs are immutable (in the sense that they are managed just like if they were declared as val).
The return keyword is optional. The method will automatically return the last expression. Moreover, it’s worth mentioning that in Scala (compared to Java), return exits the current method, not the current block.
One last thing to add, the return type is optional. The Scala compiler is also able to infer it. Yet, for the sake of code maintainability, it might be a good option to set it explicitly.
Furthermore, a method without output can be written is both ways:
In this case, mergesort2 method is used solely by mergesort1. To restrict its access, we may decide to set it private (we’ll see later on the different visibility levels).
Yet, in Scala we can also decide to nest the second method into the first one like that:
def mergesort1(array: Array[Int]): Unit = {
val helper = new Array[Int](array.length)
mergesort2(array, helper, 0, array.length - 1)
def mergesort2(array: Array[Int], helper: Array[Int], low: Int, high: Int): Unit = {
if (low < high) {
val middle = (low + high) / 2
mergesort2(array, helper, low, middle)
mergesort2(array, helper, middle + 1, high)
merge(array, helper, low, middle, high)
}
}
}
mergesort2 becomes available only in the scope of mergesort1.
Higher-Order Functions
Higher-order functions take as parameters a function or return a function as a result. As an example of a method taking a function as a parameter:
def foo(i: Int, f: Int => Int): Int = {
f(i)
}
f is a function taking an Int as an input and returning an Int. In our example, foo delegates the execution to f by passing i to it.
Function Literals
Scala is considered as a functional language in the sense that every function is a value. It means we can express a function in a function literal syntax like that:
val increment: Int => Int = (x: Int) => x + 1
println(increment(5)) // Prints 6
increment is a function with an Int => Int type (which could have been inferred by the Scala compiler). For each integer x it returns x + 1.
If we take again the previous example, we could pass increment to foo:
def foo(i: Int, f: Int => Int): Int = {
f(i)
}
def bar() = {
val increment: Int => Int = (x: Int) => x + 1
val n = foo(5, increment)
}
We can also manage so-called anonymous functions:
val n = foo(5, (x: Int) => x + 1)
The second parameter is a function without any name.
Closure
A closure in a function literal which depends on the value of one or more variable/value declared outside this function.
A simple example:
val Pi = 3.14
val foo = (n: Int) => {
n * Pi
}
Here, foo depends on Pi which is declared outside of foo.
Partial Functions
Let’s consider the following method to compute the speed from a distance and a time:
As you can see, there’s an effort made to make this function pure. Instead of depending on an external context, we make it available as a parameter of the send function.
Yet, it might be somewhat tedious to have to pass this context during every single call of send. Or maybe a function does not need to know about the context.
One solution may be to partially apply send with a predefined context and to manage an Array[Byte] => Unit function.
Another solution is to curry send and make the context parameter implicit like this:
How can we call send in this case? We can define an implicit context before to call send:
implicit val context = new Context(...)
send(bytes)
The implicit keyword means that for every function managing an implicit Context parameter, we don’t even need to pass it. It will automatically be mapped by the Scala compiler.
In our case, send manages the Context object as a potential implicit (we can also decide to pass it explicitly). So, we can simply call send with the first argument list.
Classes
A class in Scala is a similar concept than in Java:
class Point(var x: Int, var y: Int) {
def move(dx: Int, dy: Int): Unit = {
x += dx
y += dy
println(s"$x $y")
}
}
Point exposed a default (Int, Int) constructor because of the syntax line 1. Meanwhile, x and y are two members of the class.
A class can also contain a collection of methods just like move in the previous example.
We can instantiate Point with the new keyword:
val point = new Point(5, 2)
A class can be abstract meaning it cannot be instantiated.
Case Classes
Case classes are a particular kind of classes. If you are familiar with DDD (Domain Driven Design), a case class is a value object.
By default, a case class is immutable:
case class Point(x: Int, y: Int)
The value of x and y cannot be changed.
A case class must be instantiated without new:
val point = Point(5, 2)
Case classes (compared to regular classes) are compared by value (and not by reference):
We can also include conditions in the for. Let’s consider the following list of elements:
val list = List(5, 7, 3, 0, 10, 6, 1)
If we need to iterate over each element of list and consider only the even integers, we can do it this way:
for (elem <- list if elem % 2 == 0) {
}
Moreover, Scala provides so-called for comprehensions to create sequence of elements with the form for() yield element. As an example:
val sub = for (elem <- list if elem % 2 == 0) yield elem
In this example, we created a collection of even integers by iterating over each element and yielding it in case it is even. As a result, sub will be inferred as a sequence of integers (a Seq object, the parent of List).
In the same way than with if-else statement, for is also an expression. So we can also define methods like this:
def even(list: List[Integer]) = for (elem <- list if elem % 2 == 0) yield elem
Pattern Matching
Pattern matching is a mechanism to check a value against a given pattern. It is an enhanced version of the Java switch statement.
Let’s consider a simple function to translate an integer into a string:
def matchA(i: Int): String = {
i match {
case 1 => return "one"
case 2 => return "two"
case _ => return "something else"
}
}
Scala adds a bit of syntactic sugar to implement an equivalent this way:
def matchB(i: Int): String = i match {
case 1 => "one"
case 2 => "two"
case _ => "something else"
}
First, we removed the return statements. Then, matchB function becomes a pattern matcher as we removed the block statement after the function definition.
Anything else apart from some sugar? Pattern matching is a great addition to case classes. Let’s consider an example taken from Scala documentation.
We want to return a String depending on a notification type. We define an abstract class Notification and two case classes Email and SMS:
abstract class Notification
case class Email(sender: String, title: String, body: String) extends Notification
case class SMS(caller: String, message: String) extends Notification
The most elegant way to do it in Scala is to use pattern matching on the notification:
def showNotification(notification: Notification): String = {
notification match {
case Email(email, title, _) =>
s"You got an email from $email with title: $title"
case SMS(number, message) =>
s"You got an SMS from $number! Message: $message"
}
}
This mechanism allows us to cast the given notification and to automatically parse the parameters we are interested in. For example, in the case of an email, maybe we are not interested in displaying the body so we simply omit it with _ keyword.
Exceptions
Let’s consider the concrete use case where we need to print the number of bytes from a given file. To perform the I/O operation, we are going to use java.io.FileReader which may throw exceptions.
The most common way to do it if you are a Java developer would be something like this using a try/catch statement:
try {
val n = new FileReader("input.txt").read()
println(s"Success: $n")
} catch {
case e: Exception =>
e.printStackTrace
}
The second way to implement it is somewhat similar to Java Optional. As a reminder, Optional is a container brought in Java 8 for optional values.
In Scala, Try is a container for success or failures. It is an abstract class, extended by two case classes Success and Failure.
val tried: Try[Int] = Try(new FileReader("notes.md")).map(f => f.read())
tried match {
case Success(n) => println(s"Success: $n")
case Failure(e) => e.printStackTrace
}
We first wrap the creation of a new FileReader in a Try call. We use a map to convert an eventual FileReader to an Int by calling the read method. As a result, we get a Try[Int].
Then, we can use pattern matching to determine the type of tried.
Implicit Conversions
Let’s analyze the following example:
case class Foo(x: Int)
case class Bar(y: Int, z: Int)
object Consumer {
def consume(foo: Foo): Unit = {
println(foo.x)
}
}
object Test {
def test() = {
val bar = new Bar(5, 2)
Consumer.consume(bar)
}
}
We defined two case classes Foo and Bar.
Meanwhile, an object Consumer exposes a consume method taking a Foo in parameter.
In Test, we call Consumer.consume() but not with a Foo as required by the signature of the method but with a Bar. How is this possible?
In Scala, we can define implicit conversions between two classes. In the last example, we simply need to describe how to convert a Bar to a Foo:
implicit def barToFoo(bar: Bar): Foo = new Foo(bar.y + bar.z)
If this method barToFoo is imported, the Scala compiler will make sure that we can call consumer with either a Foo or a Bar.
Concurrency
To handle concurrency, Scala was initially based on the actor model. Scala was providing the scala.actors library. Yet, since Scala 2.10 this library became deprecated in favor of Akka actors.
Akka is a set of libraries for implementing concurrent and distributed applications. Nonetheless, we can also use Akka only at the scale of a single process.
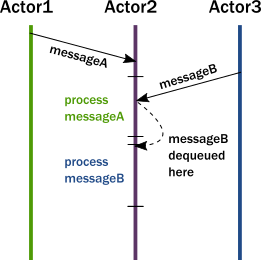
The main idea is to manage actors as a primitive for concurrent computation. An actor can send messages to other actors, receive and react to messages and spawn new actors
Example of communications within an actor system
Just like other concurrent computation models like CSP (Communicating Sequential Processes), the key is to communicate through messages instead of sharing memory between different threads.
Scala is a very elegant language. Yet, the learning curve is not that small compared to other languages like Go for example. Reading an existing Scala code as a beginner might be somewhat difficult. But once you start to master it, developing an application can be done in a very efficient way.
API Testing Guide and Beginner’s Tips (SOAP & REST)
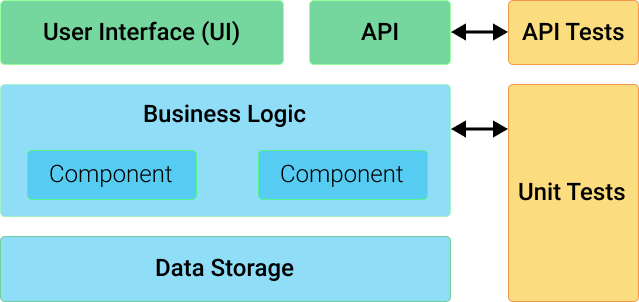
API (application programming interface) testing is a type of software testing that performs verification directly at the API level. It is a part of integration testing that determines whether the APIs meet the testers’ expectations of functionality, reliability, performance, and security. Unlike UI testing, API testing is performed at the message layer without GUI.
There are two broad classes of web service for Web API: SOAP and REST. SOAP (Simple Object Access Protocol) is a standard protocol defined by the W3C standards for sending and receiving web service requests and responses. REST (REpresentational State Transfer) is the web standards-based architecture that uses HTTP. Unlike SOAP-based Web services, there is no official standard for RESTful Web APIs.
Here are 10 basic tips that you need to know for API testing:
1. Understand API requirements
Before testing your APIs, you need to answer these questions to thoroughly understand the API’s requirements:
What is the API’s purpose?
Knowing the purpose of the API will set a firm foundation for you to well prepare your test data for input and output. This step also helps you define the verification approach. For example, for some APIs, you will verify the responses against the database; and for some others, it is better to verify the responses against other APIs.
What is the workflow of the application; and where is the API in that flow?
Generally, APIs of an application are used to manipulate its resources. They are used to read, create, update Knowing the purpose of the API will set a firm foundation for you to well prepare your test data for input and output. This step also helps you define the verification approach. For example, for some APIs, you will verify the responses against the database; and for some others, it is better to verify the responses against other APIs.
For example, the output of the “Create user” API will be the input of the “Get user” API for verification. The output of the “Get user” API can be used as the input of the “Update user” API, and so on.
2. Specify the API output status
The most common API output you need to verify in API testing is the response status code.
Verifying if the response code equals to 200 or not to decide whether an API testing is passed or failed is familiar to new API testers. This is not a wrong verification. However, it does not reflect all test scenarios of the API.
All API response status codes are separated into five classes (or categories) in a global standard. The first digit of the status code defines the class of response. The last two digits do not have any class or categorization role.
There are five values for the first digit:
1xx (Informational): The request is received and continues to be processed
2xx (Successful): The request is successfully received, understood, and accepted
3xx (Redirection): Further action needs to be taken to complete the request
4xx (Client Error): The request contains the wrong syntax or cannot be fulfilled
5xx (Server Error): The server fails to fulfill an apparently valid request
However, the actual response status code of an API is specified by the development team that built the API. So as a tester, you need to verify whether:
The code follows global standard classes
The code is specified in the requirement.
3. Focus on small functional APIs
In a testing project, there are always some APIs that are simple with only one or two inputs such as login API, get token API, health check API, etc. However, these APIs are necessary and are considered as the “gate” to enter further APIs. Focusing on these APIs before the others will ensure that the API servers, environment, and authentication work properly.
You should also avoid testing more than one API in a test case. It is painful if errors occur because you will have to debug the data flow generated by API in a sequence. Keep your testing as simple as possible. There are some cases in which you need to call a series of API to achieve an end-to-end testing flow. However, these tasks should come after all APIs have been individually tested.
4. Organize API endpoints
A testing project may have a few or even hundreds of APIs for testing. We highly suggest that you organize them into categories for better test management. It takes one extra step but will significantly help you create test scenarios with high coverage and integration. Take JIRA’s API, for example:
APIs in the same category share some common information such as resource type, path, etc. Organizing your tests with the same structures will make your test reusable and extendable with integration flow.
5. Leverage automation capability for API testing
Leverage automation capability for your API testing as much and as early as possible. Here are some significant benefits of automating API tests:
Test data and execution history can be saved along with API endpoints. This makes it easier to rerun tests later.
API tests are stable and changed with care. An API reflects a business rule of the system. Any change in the API needs an explicit requirement; so testers can always stay alert of any changes and adjust them on time.
Test execution is much faster compared to Web UI test
API testing is considered as black-box testing in which the users send input and get output for verification. Automation with a data-driven approach — i.e. applying different datasets in the same test scenario — can help increase API test coverage
Data input and output follows some specific templates or models so that you can create test scripts only once. These test scripts can also be reused throughout the entire testing project.
API tests can be performed at the early stage of the software development lifecycle. An automation approach with mocking techniques can help verify API and its integration before the actual API is developed. Hence, the level of dependency within the team is reduced.
6. Choose a suitable automation tool
A further step to leverage the automation capability of API testing is choosing the most suitable tool or a set of suitable tools from hundreds of options in the market. Here are some criteria that you should consider when choosing an API automated testing tool:
Does the tool support testing the API/Web service types that your AUT (Application Under Test) is using? It will not make sense if the selected tool supports testing RESTful services while you AUT is using SOAP services.
Does the tool support the authorization methods that your AUT services require? Here are some authorization methods that your API can use:
No Auth
Bearer Token
Basic auth
Digest Auth
NTLM Authentication
OAuth 1.0
OAuth 2.0
Hawk Authentication
AWS Signature
This is an essential task since you cannot start testing an API without authorization.
Does the tool support importing API/Web service endpoints from WSDL, Swagger, WADL, and other service specification? This is an optional feature. However, it will be time-consuming if you have hundreds of API to test.
Does the tool support data-driven methods? This is also an optional feature. However, your test coverage will increase dramatically if the tool has this function.
Last but not least, besides API testing, do you need to perform other types of testing, such as WebUI or data source? API testing is performed at the business layer between data sources and UI. It is normal that all these layers have to be tested. A tool that supports all testing types would be an ideal choice so that your test objects and test scripts can be shared across all layers.
While the response status code tells the status of the request, the response body content is what an API returns with the given input. An API response content varies from data types to sizes. The responses can be in plain text, a JSON data structure, an XML document, and more. They can be a simple few-word string (even empty), or a hundred-page JSON/XML file. Hence, it is essential to choose a suitable verification method for a given API. Katalon Studio has provided rich libraries to verify different data types using matching, regular expression, JsonPath, and XmlPath.
Generally, there are some basic methods to verify an API response body content:
Compare the whole response body content with the expected information
This method is suitable for a simple response with static contents. Dynamic information such as date time, increasing ID, etc. will cause trouble in the assertion.
Compare each attribute value of the response
For those responses in JSON or XML format, it is easy to get the value of a given key or attribute. Hence, this method is helpful when verifying dynamic content, or individual value rather than the whole content.
Compare matching with regular expression
Together with verifying individual attribute values, this method is used to verify data responses with a specific pattern to handle complex dynamic data.
Each verification method has pros and cons, and there is no one-size-fits-all option. You need to choose the solution that best fits your testing project.
8. Create positive and negative tests
API testing requires both positive and negative tests to ensure that the API is working correctly. Since API testing is considered a type of black-box testing, both types of testings are driven by input and output data. There are a few suggestions for test scenario generation:
Positive test
Verify that the API receives input and returns the expected output as specified in the requirement.
Verify that the response status code is returned as specified in the requirement, whether it returns a 2xx or error code.
Specify input with minimum required fields and with maximum fields.
Negative test
Verify that the API returns an appropriate response when the expected output does not exist.
Perform input validation test.
Verify the API’s behaviors with different levels of authorization.
9. Live testing process
Scheduling API test execution every day while the testing process is live is highly recommended. Since API test execution is fast, stable, and small enough, it is easy to add more tests into the current testing process with minimum risks. This is only possible with automated API testing tools that come with features like:
Test scheduling with built-in test commands
Integration with test management tools and defect tracking tools
Continuous Integration with various leading CI tools
Visual log reports generation
Once the testing process is completed, you can get the result of those tests every day. If failed tests occur, you can check the outputs and validate issues to have proper solutions.
10. Do not underestimate API automation testing
API testing flow is quite simple with three main steps:
Send the request with necessary input data
Get the response having output data
Verify that the response returned as expected in the requirement
The most touch parts of API testing are not either sending request nor receiving the response. They are test data management and verification. It is common that testing a few first APIs such as login, query some resources, etc. is quite simple. The testing task becomes more and more difficult to further APIs. Therefore, API testing task is easy to be underestimated. At some point in time, you would find yourself in the middle of choosing a good approach for test data and verification method. It is because the returned data have similar structures, but not the same in a testing project. It will be difficult to decide if you should verify the JSON/XML data key by key, or using object mapping to leverage the power of programming language.
Considering API automation testing a real development project is highly suggested. It should be structured to be extendable, reusable, and maintainable.